Last week I had a pleasure to participate in the International Conference on Learning Representations (ICLR), an event dedicated to the research on all aspects of deep learning. Initially, the conference was supposed to take place in Addis Ababa, Ethiopia, however, due to the novel coronavirus pandemic, it went virtual. I’m sure it was a challenge for organisers to move the event online, but I think the effect was more than satisfactory, as you can read here!
Over 1300 speakers and 5600 attendees proved that the virtual format was more accessible for the public, but at the same time, the conference remained interactive and engaging. From many interesting presentations, I decided to choose 16, which are influential and thought-provoking. Here are the best deep learning papers from the ICLR.
Best Deep Learning papers
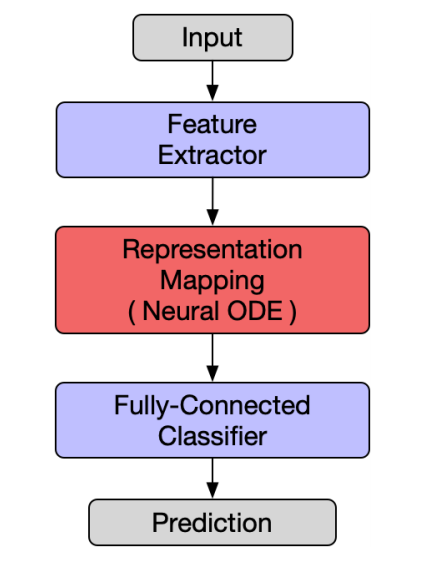
1. On Robustness of Neural Ordinary Differential Equations
In-depth study of the robustness of the Neural Ordinary Differential Equations or NeuralODE in short. Use it as a building block for more robust networks.
Gradient norm vs local gradient Lipschitz constant on a log-scale along the training trajectory for AWD-LSTM (Merity et al., 2018) on PTB dataset. The colorbar indicates the number of iterations during training.
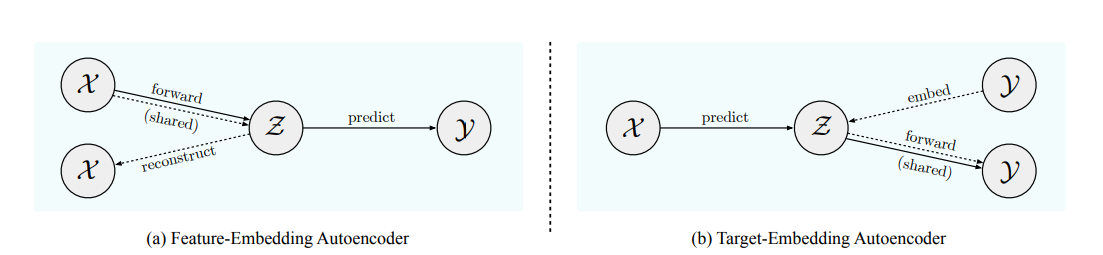
(a) Feature-embedding and (b) Target-embedding autoencoders. Solid lines correspond to the (primary) prediction task; dashed lines to the (auxiliary) reconstruction task. Shared components are involved in both.
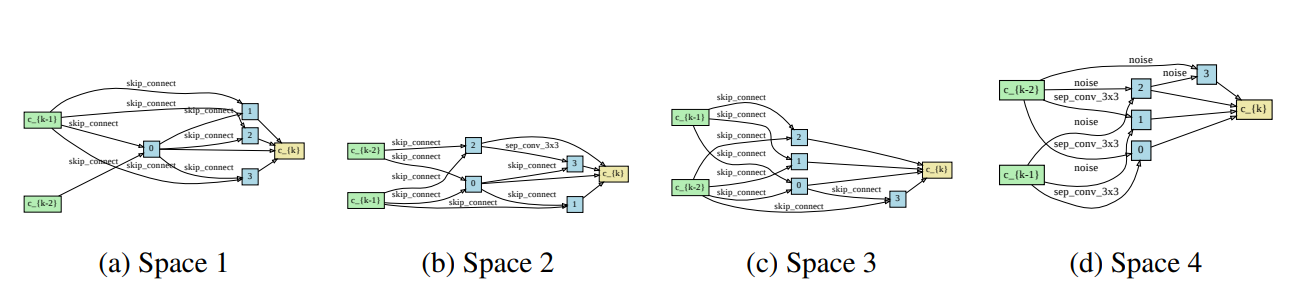
4. Understanding and Robustifying Differentiable Architecture Search
We study the failure modes of DARTS (Differentiable Architecture Search) by looking at the eigenvalues of the Hessian of validation loss w.r.t. the architecture and propose robustifications based on our analysis.
The poor cells standard DARTS finds on spaces S1-S4. For all spaces, DARTS chooses mostly parameter-less operations (skip connection) or even the harmful Noise operation. Shown are the normal cells on CIFAR-10.
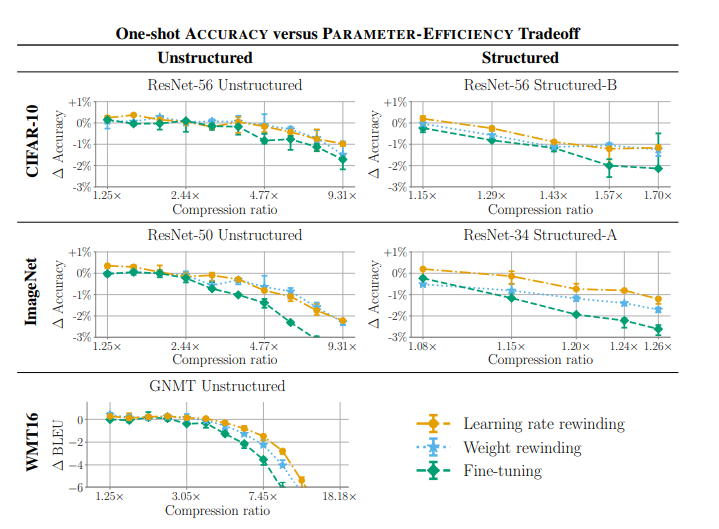
5. Comparing Rewinding and Fine-tuning in Neural Network Pruning
Instead of fine-tuning after pruning, rewind weights or learning rate schedule to their values earlier in training and retrain from there to achieve higher accuracy when pruning neural networks.
Neural nets, while capable of approximating complex functions, are rather poor in exact arithmetic operations. This task was a longstanding challenge to deep learning researchers. Here, the novel, Neural Addition Unit (NAU) and Neural Multiplication Unit (NMU) are presented, capable of performing exact addition/subtraction (NAU) and multiplying subsets of a vector (MNU). Notable first author is an independent researcher 🙂
Visualization of the NMU, where the weights (Wi,j ) controls gating between 1 (identity) or xi, each intermediate result is then multiplied explicitly to form zj.
7.The Break-Even Point on Optimization Trajectories of Deep Neural Networks
In the early phase of training of deep neural networks there exists a “break-even point” which determines properties of the entire optimization trajectory.
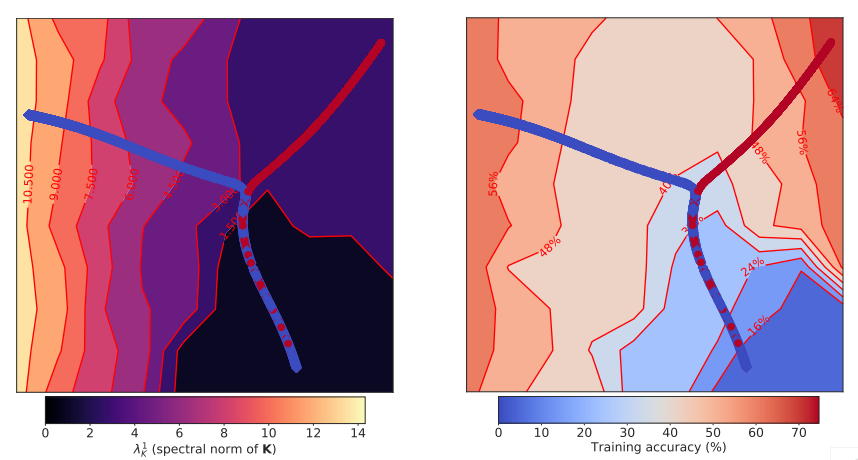
Visualization of the early part of the training trajectories on CIFAR-10 (before reaching 65% training accuracy) of a simple CNN model optimized using SGD with learning rates η = 0.01 (red) and η = 0.001 (blue). Each model on the training trajectory, shown as a point, is represented by its test predictions embedded into a two-dimensional space using UMAP. The background color indicates the spectral norm of the covariance of gradients K (λ1K, left) and the training accuracy (right). For lower η, after reaching what we call the break-even point, the trajectory is steered towards a region characterized by larger λ1K (left) for the same training accuracy (right).
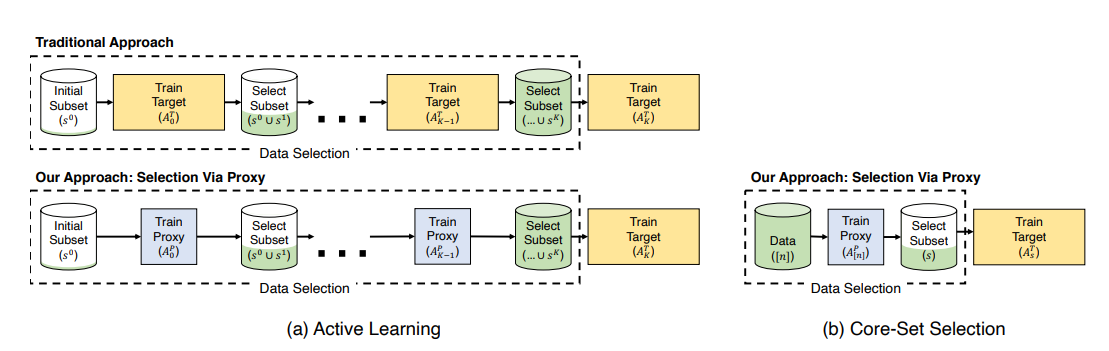
9. Selection via Proxy: Efficient Data Selection for Deep Learning
We can significantly improve the computational efficiency of data selection in deep learning by using a much smaller proxy model to perform data selection.
SVP applied to active learning (left) and core-set selection (right). In active learning, we followed the same iterative procedure of training and selecting points to label as traditional approaches but replaced the target model with a cheaper-to-compute proxy model. For core-set selection, we learned a feature representation over the data using a proxy model and used it to select points to train a larger, more accurate model. In both cases, we found the proxy and target model have high rank-order correlation, leading to similar selections and downstream results.
Illustration of our method. We approximate a binary classifier ϕ that labels images as dogs or cats by quantizing its weights. Standard method: quantizing ϕ with the standard objective function (1) promotes a classifier ϕbstandard that tries to approximate ϕ over the entire input space and can thus perform badly for in-domain inputs. Our method: quantizing ϕ with our objective function (2) promotes a classifier ϕbactivations that performs well for in-domain inputs. Images lying in the hatched area of the input space are correctly classified by ϕactivations but incorrectly by ϕstandard.
11. A Signal Propagation Perspective for Pruning Neural Networks at Initialization
We formally characterize the initialization conditions for effective pruning at initialization and analyze the signal propagation properties of the resulting pruned networks which leads to a method to enhance their trainability and pruning results.
(left) layerwise sparsity patterns c ∈ {0, 1} 100×100 obtained as a result of pruning for the sparsity level κ¯ = {10, .., 90}%. Here, black(0)/white(1) pixels refer to pruned/retained parameters; (right) connection sensitivities (CS) measured for the parameters in each layer. All networks are initialized with γ = 1.0. Unlike the linear case, the sparsity pattern for the tanh network is nonuniform over different layers. When pruning for a high sparsity level (e.g., κ¯ = 90%), this becomes critical and leads to poor learning capability as there are only a few parameters left in later layers. This is explained by the connection sensitivity plot which shows that for the nonlinear network parameters in later layers have saturating, lower connection sensitivities than those in earlier layers.
The need for semi-supervised anomaly detection: The training data (shown in (a)) consists of (mostly normal) unlabeled data (gray) as well as a few labeled normal samples (blue) and labeled anomalies (orange). Figures (b)–(f) show the decision boundaries of the various learning paradigms at testing time along with novel anomalies that occur (bottom left in each plot). Our semi-supervised AD approach takes advantage of all training data: unlabeled samples, labeled normal samples, as well as labeled anomalies. This strikes a balance between one-class learning and classification.
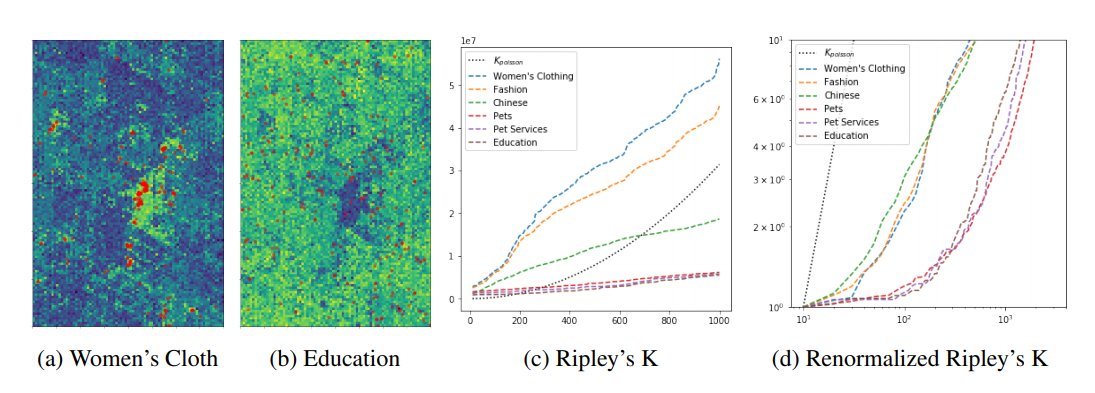
The challenge of joint modeling distributions with very different characteristics. (a)(b) The POI locations (red dots) in Las Vegas and Space2Vec predicted conditional likelihood of Women’s Clothing (with a clustered distribution) and Education (with an even distribution). The dark area in (b) indicates that the downtown area has more POIs of other types than education. (c) Ripley’s K curves of POI types for which Space2Vec has the largest and smallest improvement over wrap (Mac Aodha et al., 2019). Each curve represents the number of POIs of a certain type inside certain radios centered at every POI of that type; (d) Ripley’s K curves renormalized by POI densities and shown in log-scale. To efficiently achieve multi-scale representation Space2Vec concatenates the grid cell encoding of 64 scales (with wave lengths ranging from 50 meters to 40k meters) as the first layer of a deep model, and trains with POI data in an unsupervised fashion.
Comparison among various federated learning methods with limited number of communications on LeNet trained on MNIST; VGG-9 trained on CIFAR-10 dataset; LSTM trained on Shakespeare dataset over: (a) homogeneous data partition (b) heterogeneous data partition.
Performing convolution on this real world image using a correlative filter, such as a Gaussian kernel, adds correlations to the resulting image, which makes object recognition more difficult. The process of removing this blur is called deconvolution. What if, however, what we saw as the real world image was itself the result of some unknown correlative filter, which has made recognition more difficult? Our proposed network deconvolution operation can decorrelate underlying image features which allows neural networks to perform better.
Depth and breadth of the ICLR publications is quite inspiring. Here, I just presented the tip of an iceberg focusing on the “deep learning” topic. However, this analysis, suggests that there were few popular areas, specifically:
In order to create a more complete overview of the top papers at ICLR, we are building a series of posts, each focused on one topic mentioned above. You may want to check them out for a more complete overview.
Happy reading!
Was the article useful?
Thank you for your feedback!
More about
The Best Deep Learning Papers from the ICLR 2020 Conference
Check out our
product resources
and
related articles below: