Last week I had a pleasure to participate in the International Conference on Learning Representations (ICLR), an event dedicated to the research on all aspects of representation learning, commonly known as deep learning. The conference went virtual due to the coronavirus pandemic, and thanks to the huge effort of its organizers, the event attracted an even bigger audience than last year. Their goal was for the conference to be inclusive and interactive, and from my point of view, as an attendee, it was definitely the case!
Inspired by the presentations from over 1300 speakers, I decided to create a series of blog posts summarizing the best papers in four main areas. You can catch up with the first post about the best deep learning papers here, and today it’s time for 15 best reinforcement learning papers from the ICLR.
The Best Reinforcement Learning Papers
1. Never Give Up: Learning Directed Exploration Strategies
We propose a reinforcement learning agent to solve hard exploration games by learning a range of directed exploratory policies.
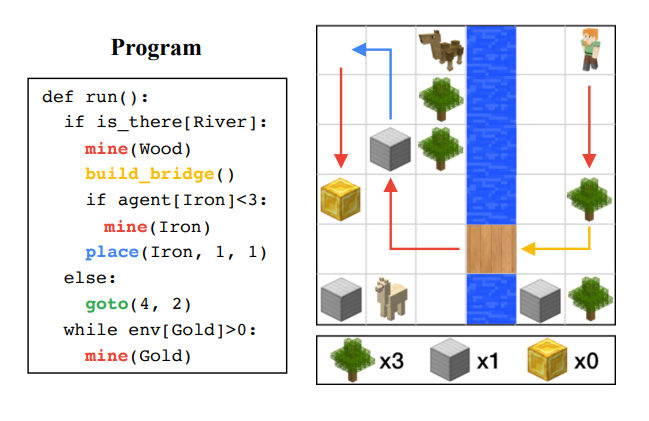
An illustration of the proposed problem. We are interested in learning to fulfill tasks specified by written programs. A program consists of control flows (e.g. if, while), branching conditions (e.g. is_there[River]), and subtasks (e.g. mine(Wood)).
Main loop of SimPLe. 1) the agent starts interacting with the real environment following the latest policy (initialized to random). 2) the collected observations will be used to train (update) the current world model. 3) the agent updates the policy by acting inside the world model. The new policy will be evaluated to measure the performance of the agent as well as collecting more data (back to 1). Note that world model training is self-supervised for the observed states and supervised for the reward.
Qualitative Results: Visualization of different target functions (Sec. 2.3). T+ generates high reward and T− low reward states; T± generates states in which one action is highly beneficial and another is bad.
We identify and formalize the memorization problem in meta-learning and solve this problem with novel meta-regularization method, which greatly expand the domain that meta-learning can be applicable to and effective on.
Left: An example of non-mutually-exclusive pose prediction tasks, which may lead to the memorization problem. The training tasks are non-mutually-exclusive because the test data label (right) can be inferred accurately without using task training data (left) in the training tasks, by memorizing the canonical orientation of the meta-training objects. For a new object and canonical orientation (bottom), the task cannot be solved without using task training data (bottom left) to infer the canonical orientation. Right: Graphical model for meta-learning. Observed variables are shaded. Without either one of the dashed arrows, Yˆ ∗ is conditionally independent of D given θ and X∗, which we refer to as complete memorization (Definition 1).
An example with H = 3. For this example, we have r(s5) = 1 and r(s) = 0 for all other states s. The unique state s5 which satisfies r(s) = 1 is marked as dash in the figure. The induced Q∗ function is marked on the edges.
Illustration of our proposed instrumentation-free system requiring minimal human engineering. Human intervention is only required in the goal collection phase (1). The robot is left to train unattended (2) during the learning phase and can be evaluated from arbitrary initial states at the end of training (3). We show sample goal and intermediate images from the training process of a real hardware system
8. Improving Generalization in Meta Reinforcement Learning using Learned Objectives
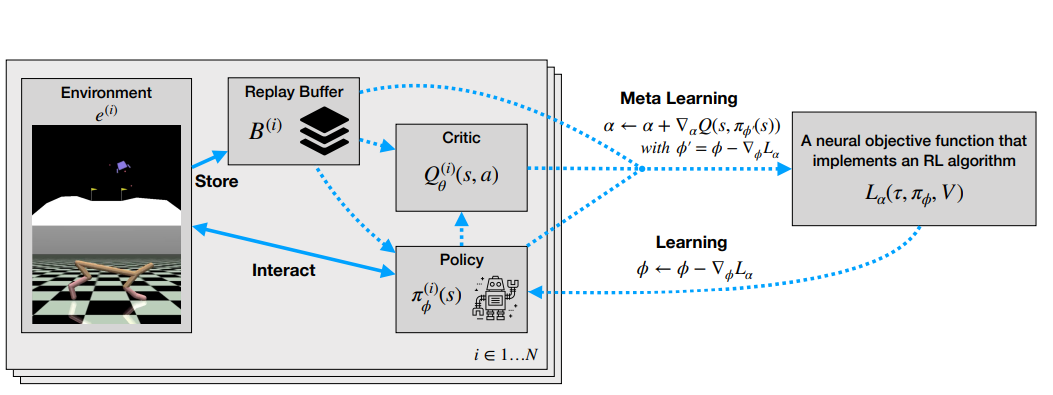
We introduce MetaGenRL, a novel meta reinforcement learning algorithm. Unlike prior work, MetaGenRL can generalize to new environments that are entirely different from those used for meta-training.
A schematic of MetaGenRL. On the left a population of agents (i ∈ 1, . . . , N), where each member consist of a critic Q (i)θ and a policy π (i)φ that interact with a particular environment e(i) and store collected data in a corresponding replay buffer B(i) . On the right a meta-learned neural objective function Lα that is shared across the population. Learning (dotted arrows) proceeds as follows: Each policy is updated by differentiating Lα, while the critic is updated using the usual TD-error (not shown). Lα is meta-learned by computing second-order gradients that can be obtained by differentiating through the critic.
9. Making Sense of Reinforcement Learning and Probabilistic Inference
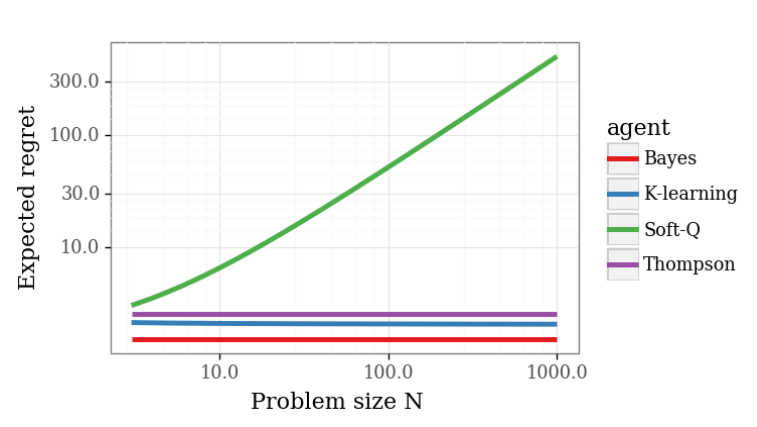
Popular algorithms that cast “RL as Inference” ignore the role of uncertainty and exploration. We highlight the importance of these issues and present a coherent framework for RL and inference that handles them gracefully.
10. SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
SEED RL, a scalable and efficient deep reinforcement learning agent with accelerated central inference. State of the art results, reduces cost and can process millions of frames per second.
Forward propagations of NeurComm enabled MARL, illustrated in a queueing system. (a) Single-step forward propagations inside agent i. Different colored boxes and arrows show different outputs and functions, respectively. Solid and dashed arrows indicate actor and critic propagations, respectively. (b) Multi-step forward propagations for updating the belief of agent i.
12. A Generalized Training Approach for Multiagent Learning
This paper studies and extends Policy-Spaced Response Oracles (PSRO). It’s a population-based learning method that uses game theory principles. Authors extend the method so that it’s applicable to multi-player games, while providing convergence guarantees in multiple settings.
13. Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Sometimes an implementation detail may play a role in your research. Here, two policy search algorithms were evaluated: Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO). “Code-level optimizations”, should be negligible form the learning dynamics. Surprisingly, it turns out that h optimizations turn out to have a major impact on agent behavior.
An ablation study on the first four optimizations described in Section 3 (value clipping, reward scaling, network initialization, and learning rate annealing). For each of the 24 possible configurations of optimizations, we train a Humanoid-v2 (top) and Walker2d-v2 (bottom) agent using PPO with five random seeds and a grid of learning rates, and choose the learning rate which gives the best average reward (averaged over the random seeds). We then consider all rewards from the “best learning rate” runs (a total of 5 × 24 agents), and plot histograms in which agents are partitioned based on whether each optimization is on or off. Our results show that reward normalization, Adam annealing, and network initialization each significantly impact the rewards landscape with respect to hyperparameters, and were necessary for attaining the highest PPO reward within the tested hyperparameter grid.
This is in-depth, empirical study of the behavior of the deep policy gradient algorithms. Authors analyse SOTA methods based on gradient estimation, value prediction, and optimization landscapes.
Empirical variance of the estimated gradient (c.f. (1)) as a function of the number of state-action pairs used in estimation in the MuJoCo Humanoid task. We measure the average pairwise cosine similarity between ten repeated gradient measurements taken from the same policy, with the 95% confidence intervals (shaded). For each algorithm, we perform multiple trials with the same hyperparameter configurations but different random seeds, shown as repeated lines in the figure. The vertical line (at x = 2K) indicates the sample regime used for gradient estimation in standard implementations of policy gradient methods. In general, it seems that obtaining tightly concentrated gradient estimates would require significantly more samples than are used in practice, particularly after the first few timesteps. For other tasks – such as Walker2d-v2 and Hopper-v2 – the plots have similar trends, except that gradient variance is slightly lower. Confidence intervals calculated with 500 sample bootstrapping.
How well does meta-RL work? Average returns on validation tasks compared for two prototypical meta-RL algorithms, MAML (Finn et al., 2017) and PEARL (Rakelly et al., 2019), with those of a vanilla Q-learning algorithm named TD3 (Fujimoto et al., 2018b) that was modied to incorporate a context variable that is a representation of the trajectory from a task (TD3-context). Even without any meta-training and adaptation on a new task, TD3-context is competitive with these sophisticated algorithms.
Depth and breadth of the ICLR publications is quite inspiring. Here, I just presented the tip of an iceberg focusing on the “reinforcement learning” topic. However, as you can read in this analysis, there were four main areas discussed at the conference:
In order to create a more complete overview of the top papers at ICLR, we are building a series of posts, each focused on one topic mentioned above. You may want to check them out for a more complete overview.
Feel free to share with us other interesting papers on reinforcement learning and we will gladly add them to the list.
Enjoy reading!
Was the article useful?
Thank you for your feedback!
Thank you for your feedback!
Thank you for your feedback.
Error: Contact form not found.
Thanks! Your suggestions have been forwarded to our editors!
More about
The Best Reinforcement Learning Papers from the ICLR 2020 Conference
Check out our
product resources
and
related articles below: