
As every practitioner in the Data Science space knows, Data is the primary fuel for Machine Learning. A trustworthy data sourcing and high-quality data collection and processing can empower a vast range of potential ML use cases. But having a well-governed Data Warehouse requires a thorough devotion from every team in the organization to look after and curate every data point that they produce, ingest, analyze or exploit. Data quality responsibility spreads across everyone. It is not only dependent on the Data Engineering team.

The most common data architecture nowadays in organizations is Lambda Architecture. It is characterized by having independent batch and streaming pipelines ingesting data into the Data Lake, which consists of a landing or raw stage where ELT processes dump raw data objects, such as events or database record dumps.
This raw data is later ingested and wrangled into more organized Data Lake tables (Parquet files, for example), and then it is enriched to be ingested into the Data Warehouse. The data that gets into the DW is logically organised information for different business domains called Data Marts. These data marts are easily queried by Data Analysts and explored by Business Stakeholders. Each data mart could be related to different business units or product domains (Marketing, Subscriptions, Registrations, Product, Users …).

There are also other reference architecture patterns such as the Kappa or Delta, the latter getting a lot of traction with commercial products such as Databricks and Delta Lake.
These foundational data architectural patterns have paved the way for analytical workloads. OLAP databases and processing engines for Big Data, such as Spark and Dask, among others, have enabled the decoupling of the storage and computing hardware, allowing Data practitioners to interact with massive amounts of data for doing Data Analytics and Data Science.
With the rise of MLOps, DataOps, and the importance of Software Engineering in production Machine Learning, different startups and products have emerged to solve the issue of serving features such as Tecton, HopsWorks, Feast, SageMaker Feature Store, Databricks Feature Store, Vertex AI Feature Store… (check out Featurestore.org to see all the players in this field).
Furthermore, every company doing production data science at a considerable scale, if not using one of the tools named before, has built their in-house feature store (e.g., Uber was of the first to publish their own approach for building an ML platform, followed by Airbnb).
In this article, we will explain some of the concepts and issues that feature stores solve as if it was an in-house platform. This is because we think it is easier to understand the underlying components and the conceptual and technical relationships among them. We won’t dive deep into commercial products.
We will also discuss the tension between build and buy, which is a hot topic among practitioners in the industry today and what’s the best way to approach this decision.
Bookmark for later
What is a feature store?
Last year, some blogs and influential people in the ML world named 2021 as the year of the feature store. We will argue in the next sections the reason behind this. But then, what is a feature store?
A short definition given by Featurestore.org is:
“A data management layer for machine learning that allows to share & discover features and create more effective machine learning pipelines.”
That’s pretty accurate. To briefly expand on some details, feature stores are composed of a set of technological, architectural, conceptual, and semantic components that enable ML practitioners to create, ingest, discover and fetch features for doing offline experiments and developing online production services.
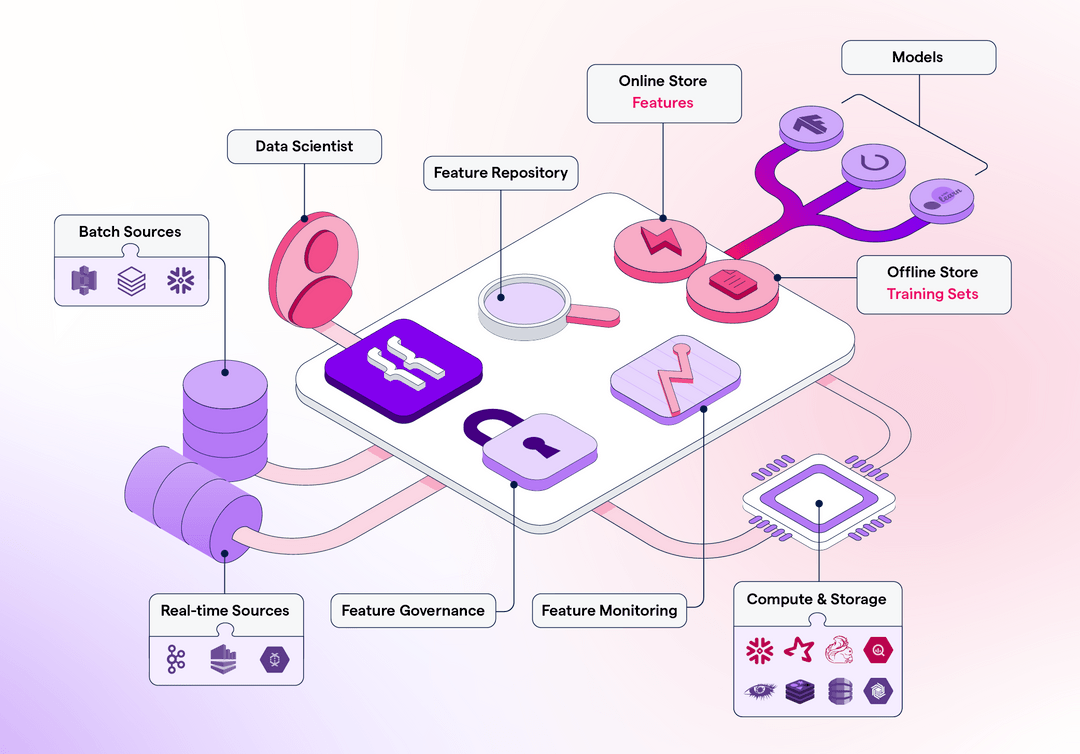
Components of a feature store

We should start defining what is a feature vector as it’s the core entity that feature stores deal with.
- Feature Vector: This is a data element that contains an entity identifier and a set of properties or characteristics that describe that element at a certain point in time. For example, the entity identifier can be a user ID and the properties could contain the following values: (time_since_registration, n_purchases, ltv_value, is_free_trial, average_purchases_per_month, accumulated_purchases, last_purchase_ts etc)
Let’s explain now which are the different storage components that host these feature vectors:
- Offline Store: This is meant to be an analytical database that can ingest, store and serve feature vectors for offline workloads such as data science experiments or batch production jobs. In general, each row contains a feature vector uniquely identified by the entity ID and a given timestamp. This component is usually materialized as S3, Redshift, BigQuery, Hive, etc.
- Online Store: Also referred to as hot data, this storage layer is meant to serve features for low latency prediction services. This database is now used to fetch features at millisecond speed. Redis, DynamoDB, or Cassandra are the common candidates to play this role. Key-Value databases are the best option as complex queries and join are not often needed at runtime.
- Feature Catalog or Registry: Ideally, this is presented as a nice UI that enables features and training datasets discoverability.
- Feature Store SDK: This is a Python library that abstracts access patterns for online and offline stores.
- Metadata Management: This component is used to track access from different users or pipelines, ingestion processes, schema changes, and this type of information.
- Offline and Online Serving API: This is a proxy service that sits in between the SDK and the online and feature hardware to facilitate feature access.
In the following chronological diagram, we can see a summary of the key milestones around feature store since 2017, when Uber released its famous Michelangelo. A couple of years later, after several commercial and OS products launched, we’ve already seen a wide acceptance of the concept of feature store by industry practitioners. Several organizations such as featurestore.org and mlops.community have emerged in response to this.
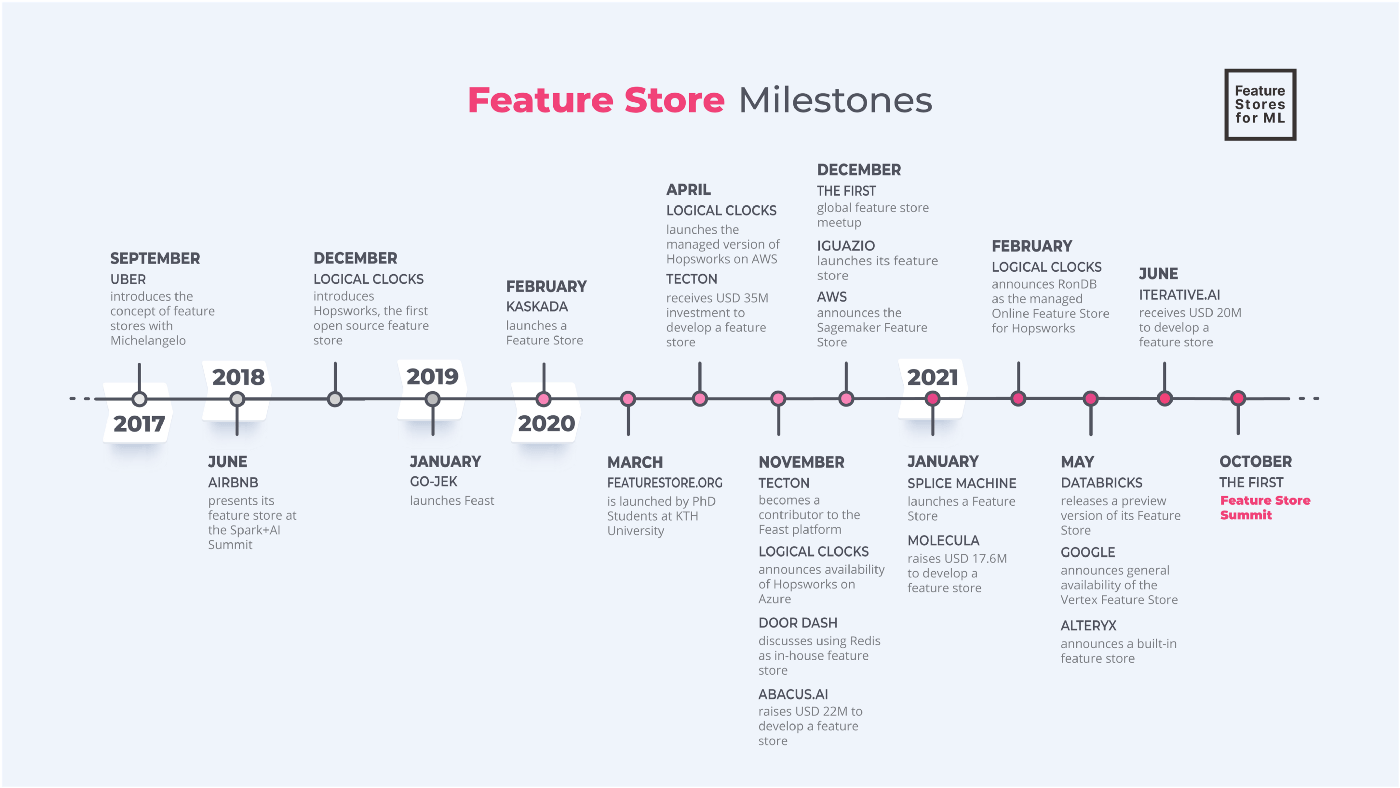
In relationship with MLOps, feature stores are themselves affected and affect other components of the stack such as the Data Warehouse, Data Lake, the data job schedulers, production databases, etc. as well. We will discuss this relationship in detail later, i.e., where does a feature store sit in the big picture of the MLOps framework?
Now, let’s discuss some of the major issues that ML Engineers face around production feature engineering.
Hassles around feature store
Standardization of features ingestion and fetching
Before the existence of a proper feature store, each data science team stored and fetched features using very different tools. These kinds of jobs have been treated traditionally as part of Data Engineering pipelines. Therefore, the libraries, SDKs, and tooling around these jobs are the ones used by data engineers. They can be quite diverse depending on the team’s expertise, maturity level, and background.
For example, you could see the following situation in the same organization:
- Team A: The team is not very knowledgeable in data engineering. They use bare pandas and SQL scripts with psycopg connectors to store offline features in Redshift and boto to store online features in DynamoDb.
- Team B: The team is mature and autonomous. They built a library for abstracting connections to several data sources using sqlalchemy or PySpark for big data jobs. They also have custom wrappers for sending data to DynamoDb and other hot databases.
This is very typical in large organizations where the ML teams are not fully centralized, or ML cross-teams don’t exist.
Teams operating with the same databases over different projects tend to build wrappers around them so that they can abstract the connectors and encapsulate common utilities or domain definitions. This problem is already solved by Team B. But Team A is not so skilled, and they might develop another in-house library to work with their features in a simpler way.
This causes friction among teams because they want to impose their tool across the organization. It also lowers productivity levels across teams because each one is reinventing the wheel in its own manner, coupling developers to projects.
By introducing a Feature Store SDK, both teams could leverage the same interface for interacting with Redshift and DynamoDb, and other data sources too. The learning curve will be steeper for Team A, but they will maintain the same standard for operating them. So overall productivity will be increased. This allows for better feature governance. SDKs usually hide other API calls to log user requests, and version datasets, allowing for rollbacks, etc.
Most commercial feature stores provide specific SDKs for interacting with their central service. For example, in the next snippet, you could see how to build a dataset fetching features from Feast.

This is not only valuable for standardizing feature store operations but also for abstracting the online and offline stores’ hardware. Data Scientists don’t need to know if the offline store is a BigQuery or Redshift database. This is a great benefit as you could use a different source depending on the use case, data, etc.
Time-travel data
If we want to predict whether a user will buy a product or not, we have to build a dataset with features until that specific moment. We need to be very careful regarding not introducing future data as this can lead to Data Leakage. But how?
If we introduce future data into the training dataset with respect to each observation, the Machine Learning model will learn unreliable patterns. When putting the model into real-time production, it won’t have access to the same features (unless you can travel to the future), and its prediction capabilities will deteriorate.
Coming back to the example of the product purchase prediction, let’s say you want to use specific characteristics about the users, for example, the number of items saved in the cart. The training dataset will contain events about users who saw and bought the product (positive label) and users who saw but didn’t buy the product (negative label). If you want to use the number of items in the cart as a feature, you would need to query specifically for the events that log every item added to the cart within the same session and just before the purchase/seen event.

Hence, when building such a dataset, we need to query specifically for the features that were available at that point in time with respect to each event. It’s necessary to have a representation of the world in which that event occurred.
How to have an accurate picture?
- Log and wait: You just have to log specific features, such as n_cumulative_items_in_the_cart, and then we’ll know how many items the user had at that point in time. The main drawback is that this feature collection strategy needs time to gather enough data points for the use case. But on the other hand, it is easy to implement.
- Backfilling: This technique basically aims to reconstruct the desired features at a given point in time. For example, by looking at logged events, we could add all the items added to the cart before each purchase. However, this might become very complex as we have to select the time window cutoff for every feature. These queries are commonly known as point-in-time joins.
- Snapshotting: It is based on dumping the state of a production database periodically. This allows having features at any given point in time, with the drawback that the data changes between consecutive snapshots wouldn’t be available.
Features availability for production
Experienced ML engineers tend to think about what features are available at run time (online) when a new ML use case is proposed. Engineering the systems behind enabling features is the most time-consuming piece of the ML architecture in most cases.
Having an up-to-date feature vector ready to be fed to ML models to make a prediction is not an easy task. Lots of components are involved, and special care is required to glue them all together.
Features in production can come from very different sources. They can be fed to the algorithm within the request body parameters, they can be fetched from a specific API, retrieved from a SQL or NoSQL database, from a Kafka topic event, from a Key-Value store, or they can be computed and derived on-the-fly from other data. Each of them implies different levels of complexity and resource capacity.
What are these sources?
- Request Body Parameters
This is the simplest way of receiving features for prediction. The responsibility of obtaining these features and passing them to the ML model is delegated to the client or consumer of the inference API Web Service. Nevertheless, this is not the most common way of feeding features. In fact, request parameters tend to contain unique identifiers that are needed to fetch feature vectors from other sources. These are usually user IDs, content IDs, timestamps, search queries, etc.
- Databases
Depending on the evolvability requirements of the features schemas and latency, features can be live in different databases such as Cassandra, DynamoDb, Redis, PostgreSQL, or any other fast NoSQL or SQL database. Fetching these features from an online service is quite straightforward. You can use any Python library like boto for DynamoDb, pyredis for Redis, psycopg2 for PostgreSQL, mysql-connector-python for MySQL, cassandra-driver for Cassandra, and so on.

Each row in the database will have a primary key or index that will be available at runtime for each prediction request. The rest of the columns or values will be the features that you can use.
To fill up these tables we can use different approaches depending on the nature of the features to compute:
- Batch jobs: These are compute-intensive, heavy, and “slow”, that’s why they only serve a certain type of features defined by how fresh they need to be. When building different use cases, you realise that not every model needs real-time features. If you’re using the average rating of a product, you don’t need to compute the average every second. Most of the features like this just need a daily computation. If the feature requires higher update frequency than 1 day, you should start thinking about a batch job.

Talking about common tech stacks, old friends come into play for serving different purposes and scales:
- Airflow + DBT or Python is a great first start to schedule and run these jobs.
- If more scale is needed in terms of distributed memory, we can start thinking about Kubernetes Clusters to execute Spark or Dask jobs.
Some alternatives for orchestration tools are Prefect, Dagster, Luigi, or Flyte. Have a look at a comparison of Data Science orchestration and workflow tools.
- Streaming Ingestion: Features that need streaming or (near) real-time computations are time-sensitive. Common use cases that need real-time features are fraud detection, real-time product recommendation, predictive maintenance, dynamic pricing, voice assistants, chatbots, and more. For such use cases, we would need a very fast data transformation service.

There are two important dimensions to take into account here – frequency and complexity. For example, computing the “standard deviation of the current price versus the average monthly price” on an individual transaction is both a real-time and complex aggregation.

Apart from having a streaming tool in place for collecting events (Kafka), we would also need a high-speed and scalable (to handle any volume of events per second) function-as-a-service (such as AWS Lambda) to read and process those events. More importantly, the transformation service needs to support aggregations, grouping, joins, custom functions, filters, sliding windows to calculate data over a given time period every X minutes or hours, etc.
Where does the feature store sit in the MLOps architecture?
The feature store is an inherent part of ML Platforms. As said previously, it has been a part of it since the first ML models were put in production, but it wasn’t until a few years ago when the concept acquired its own identity within the MLOps world.
Features data sources can get tracked with Experiment Tracking tools such as Neptune, MLFlow, or SageMaker Experiments. That is, let’s say you’re training a fraud detection model and you’ve used some shared Features that another team has built. If you logged those features metadata as parameters, then they will be versioned along with your experiment results and code when tracking the experiments.

Besides, they become a critical piece when the model is in the production stage. There are several components that need to be synchronised and closely monitored when being live. If one fails, predictions could degrade pretty quickly. These components are the features computation & ingestion pipelines and features consumption from the production services. The computation pipelines need to run at a specific frequency so that features’ freshness doesn’t affect the online predictions. E.g.: if a recommendation system needs to know the film you viewed yesterday, the feature pipeline should run before you go into the media streaming service again!
How to implement a feature store?
In this section, we will discuss different architectures that can be implemented for different stages and sizes of Data Science teams. In this very nice article, you can see how the author uses the Hierarchy of Needs to very explicitly show which are the main pillars you need to solve. He places the Access need, which encompasses transparency and lineage, as more foundational than Serving. I don’t completely agree as the features availability in production unlocks higher business value.
The suggestions presented below will be based on AWS services (although they are easily interchangeable with other public cloud services).
The simplest solution
This architecture is based on managed services, which require less maintenance overhead and are better suited for small teams that can operate quickly.
My initial setup would be Redshift as an offline store, DynamoDB as an online key value store, Airflow to manage batch feature computation jobs. Also, Pandas as data processing engine for both options. In this architecture, all feature computation pipelines are scheduled in Airflow and would need to ingest data by using Python scripts that fetch data from Redshift or S3, transforms it, and put it into DynamoDB for online services and then in Redshift again for the offline feature storage.

Medium-size feature store
If you’re already dealing with big data, near real-time needs for features, and reusability necessities across data science teams, then you are probably looking for more standardization across feature pipelines and some degree of reusability.
In this situation, I would recommend starting using third-party feature store vendors when the data science team size is relatively big (let’s say, more than 8-10 data scientists). First, I would explore Feast as it’s the most used open-source solution out there, and it can work on top of existing infrastructure. You could use Redshift as an offline feature store and DynamoDB or Redis as an online feature store. The latter is faster for online prediction services with lower latency requirements. Feast will help to catalogue and serve features through their SDK and web UI (still experimental, though). If you want a fully managed commercial tool, I implore you to try out Tecton.
Feature computation pipelines can now be developed using plain Python or Spark if there are big data requirements, leveraging Feast SDK for managing data ingestion.

It’s also pretty likely that at this size, there are some use cases with real-time features freshness necessities. In this case, we need a streaming service that ingests features directly into the online feature store. We could use Kinesis services and AWS Lambda to write feature vectors into Redis or DynamoDB directly. If window aggregations are needed, then Kinesis Data Analytics, KafkaSQL, or Spark Streaming might be reasonable options.
Enterprise-level feature store
At this stage, we assume the company has plenty of data scientists creating different types of models for different business or technical domains. One key principle when setting architectures for development teams of this size is to provide a reliable, scalable, secure, and standardized data platform. Therefore, SLAs, GDPR, Audit, and Access Control Lists are mandatory requirements to put in place. These are always important points to cover at every organization size, but in this case, they play a critical role.
Most of the big players in the tech space have built their own feature stores according to their own needs, security principles, existing infrastructure, and managed availability themselves to avoid having a single point of failure if the service is fully managed.
But if this is not the case and you’re running a public cloud-heavy workload, using AWS SageMaker Feature Store or GCP Vertex AI Feature Store can be good options to start with. Their API is very similar to their open source counterparts, and if you’re already using SageMaker or Vertex, setting up their feature store services should be straightforward.

Databricks also offers an embedded Feature Store service, which is also a good option and would be perfectly compatible with a tool like MLFlow.

The buy versus build question
The MLOps landscape has been dominated and shaped by big players such as Facebook, Netflix, Uber, Spotify, etc., throughout these years with their very influential staff engineers and blogs. But ML teams should be able to recognize the contexts in which they operate in their own organizations, teams, and business domains. A 200,000 users app doesn’t need the scale, standardization, and rigidity of a 20-million one. That’s why MLOps at reasonable scale is a hot topic that is sticking around senior practitioners not working at FAANG-like companies.
Read also
Setting up MLOps at a Reasonable Scale With Jacopo Tagliabue

Who should build a feature store?
As mentioned at the start of this article, there’s a constant tussle between building a feature store-like platform in-house or buying a commercial or open source product like Feast, Hopsworks, or Tecton. This tension exists primarily because these products can be opinionated to some degree in their architecture and their SDKs. Thus, most of these tools need to have a central service to handle feature serving on top of online stores, which becomes a single point of failure for production ML services.
In addition, some other products are full SaaS, becoming an uncertain critical piece for some teams. Thus, ML Engineers are skeptical to bet and adhere too early to one of these tools in their MLOps journey.
It is very common that ML and Data Engineering teams share the same technology stack in small or medium size companies or startups. For that reason, migrating to a feature store might cause a big headache and expose some hidden costs. In terms of planning, legacy maintenance, operationality, duplicities, etc., it becomes another piece of infrastructure with specific SDKs which are different from the traditional Data Engineering ones.
Who should buy a feature store?
To extract the most value from a commercial feature store, your use cases and data science teams’ setup need to be aligned with the core benefits that they provide. Products that are heavily reliant on real-time complex ML use cases such as recommendation systems, dynamic pricing, or fraud detection are the ones that can leverage these tools the most.
A big team of Data Scientists is also a good reason to have a feature store, as it will increase productivity and features reusability. Apart from that, they usually provide a nice UI to discover and explore features. Nonetheless, commercial Feature Store SDKs and APIs provide a set of standards for a more homogeneous way of ingesting and retrieving features. And as a by-product, the data is governed, and reliable metadata is always logged.
In the very wide variety of ML teams domains, the situation described above is not always met, and setting up these new commercial stacks is sometimes just a personal development desire of the engineers to stay up-to-date with respect to new technology.
That’s why there are teams still who haven’t migrated to a full-packaged feature store and, instead, still rely on the existing data engineering stack for running their production feature engineering layer. This is totally valid, in my opinion.
All in all, feature stores just add a convenient shell on top of the existing data engineering stack to provide unified access APIs, a nice UI to discover and govern feature sets, guarantee consistency between online and feature stores, etc. But all these features are not critical for every ML team’s use case.
Conclusion
I hope that this article has provided a broad view of what feature store are. But more importantly, the reason they’re necessary and the key components that need to be addressed when building one.
Feature stores are necessary for levelling up the production services in the data science industry. But you need engineers behind them. The ML Engineer role is critical for dealing with feature pipelines as they are just a specific type of data transformation and ingestion process. Hybrid roles like that allow Data Scientists to focus more on the experimentation side and also guarantee high-quality deliverables.
In addition, I paid special attention to explaining the build versus buy dilemma. From my personal experience, this question arises sooner or later within any mature ML team. I have tried to describe the situations in which they are key for achieving velocity and standardisation, but also left some thoughts on why context awareness is necessary regarding implementing this new technology. Experienced and senior roles should take into consideration the stage of the MLOps journey in which they operate.
The feature store (commercial and open source) world is still young, and there is not yet a uniform and accepted way of dealing with all the different use cases and needs. So try all the approaches before settling down with one.
References
- Feature Stores – A Hierarchy of Needs
- Feature Stores Explained: The Three Common Architectures | FeatureForm
- Feature Store – Modern Data Stack
- Back to the Future: Solving the time-travel problem in machine learning | Tecton
- An overview of dataset time travel • Max Halford
- “Turning the database inside out with Apache Samza” by Martin Kleppmann
- Temporal database – Wikiwand
- Building Real-Time ML Pipelines with a Feature Store | by Adi Hirschtein
- Running Feast in production
- The Killer Feature Store: Orchestrating Spark ML Pipelines and MLflow for Production
- Do you need a feature store?
