
In machine learning and AI development, the aspects of data labeling are essential. You need a structured set of training data that an ML system can learn from.
It takes a lot of effort to create accurately labeled datasets. Data labeling tools come very much in handy because they can automate the labeling process, which is particularly tedious.
On top of that, these tools enable easier collaboration and quality control for the overall dataset creation process. You get an accurate training dataset from any type of data, and you can connect it with your ML pipelines.
So, in this article, we’re going to explore the 10 best data labeling tools.
Amazon SageMaker Ground Truth

Amazon SageMaker Ground Truth is a state-of-the-art automatic data labeling service from Amazon. This tool offers a fully managed data labeling service that simplifies the implementation of datasets for machine learning.
With Ground Truth, you can build highly accurate training datasets with ease. There’s a custom built-in workflow through which you can label your data within minutes, with high accuracy. The tool provides support for different types of labeling output such as text, images, video, and 3D cloud points.
The labeling features such as automatic 3D cuboid snapping, removal of distortion in 2D images, and auto-segment tools make the labeling process easy and optimized. They greatly reduce the time needed to label the dataset.
Throughout the process, you will:
- Enter raw data into Amazon S3.
- Create automatic labeling tasks using built-in custom workflow.
- Make accurate selection from a group of labelers.
- Label with assistive labeling feature
- Generate accurate training datasets.
The major benefits of Ground Truth are:
- It’s automatic and easy to use.
- It improves data labeling accuracy.
- It greatly reduces the time with its labeling features.
You can watch an overview walkthrough video here.
Label Studio

Label Studio is a web application platform with a data labeling service, and exploration for multiple data types. It’s built using a combination of React and MST as the frontend, and Python as the backend.
It offers data labeling for every possible data type: text, images, video, audio, time series, multi-domain data types, etc. Resulting datasets have high accuracy, and can easily be used in ML applications. The tool is accessible from any browser. It’s distributed as precompiled js/CSS scripts that run on every browser. There’s also a feature to embed Label Studio UI into your applications.
In order to perform accurate labeling and create optimized datasets, this tool:
- Takes in data from various APIs, files, Web UI, audio URL, HTML markup, etc.
- Pipelines the data to a labeling configuration that has three major sub-processes:
- Task that takes in data of different types from various sources.
- The completion process provides the result of labeling in JSON format.
- The prediction process provides optional labeling results in JSON format.
- The machine learning backend adds the popular and efficient ML frameworks to create accurate datasets automatically.
The benefits are:
- Supports labeling of data of different types.
- Easy to use and automatic.
- Accessible in any web browser and also can be embedded in personal applications.
- Generates high-level dataset with precise labeling workflow.
Sloth

Sloth is an open-source data labeling tool mainly built for labeling image and video data for computer vision research. It offers dynamic tools for data labeling in computer vision.
This tool can be considered as a framework, or a set of standard components to quickly configure a label tool specifically tailored to your needs. Sloth lets you write your own custom configurations, or use default configurations to label the data.
It lets you write and factorize your own visualisation items. You can handle the complete process from installation to labeling, and creating properly documented visualization datasets. Sloth is pretty easy to use.
The benefits are:
- It simplifies image and video data labeling.
- Specialized tool to create accurate datasets for computer vision.
- You can customize default configurations to create your own labeling workflow.
Labelbox

LabelBox is a popular data labeling tool that offers an iterate workflow process for accurate data labeling and creating optimized datasets. The platform interface provides a collaborative environment for machine learning teams, so that they can communicate and devise datasets easily and efficiently. The tool offers a command center to control and perform data labeling, data management, and data analysis tasks.
The overall process involves:
- Management of external labeling service, workforce and machine labels.
- Optimization for different data types.
- Analytical and automatic iterative process for training and labeling data and making predictions, along with active learning.
The benefits are:
- Centralized command center for ML teams to collaborate.
- Easy to perform tasks with complete communication.
- Iterate your process with active learning to perform highly accurate labeling and create improved datasets.
Tagtog

Tagtog is a data labeling tool for text-based labeling. The labeling process is optimized for text formats and text-based operations, to create specialized datasets for text-based AI.
At its core, the tool is a Natural Language Processing (NPL) text annotation tool. It also provides a platform to manage the work of labeling the text manually, take in machine learning models to optimize the task, and more.
With this tool, you can automatically get relevant insights from text. It helps to discover patterns, identify challenges, and realize solutions. The platform has support for ML and dictionary annotations, multiple languages, multiple formats, secure Cloud storage, team collaboration and quality management.
The process is simple:
- Import text-based data in any file formats.
- Perform labeling automatically or manually.
- Export accurate datasets with API format.
The benefits are:
- It’s easy to use and highly accessible to all.
- It’s flexible, you can integrate it in your own application with personalized workflow and workforce.
- It’s time- and cost-efficient.
Playment
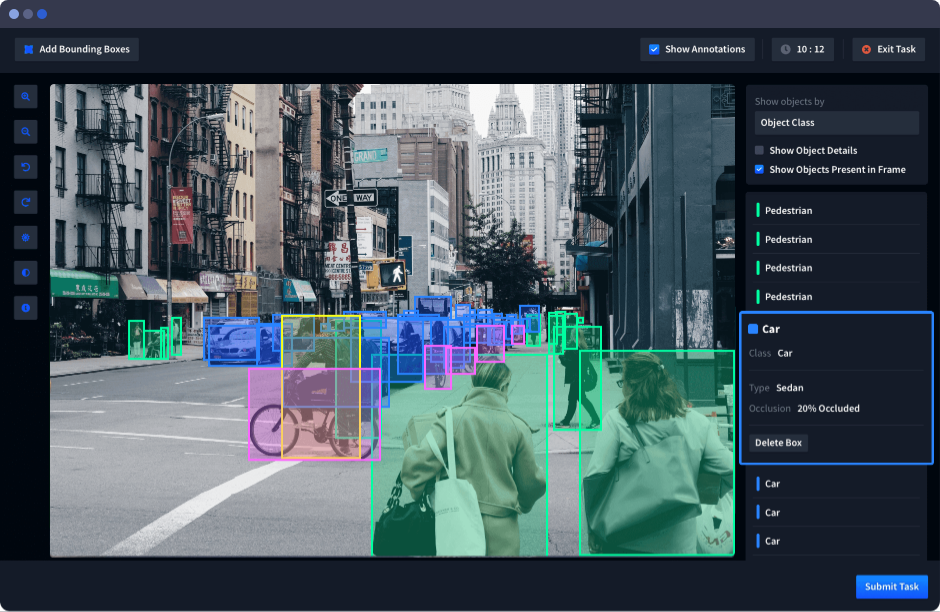
Playment is a multi-featured data labeling platform that offers customized and secure workflows to build high-quality training datasets with ML-assisted tools and sophisticated project management software.
It offers annotations for various use cases, such as image annotation, video annotation, and sensor fusion annotation. The platform supports end-to-end project management with a labeling platform and auto-scaling workforce to optimize the machine learning pipeline with high-quality datasets.
It has features like workflow customization, automated labeling, centralized project management, workforce collaboration, built-in quality control tools, dynamic business-based scaling, secure cloud storage, and more. It’s an awesome tool to label your dataset and produce high-quality accurate datasets for ML applications.
The benefits are:
- All-in-one tool with a centralized project management center.
- Collaboration platform for ML teams to seamlessly participate.
- Easy to use and automated with built-in automated tools.
- Big emphasis on quality control.
Dataturk
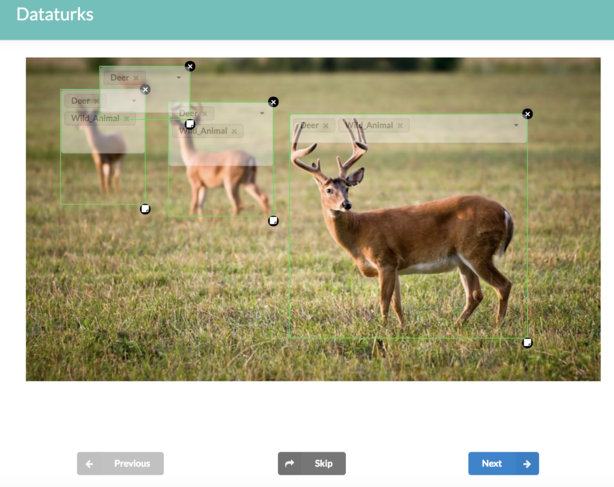
Dataturk is an open-source online tool that provides services primarily for labeling text, image, and video data. It simplifies the whole process by letting you upload data, collaborate with the workforce, and start tagging the data. This lets you build accurate datasets within a few hours.
It supports various data annotation requirements such as Image Bounding Boxes, NER tagging in documents, Image Segmentation, POS tagging, and more. Easy and simple UI for workforce collaborations.
The overall process is simple:
- Create a project based on required annotation.
- Upload the required data in any related format.
- Bring the workforce in and start tagging/labeling.
The benefits are:
- Open-source tool so the services are accessible to all.
- Simple UI platform for coordination between team and labeling.
- Highly simplified labeling process to create datasets in a short period of time.
LightTag
LightTag is another text-labeling tool designed to create accurate datasets for NLP. The tool is configured to run in a collaborative workflow with ML teams. It offers a highly simplified UI experience to manage the workforce and make annotations easy. The tool also delivers high-quality control features for accurate labeling and optimized dataset creation.
The benefits are:
- Super simplified UI platform for easy labeling process and team management.
- Faster and efficient data labeling without any complex feature hassles.
- Reduces time and project management cost.
Superannotate
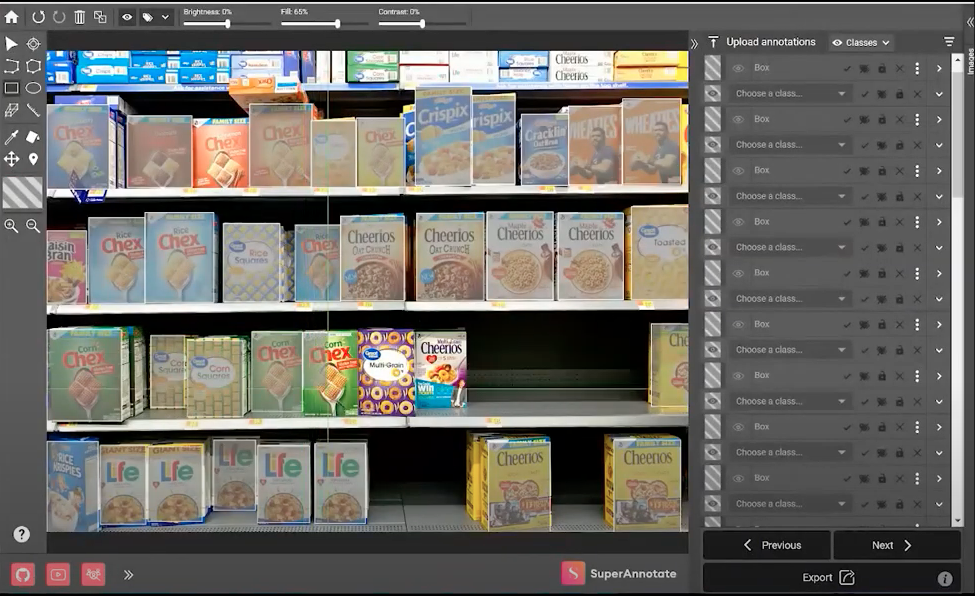
Superannotate is the fastest data annotation tool specially designed as a complete solution for computer vision products. It offers an end-to-end platform to label, train, and automate the computer vision pipeline. It supports multi-level quality management and effective collaboration to boost model performance.
It can integrate easily with any platform to create a seamless workflow. The platform can handle labeling for image, video, LiDar, text/NLP, and audio data. With performant tools, automated predictions, and quality control, this tool can speed up the annotation process with utmost accuracy.
The benefits are:
- The platform supports smart predictions and active learning to create more accurate datasets.
- It utilizes transfer learning methods to improve the efficiency of overall training.
- It supports manual as well as automatic labeling with proper quality assurance structure.
CVAT

CVAT is a powerful open-source labeling tool for computer vision. It mainly supports image and video annotations. CVAT facilitates tasks such as image segmentation, image classification, and object detection. The tool is pretty powerful for the work it does, but it’s not easy to use.
The overall workflow and use cases are a bit hard to understand. It takes training to master this tool. CVAT is only accessible from the Google Chrome browser. The web interface is difficult to get used to. The tool is efficient in terms of labeling and dataset generation, but lacks the quality control mechanism, so you need to do it manually.
The benefits are:
- The tool is open source and highly efficient for image and video based annotations.
- It supports automatic labeling.
Conclusion
Data annotation or labeling has always been an essential component in the field of machine learning and AI. Before labeling tools existed, the manual effort that was needed to label each data point in the dataset was tremendously inefficient, error-prone, and difficult.
Now, with the state-of-the-art tools above, the process is much easier thanks to automation, team management, prediction analysis, and iterative learning. In consequence, datasets are much more accurate and optimized with different variable changes.
These tools have made work easier for data scientists and ML developers. Datasets for different applications are readily available. With the ability to pipeline labeled datasets to machine learning models, the overall AI-based work and model creation has become easier, more accurate, and optimized.
