
Computer vision models have become insanely sophisticated with a wide variety of use cases enhancing business effectiveness, automating critical decision systems, and so on. But a promising model can turn out to be a costly liability if the model fails to perform as expected in production. Having said that, how we develop and deploy computer vision models matters a lot!
Machine learning engineers are slowly embracing DevOps practices in their model deployment systems, but it doesn’t end there! We also need to consider several aspects like code versioning, deployment environment, continuous training/retraining, production model monitoring, data drift & quality, model features & hyperparameters, and so on. But some of these practices are specific to machine learning systems.
In this article, we will take a look at how we should deploy Computer Vision models while keeping the above-mentioned aspects in mind.
Computer vision model lifecycle
Deploying a computer vision model or rather any machine learning model is a challenge in itself, considering the fact that only a few of the developed models go to continuous production environments.
The CV model lifecycle starts from collecting quality data to preparing the data, training and evaluating the model, deploying the model, and monitoring and re-training it. It can be visualized through the chart shown below:

In this article, we will focus on the deployment phase of computer vision models. You will learn key aspects of model deployment including the tools, best practices, and things to consider when deploying computer vision models.
CV model deployment modes, platforms & UI
In this section let’s dive into different ways you can deploy and serve Computer Vision models. The key elements that need to be considered here are:
- Deployment modes (with REST/RPC endpoints, on the edge, hybrid)
- How they are served to the end-user
- Ease of access to hardware and scalability of the deployment platform
Deployment modes (with REST/RPC endpoints, on the edge, hybrid)
Machine learning models hosted on on-premise/cloud platforms are often deployed or rather accessed through API endpoints. APIs such as REST/RPC essentially provide the language and a contract for how two systems interact.
Another mode is to deploy models on edge devices, where the consumption of data through CV/cognitive applications happens at the point of origin. Oftentimes the deployment can go hybrid too, i.e a combination of API end-points as well as edge devices.
How are they served to the end-user
Depending on how the end-user will consume the model, the interfaces can vary. Models may be served to some users through a simple bash command-line interface while others could consume it through an interactive web-based or app-based UI. In most cases, the model can be served through an API and a downstream application consumes the results.
Ease of access to hardware and scalability of the deployment platform
Just like the options available in terms of UI/UX, a multitude of options are available with the platforms or the hardware where we can deploy the production models. That includes the laptop where the developer often carries out code development, a remote machine, remote Virtual Machines, remote servers where jupyter notebooks are hosted, containers with orchestrators deployed in cloud environments, and so on.
Each of the points mentioned above is elaborated on in the following sections.
CV deployment through API (REST/RPC) endpoints
REST stands for “representational state transfer” (by Roy Fielding). In a nutshell, REST is about a client-server relationship, where data is made available/transferred through simple formats, such as JSON/XML. The “RPC” part stands for “remote procedure call,” and it’s often similar to calling a function in JavaScript, Python, etc. Please read this article for a detailed understanding of REST/RPC protocols.

When an ML deployment API interacts with another system, the touchpoints of this communication are happening through REST/RPC endpoints. For APIs, typically an endpoint consists of a URL of a server or service. It is like a software intermediary that allows two applications to exchange data with each other. It’s also a set of routines, protocols, and tools for building software applications. Some of the popular pretrained CV cloud services are completely served on API endpoints, for example, Google Vision API.
REST simply determines how the API architecture looks. To put this in a simple way, it is a set of rules that developers follow when they create APIs.
Usually, each URL is called a request(API request) while the data sent back to you(mostly as a JSON) is called a response.
An API request primarily consists of four components:
- The endpoint: endpoints have something called a URL which determines the resource or data you’re requesting for. These URLs or paths, in the context of an API, are called endpoints.
- The method: a method is a request you send to the server such as GET, POST PUT, DELETE, etc.
- The headers: headers carry information for Request and Response Body, Authorization, Caching cookies, and so on.
- The data: usually in the form of JSON strings and data URLs.
Some of the tools that we can rely on to create Pythonic REST APIs are mentioned below (under the assumption that we are using Python as our ML backend code). The scope of this article is not to dive deep into each of these frameworks but to give a high-level overview of them.
- Flask REST API
Flask is a Python microframework used to build web applications and REST APIs. Flask’s main job is to handle HTTP requests and route them to the appropriate function in the backend application.
- Django REST API
Another popular option for building REST APIs is the Django REST framework. The patterns to build an API are usually added on top to a Django web UI project.
- FastAPI
FastAPI is a Python web framework that’s specially built for building efficient APIs. It uses Python-type hints and has built-in support for async operations. The FastAPI framework is recently becoming more and more popular due to its ease of use and versatility.
Deploying computer vision applications through the python APIs is just as similar to deploying any machine learning model. In the case of APIs catering to computer vision deployments, it’s important you need to pass on Images/videos for processing and as a response from backend deployment. Sending images/videos or other data files can be done through some of the methods discussed below
Parsers
REST Frameworks in general have built-in parsers that it uses to detect the type of data in the request. Some of them are JSONParser, FormParser, MultiPartParser, FileUploadParser, and so on. In computer vision deployment, FileUploadParsers will play a major role in handling data transfer from backend-frontend.
A sample snippet for file upload parser(in our case, an image/video, etc) with Flask Framework is shown below. The code structure of course varies with Django and FastAPI frameworks.
from flask import Flask, render_template, request, redirect, url_for
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/', methods=['POST'])
def upload_file():
uploaded_file = request.files['file']
if uploaded_file.filename != '':
uploaded_file.save(uploaded_file.filename)
return redirect(url_for('index'))
Code snippet | Source
For a detailed guide on python API creation, this would be an excellent article to read through.
In the context of deployed machine learning models, users can leverage API endpoints and associated URL paths to transfer data, processes, and transactions with the underlying inference engine which means it can transfer images, video data, and commands back and forth. The usage of API endpoints to consume computer vision models is only bound to rise over time.
Computer vision API providers
There are many service providers out there who provide computer vision APIs that can be directly integrated with your application. A few of them are discussed in detail below. Interestingly you have an option to build your custom UI or to use the default service provider UIs over those APIs.
Nyckel
Nyckel is offering computer vision APIs alongside others which can be accessed through RESTful HTTPS requests. They provide a number of pretrained CV-specific use cases like Barcode less scanner, Quality inspection systems, Human emotion analysis, and so on.


Nyckel cognitive solutions | Source
Nyckel supports three input data types through https requests: text, image, and tabular.
1. Text: requests and responses that pass Text data will be handled as JSON strings.
2. Image: requests to pass Image data can be provided in the ways below:
- Raw image bytes
- As a data URI in a JSON request
Responses that pass image data will be provided as a JSON string in the ways shown below:
- URL which directs to the image
- A data URI which contains the image.
3. Tabular: they are handled as JSON key-value pairs. I.e both requests and responses. It allows the user to build custom UIs or as an intermediate API in a larger application pipeline.
Complete documentation on accessing Nyckel API can be read through the web document shared here.
AWS Rekognition
It is a part of the broader AWS cloud solutions suite. This tool offers pre-trained and customizable computer vision capabilities to extract information from pictures, videos, etc. ‘Rekognition’ is well-suited for a beginner, since it does not require deep knowledge of theory pertaining to computer vision. Off the shelf solutions with Rekognition include content moderation, facial recognition, video analytics, text recognition, and so on.
Amazon Rekognition provides two API sets. Amazon Rekognition Image for analyzing images and Amazon Rekognition Video for analyzing videos. The data that needs to be analyzed will be uploaded into an S3 bucket and can be invoked through AWS CLI & SDKs.
Both APIs analyze images and videos to provide insights you can use in your applications. Or as mentioned before, you can use it as an internal API that can be accessed through REST/RPC endpoints.

Google Cloud Vision API
Vision API offers powerful pre-trained machine learning models through REST/RPC APIs. Similar to Rekognition by Amazon, it can assign labels to images and quickly classify them into predefined categories. It can detect objects and faces, read printed and handwritten text.
The deployment architecture shown below is for an OCR application leveraging Google Cloud Vision API.

The flow of data in the OCR (optical character recognition) application using Vision API involves steps shown below:
- 1 An image uploaded that contains text in any language
- 2 Vision API is triggered to extract the text and detect the source language
- 3 A translation is queued in case the target language is different from the source
- 4 Translation API is triggered to translate the text in the translation queue
- 5 Saves the translated text from the result queue to Cloud Storage, which can be accessed later
For further information, please go through the Google Cloud OCR tutorial.
Kairos face recognition API
The Kairos Face Recognition API uses computer vision algorithms to analyze human-like faces found on images and videos and returns data about the detected faces. This data can be used in applications such as image search, matching and comparing faces, or detecting characteristics such as gender or age.

Kairos is a fairly easy-to-implement computer vision API, offering cloud-based services for facial recognition for custom business use cases.
Edge deployment of CV models
Before diving into the concept of on edge deployment, it’s important to understand what edge computing is.
Simply put, edge computing is a process where computing happens at the same location or close to where the data originates.
Nowadays businesses are flooded with data that they really don’t know what to do with. The traditional way of analysis was to transfer generated data through the internet to be used for computing jobs somewhere else. But that model has become insufficient due to the sheer volume of data generated and the latency associated with the same. These issues are now tackled through edge computing systems. The following image shows a direct comparison of cloud vs edge cloud vs edge computing.

In the context of CV edge deployment, it refers to computer vision models that are created and trained in a cloud or on-premise infrastructure and deployed on edge devices. State of the art Computer Vision-based systems such as autonomous vehicles, industrial robots used in manufacturing, autonomous drones, etc. leverages high levels of edge computing/deployment capabilities.
Let’s get into some classic use cases of on-edge deployment of computer vision algorithms. An example shown below goes briefly into how on-the-edge computer vision systems help retailers (e.g. grocery stores) to monitor live events and take prompt actions to optimize their sales volumes.
Cameras installed on-premises can capture live video feeds on customer queueing at check-out counters, crowding in certain sections, identifying empty shelves, buying patterns of customers over a period of time, theft/fraud happening at self check-out stations, and so on.
The image below shows the objects being identified and tracked in a supermarket setting. The complete paper can be accessed through this link.


Another application area for on-edge deployment of CV models is Industrial automation. An example of real-time quality inspection of welds in an Industrial setting is shown below. The robotic arm shown is mounted with a camera that identifies where the problems are occurring in a weld pool so that corrective action can be taken. The captured input stream is ingested into a system based on Intel Edge AI processors. Built on a computer vision-based AI inference engine, this solution detects welding defects and sends commands to pause the robotic arm immediately so that corrective action can be taken in time.

Almost all of the popular cloud service providers provide on-edge deployment services. Some of them are taken up and discussed below.
IBM Edge Application Manager (IEAM) is a model management system that can create, deploy and update machine learning models on edge devices. This specific solution can manage metadata and synchronize the deployments across multiple edge devices. On a high level, there will be two components of the application, one in the cloud and the other hosted on edge devices which will be synchronized with the help of HTTPS connections. A representative image of the IEAM model management system is shown below.

Edge deployment solutions by Azure
All the Azure capabilities such as computing, storage, networking, and GPU-accelerated machine learning can be brought into any edge location using Azure stack edge.
The deployment architecture for a Video Analyser on edge devices might use the following Azure services: (Only the relevant few are listed, the actual list can vary depending on the application.)
- Azure machine learning: to build, train, deploy, and manage ML models in a cloud-based environment.
- Azure video analyzer: to build intelligent video-based applications using your choice of AI.
- Azure container registry: builds, stores, and manages containerized(Docker) computer vision/ML models.
- Azure stack edge: designed for machine learning inference at the edge. Data is preprocessed at the edge before transfer to Azure, accelerator hardware which can improve the performance of AI inference at the edge.
- Azure IoT hub: a cloud-based managed service for bidirectional communication between IoT devices and Azure.
- Media services storage: uses Azure storage to store large media files.
- Local data: stored and used in the training of the machine learning model.
The example diagram shown below goes briefly into how Azure helps retailers like grocery stores to monitor live events and take prompt actions. Cameras installed on-premise can capture live video feeds on customer queueing at check-out counters, customer crowding in certain sections, identifying empty shelves, buying patterns of customers over a period of time, theft or fraud happening at self check-out stations, and so on.
The image shown below is a representative Architecture used by Azure edge deployment for a video analytics system. You can read about the deployment architecture in detail through the same link.

AWS Panorama
AWS Panorama is a machine learning (ML) appliance and software development kit (SDK) from Amazon that brings CV to on-premises/edge devices, especially IP cameras. Enterprises have access to many video assets from their existing cameras, but the data remains untapped mainly without the right tools to gain insights.
AWS Panorama enables you to bring computer vision to on-premises devices with low latency effects. It works with devices on the edge; hence scenarios with limited internet bandwidth are smoothly managed by default. Also, users can easily bring custom trained models to the edge and build applications that integrate with custom business logic

Here is the link to an implementation of a parking lot car counter application using AWS Panorama.

Similar to the example cited above, there could be a plethora of similar applications such as counting the number of visitors to a shopping mall, computing traffic density at any given time, improving restaurant operations, etc.
CV model deployment UI
After discussing the API endpoints, the time is ripe for us to take the discussion to the popular UI options available for CV deployments. Let’s explore some of the popular & convenient UI options available.
Command-line interface
A command-line interface (CLI) is a text-based user interface (UI) used to run programs, manage computer files and interact with the computer. CLIs accept input commands entered through the keyboard; the commands invoked at the command prompt are then run by the computer.
Bash is the most common CLI for Linux, Mac OS, and PowerShell/command prompt for Windows.
Here, the requirements are that the CLI recognizes the python file, which contains the CV code and the input data. The results get produced and stored in a location you can access later. But as mentioned before, this way of model serving is usually not very appealing to potential users for obvious reasons.
Web application with Flask-REST API, HTML & CSS
Flask is a small and lightweight Python web framework that provides valuable tools and features that make creating web applications and APIs in Python easier. It allows us to create lightweight web apps that you can run in local machines, cloud environments, or containers with reasonably low code. It can also render HTML text on the browser, allowing you to customize the UI used for model serving. So if we can use CSS alongside HTML, that becomes more visually attractive in line with web apps we see while surfing the web.
A code snippet showing Flask usage with python is shown below:
from flask import Flask, render_template
app = Flask(__name__)
@app.route("/")
def home():
return render_template("homePage.html")
@app.route("/new_address")
def salvador():
return "Hello, new_address!"
if __name__ == "__main__":
app.run()
By executing the code snippet shown above, the following things happen:
- Importing the Flask module and creating a Flask webserver
- __name__ means this current file
- app.route(“/”) represents the default page. This message pops up when we connect the browser to the localhost port
- The render_template renders the HTML & CSS file provided with the code; this makes the UI nicer!
- app.route(“/new_address”) from browser routes to the next method shown in the snippet, which in turn prints out “Hello, new_address!”
For more information and hands-on implementation, please refer to this article.
Shown below is an example of using Flask based web application tailored for multiclass image classification.

If you want to develop a similar application and read further, follow this link.
Model deployment using Flask is ideal for local deployment or even on a cloud server with many users consuming the API. You can build a scalable Flask application using `docker-compose` and Nginx load balancer, where Nginx is an open-source HTTP web server that can also act as a reverse proxy server.

With Docker-compose, you can create multiple instances of the Flask applications served by Nginx load balancer. You can go through a detailed implementation of the same in this article.
Web app with Flask API (or any Python API) and React FE, CSS
Vanilla Flask isn’t always user-friendly. It isn’t always helpful with automatic UI updates, dynamic querying, etc.
Moreover, we cannot expect it to create UIs as cool as React or Angular can produce unless you have got some advanced JQuery form submission techniques embedded in it. React Native is right on top among the most popular(and powerful) web UI tools available. It powers some of the most widely used web/mobile apps and interfaces.

As a seasoned data scientist familiar with Python, picking up a JavaScript-based tool might be difficult for you. But by coupling React with a Flask API & python for the backend, that becomes one the coolest ways you can create a UI for your CV models. Here is a screenshot using React Native UI for image classification.

Here is a link for creating an image classification app using React and Tensorflow. Another implementation of React and Flask deployed to Heroku is shown here.
A decision to use React for UI means hiring a specialized UI developer or learning a new UI tool and scripting language altogether!.
Model serving web UI with Streamlit
In my opinion, Streamlit could be the fastest way to create a web app for a seasoned data scientist who is more familiar with Python than Javascript (React is primarily based on Javascript). The developer can create a web app along with the backend ML algorithms. So unlike Flask/React-based systems, it doesn’t need separate http/s routing to send JSON data. The best part is it has inbuilt features to render tabular, image, gif data, etc., onto a web screen, and it is also open source! What else do you need?
For the same reason, it’s emerging as one of the most popular ways of serving a computer vision model or rather any machine learning model in general.
An example of how cool a Streamlit web UI can be is shown below: (All these with minimal python style code!)

CV model serving platforms
All of the things discussed above, be it ML lifecycle operations or a UI, require some sort of platform to operate. The choice between these platforms is often primarily based on:
- 1 Costs involved
- 2 Organisation’s choice of cloud providers
- 3 Available on-premise infrastructure
- 4 Tech savviness of the intended user personas
- 5 The targeted volume of users etc.
For example, the users often want AI to be invisible while they use the solution. That means often users don’t want to get tangled in the intricacies of AI-based decision-making.
A UI in the form of a web app deployed at any cloud platform would be sufficient for them. But in some instances, users need enough flexibility to modify the algorithms & need customized UIs. How you serve your model will depend on the factors mentioned above.
There are fully-integrated machine learning platforms available for many Cloud service providers. Let’s take a look at a few of them.
AWS Sagemaker
SageMaker is AWS’s fully integrated platform for Machine learning. It features image annotation platforms, embedded Jupyter notebook environments, experiment tracking, model monitoring, etc. It is also an excellent tool for developing machine learning algorithms that need careful tailoring and customizations compared to point and click solutions given in Rekognition.
The ecosystem works very well with all other AWS-related tools. Hence, if your organization is an AWS customer and plans to dive into building complex computer vision or any machine learning models, Sagemaker would be a great addition to the existing suite.
An example of end-to-end Multiclass Image Classification is given in this example with the usual machine learning project steps:
- 1 Preprocessing
-
2
Data preparation
- 3 Model training
- 4 Hyperparameter tuning
- 5 Training & Inference
These are all mentioned in the article shared above.
Apart from image classification, Sagemaker provides inbuilt annotation tools for semantic segmentation, instance segmentation, object detection, etc. But the level of sophistication offered by some of the standalone tools (discussed earlier in this article) could fare better than these general annotation services.
The image below shows some of the annotation options offered by Sagemaker.

An Example of semantic segmentation using Sagemaker is shown in the image below.

Azure Machine Learning
Azure ML is another cloud-based environment that you can use to train, automate, deploy and monitor machine learning models.
Automated ML in Azure supports model training for computer vision tasks like image classification, object detection, and instance segmentation. Authoring AutoML models for computer vision tasks are currently supported via the Azure Machine Learning Python SDK. The resulting experimentation runs, models, and outputs are accessible from the Azure Machine Learning studio UI.
It has inbuilt integrations with popular machine learning and deep learning libraries such as Pytorch, TensorFlow, MLflow, etc. The interesting part is that it has its own open-source MLOps environment. A quick peep into the steps of ML pipelines using Azure ML is shown below which is common to pipelines using computer vision too:
- 1 Task type selection
- 2 Data consumption
- 3 Data augmentation
- 4 Configuring and running experiment
- 5 Selection of evaluation metrics
- 6 Hyperparameter optimisation
- 7 Registering and model deployment
Similar to the features offered by AWS environments, Azure AutoML supports tasks like Image Classification, image classification multi-label, image object detection, image instance segmentation, etc.
Towards the right, different inbuilt annotation tools available are also shown. So CV projects with fairly simpler annotations can be handled within Azure ML without much effort.

The following architecture shows how to conduct distributed training of CV models across clusters of GPU-enabled machines. The scenario is image classification, but the solution can be generalized to other CV use cases
Such as semantic segmentation, object detection, etc.

A CV model developed end to end in Azure can be deployed easily using the Azure Kubernetes web service.
Here is a link to Set up AutoML to train computer vision models with Python. Go through it if you want to explore Azure ML capabilities further.
Google Cloud AI platform
This platform is another fairly advanced platform from Google with many features supporting Machine learning lifecycle management. The flagship products offered by google on computer vision are:
- Vertex AI: brings together all the Google Cloud services under one platform, along with a UI and an API. In Vertex AI, you can train and compare models using AutoML or custom code training and all your models are stored in one central model repository. All the MLOps tools provided by Google are available within a single platform.
- AutoML Vision: provides an easy-to-use GUI to train your own custom CV models. AutoML Vision optimizes the model for accuracy, latency, and size and exports them to the cloud or any devices at the edge.
Another powerful solution from the house of Google is the Visual inspection AI. This finds direct application in detecting production defects in the manufacturing industry.
Some of the applications include Visual inspection of Robot weld seams, PCB inspection, etc.


Visual Inspection AI | Source
You will find easy-to-learn use cases from the same source to help you get started with any of the google cloud vision tools. Whatever the needs are, google cloud tools have pricing that works for you. It could be pay-per-use, scaling monthly charges, flat rates per node hour, etc.
Kubeflow
Kubeflow is another open-source machine learning platform that integrates seamlessly with major cloud platforms.
Kubeflow aims to make it easy for machine learning (ML) engineers and data scientists to leverage cloud assets (public or on-premise) for ML workloads. With Kubeflow, Jupyter notebooks can develop ML models and create Kubernetes resources to train, containerize and deploy their models at scale in any platform, i.e. on-premise, remote or cloud environments. Since the initial phase of Kubeflow development happened at Google, It has had excellent integration capability with the Google Cloud platform (GKE – Google Kubernetes Engine).


Kubeflow which runs on top of Kubernetes can operate on both cloud and on-premise platforms, but deploying Kubernetes optimized machine learning models is a Herculean job. However, the developers make constant efforts to ease its adoption.
In either case, Kubeflow becomes an excellent platform of choice for deploying computer vision models coupled with a cloud service provider or even an on-premise installation.

From a Computer Vision model deployment perspective, Kubeflow can create scalable CV deployments when provided with ample resources such as RAM, storage space, and processing power. An Issue MLOps Engineers face while using it is its inherent complexity to learn and Master the capabilities offered by Kubeflow.
Comparison between Kubeflow and neptune.ai
Other tools that may be useful when deploying CV models
neptune.ai
neptune.ai is the most scalable experiment tracker designed with a strong focus on teams that train foundation models. It lets you monitor months-long model training, track massive amounts of metrics, results, and metadata you generate (while keeping it safe), and compare them in the blink of an eye.
With Neptune, you can organize the computer vision experiments in one place to collaborate effectively with your team. From a CV model deployment perspective, Neptune offers a plethora of insights into each of the model performance parameters at every experiment run. This gives enough room for experimenting with more hyperparameters such as learning rate, optimization algorithms, and so on. Hence model selection for production deployment is simplified.
Also, Neptune is known for its user-friendly interface and flexibility, enabling teams to adopt it into their existing workflows with minimal disruption. Neptune gives users a lot of freedom when defining data structures and tracking metadata.


MLflow
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. MLflow offers features such as experiment tracking, model packaging, model registry, etc. MLflow integrates with most of the popular machine learning tools/libraries such as Scikit learn, Tensorflow, Pytorch, Spark, etc. Also, containerization tools such as Docker & Kubernetes and built-in integrations with the most popular cloud platforms are available.
Like any other ML project, MLflow can also support computer vision-related projects. That includes creating model registries for experimented models, artifacts generated during each of these experimentations, etc. The image below shows some of the popular libraries MLflow can integrate with. The actual list is larger than the ones shown in the diagram. Databricks has inbuilt integration with MLflow.
MLflow’s ease of integration with docker-compose code also makes it a popular deployment alternative among open-source code users for quick containerized deployment. As an open-source tool, MLflow is very versatile in handling model registries and metadata as an open-source tool. Hence if your CV model deployment is on a constrained budget, this would be an ideal platform to go with.

An example of productionizing computer vision models using MLflow & Redis AI can be seen on this link.
Comparison between MLflow and neptune.ai
Apache Airflow
It’s a workflow management platform primarily for data engineering pipelines. Airflow is written in Python. So a key advantage of Airflow is that you can orchestrate the workflows through python scripts. Workflows are designed to be mostly static or slowly changing. Airflow workflows are expected to look similar within subsequent runs; this allows for clarity around unit of work and continuity.

From a computer vision perspective, Airflow can be used to execute a certain pipeline of operations on image datasets, their versioning, etc. An interesting use case would be the image/video data flowing in to train self-driving algorithms. Newer sets of data need to be passed through transformation pipelines for model retraining & data drift monitoring on a continuous basis.

DVC
DVC is built to make ML models sharable and reproducible. It’s specifically designed to handle large datasets, files, ML models, metadata as well as code. It is a generic tool for all types of ML deployments, not just specific to computer vision.

DVC offers capabilities such as:
- Data version control: lets you capture the versions of data and models in Git commits while storing them on-premises or in cloud storage depending on the storage hardware opted for.
- ML project version control: i.e. versioning of ML models and datasets & metadata by connecting with cloud storage such as google cloud storage, Amazon s3 buckets, and so on.
- ML experiments tracking: Using Git versioning to track experiments. DVC makes experiments and associated branching as fast in Git.
- Deployment & collaboration: With its inherent git-like functionalities, production deployments are also more intuitive. Also, a robust collaboration between different teams is possible and introduces a high level of flexibility.
Comparison between DVC and neptune.ai
CV model deployment maturity levels
The success of an ML deployment mostly lies in the level of automation. So that means the lesser the manual intervention required to maintain the model in production, the more mature it has become.

The levels of maturity can be attributed to current deployment practices shown below. You can read the detailed article on the Google Cloud documentation page. This section is not specific to computer vision but a general guide for all the ML model deployments.
Manual process
As the name suggests every one of the ML model development cycle steps is carried out manually. The process is more experimental and iterative. Model development, validation, etc., happens in iPython notebooks or similar rapid development environments. Typically each of the steps is disconnected from each other. However, CI/CD operations are absent at this level. It is particularly suited when the data scientists/team handles only a few models and datasets, which often do not change over time.
Typical steps pertaining to a computer vision model include:
- Collection of training data through web-scraping or open datasets
- Using an annotation tool
- Using notebooks for code/model development
- Iterative steps for model training & validation
- Handing off the model to the Engineering team for API configuration, testing & deployment.
This level of maturity is common to businesses that have just started to apply machine learning in their use cases. But It comes with various challenges, such as models failing to adapt to changes with changing input data or, in the worst-case scenario, the model could fail while in production. MLOps practices such as CI/CD/CT help address these challenges.
ML pipeline automation
At this level of automation, retraining and delivery happen automatically. That means retraining is triggered either on the arrival of substantial amounts of new data or with time or whenever a model performance drift is observed. Running experiments in parameter space, logging production models, model validation & redeployment of production models are expected to happen automatically at this level of maturity.
Some characteristics of an ML pipeline at this level are:
- Rapid experimentation
- Continuous training
- Modularized & reusable code for components and pipelines.
- Continuous delivery and so on.
Some additional components that can be expected at this stage are:
Data validation
A setup to validate data through pre-built data pipelines is expected at this level. That includes checks for data quality, drift, skewness, robustness, etc. If the newer data doesn’t comply with the legacy schema, the training pipeline should be stopped, and the data science team should be alerted to mitigate these issues.
Model validation
Automated pipelines are expected to evaluate the performance of freshly trained models against existing production models for newer training data. For example, in the case of a computer vision object detection model, it’s imperative to ensure mean IoU (Intersection over Union), average precision of all object classes (or at least two-thirds of object classes) of the newly trained model is better than the existing production model.
CI/CD/CT
At this level, the model deployment graduates to a fully scalable architecture. Most often they are cloud deployments with robust web UIs, load balancers, scalable databases, and so on. With the ever-increasing trainable data at disposal, parallelized & GPU-based computing becomes even more crucial at this stage. Model performance parameters are scrutinized in even greater detail.
It could include:
- Source control: The practice of tracking and managing changes to code
- Testing services: Process of evaluating and verifying that a product does what it is supposed to do
- Model registry: A central repository that allows model developers to publish production-ready models for ease of access
- Feature store: A centralized repository where the access to features for training & serving can be standardized.
- Metadata management: Information about experiments, model parameters, timestamps, model performance metrics, model artifacts, and so on.
- Scalable containerized deployments
- Web traffic load balancers, database scaling etc.
A scalable MLOps setup warrants several components as shown below:

Surprisingly only a small fraction of Machine learning systems are composed of ML-related code. The surrounding components make it complex.
So some of the steps that we follow in DevOps (popular practice in developing and operating large-scale software systems) are often employed in MLOps as well. Such as:
- 1 Continuous integration
- 2 Continuous delivery
- 3 Continuous training (unique to MLOps)
But In the context of MLOps, CI is not just about code testing and validation, but validating data quality, and model features as well. In the context of CD, there is an additional delivery training pipeline and prediction service.
Best practices in computer vision models deployment
Test-driven machine learning development
It is another practice borrowed from traditional test-driven software development.
“Test-driven development (TDD) is a software development process relying on software requirements being converted to test cases before software is fully developed, and tracking all software development by repeatedly testing the software against all test cases. This is as opposed to software being developed first and test cases created later”
Source
So Instead of developing a full-fledged solution in the first go and testing being done at a later stage, the tests and code are iteratively built together one feature at a time.
Automated tests and TDD help AI engineers in several ways. Some of them are:
- Provide on-time feedback: instantly know whether the code meets the specifications, detect problems early on, and perform incremental debugging.
- Tackle challenges iteratively: like developing software through small increments, a similar approach can be addressed in AI systems development.
- Expend little or no wasted effort: write only the code needed to implement a requirement.
TDD makes it easy to organize the code and solve issues efficiently. This article presents a step-by-step test-driven development of a computer vision web App. You can learn about a more generalized TDD approach applicable to all AI systems in this article.

Another excellent explanation of test-driven development is given in this article. ATDD stands for Acceptance Test-Driven Development. Before starting the development, this technique involves customers, testers, and developers in the loop. The acceptance criteria are decided based on the consensus between all the stakeholders involved. ATDD ensures all stakeholders are aligned with the goals the team is working toward.
Unit tests for computer vision models
Unit testing is a handy technique essential for test driver software development. Unit tests involve testing individual pieces of the source code, primarily functions, and methods, to ascertain that they meet the expected behavior/outputs.
Unit tests are usually light and don’t take much computational effort. Specific python libraries are available to help you with setting up these frameworks. An example of unit testing in the CV model pipeline would be asserting the size of the image or tensor returned by a data loader function.
Model monitoring: the way you ensure the CV model deployment stays relevant!
While in production, computer vision models could deteriorate even faster than NLP-related models in production. This is solely due to the fact that things that we see change much faster than how we use our language.
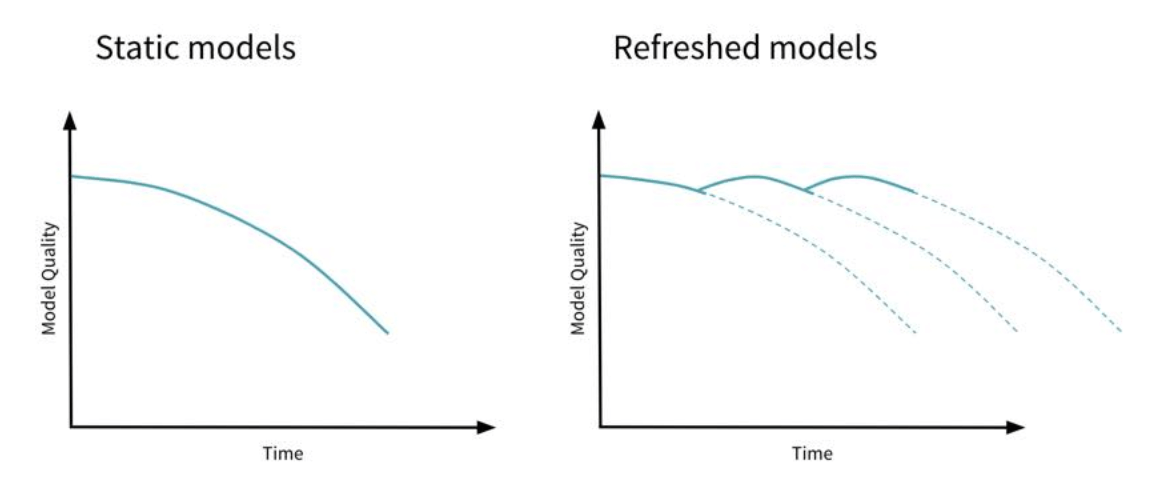
So, what parameters do we need to monitor then? Well, they are the same ones we used to benchmark the model performance in the first place!. The parameters to monitor differ with model types. Along with a statistical metric, I also recommend human intervention before you consider any retraining. Sometimes, the performance decay might not show up in the metric, but it could be visually discernible.
We need to have ground truth (labels) before we monitor production machine learning models. That means target labels are the gold standard for model monitoring. Well, this might not be feasible in many cases. How to monitor in scenarios where labels aren’t available is discussed later in this section.
The metrics discussed below are primarily based on the assumption that labels are available for the newer datasets.
Best Tools to Do ML Model Monitoring
Object detection
In computer vision, object detection is one of the powerful algorithms which helps in the classification and localization of the object from images.
The primary object detection metrics that you need to monitor are:
- Average intersection over union (IOU): it is defined as the average intersection over the union of the detection bounding boxes and the ground truth bounding box above the evaluation threshold, say 0.5. IoU can determine the number of True positives and False positives detected. Other associated parameters are precision, recall & F1 score. To know more, please refer here.

- Average precision (AP): average precision can be defined as the area under the precision/recall curve for a single object class under various IoU thresholds. Tracking this metric might make sense if your object detection model is assigned to look for only one particular object type.
- Mean average precision (mAP): the mAP score is computed using the average precision overall classes (mentioned above) and overall IoU thresholds.

where IoU threshold is 0.5 | Source
With the metrics mentioned above, we can track the model performance over newer data sets. It could be benchmarked with the existing model performance values to decide whether retraining is necessary.
Object Detection Algorithms and Libraries
Semantic segmentation
The primary monitoring metric used in semantic segmentation is IoU. This is the same as the dice coefficient used as a loss function while training the model. Compared to object detection, the IoU in semantic segmentation becomes more granular, i.e. it is computed at a pixel level.

Just like object detection, IoU metric is computed for each of the classes to get a mean IoU score and can be monitored.
Another monitoring metric could be pixel accuracy, which calculates the ratio of correctly classified pixels vs the image’s total pixels.
accuracy = TP + TNTP + FP + TN + FN
This metric can sometimes be misleading while monitoring because of class imbalances that creep in overtime to input data.
Image Segmentation: Architectures, Losses, Datasets, and Frameworks
Instance segmentation
The monitoring metric of instance segmentation is quite similar to object detection. But here, we look for the IoU for masks instead of bounding boxes. IoU is computed pixel-wise in this scenario, unlike object detection.

Okay, we discussed cases where labels are available for monitoring models, what if labels aren’t available?
Yeah, you heard that right! Sometimes labels aren’t available, and they can’t be relied upon entirely. But why?
- Long latency between prediction and ground truth label data: there are fair chances that there is a long lag between incoming data to be predicted and their ground truth labels being available. An example could be: A faulty circuit produced today won’t be labeled until the production lot is taken upon inspection, and then data is passed on to the image labeling team. Which may take days or even weeks.
- Human labeling: in most cases, computer vision data labeling is a human activity that takes time and resources
- Model intervention: when the model is deployed, you are likely to take actions based on the model’s predictions, which could change the data coming to the system.
In these scenarios, the monitoring and intervention are done at the data ingestion stage by capturing changing data patterns and their statistical characteristics. Further on data drift, the concept is discussed in detail below. An additional read would be the article shared here.
Some tools that can be helpful here are Prometheus which helps to store time series like metrics. Grafana helps to visualize the data stored in Prometheus. Both are open-source tools that can be used for model parameter monitoring/tracking.
Data drift in computer vision-based applications
In production, it is likely that data drifts happen, which would, in turn, affect the model performance. A typical example can come in such a way that an object detection model trained on an outdoor background is suddenly fed with data from an indoor background. In this case, the model performance is likely to go down.


Data drift in computer vision-based applications | Source
In another example, a model trained only on images from a unique device is exposed to images from different environments. A classical situation would be medical imaging data sourced from different devices. In these scenarios, quantify the change in model performance with newer data.
A mechanism to address these types of data drift would help the longevity of deployed computer vision models. There are tools available to monitor these types of issues. Arthur is a drift detection tool that can identify if the model fails to generalize and prompts you to take corrective action. They ensure that the data coming into the deployed model looks as expected. In CV-based systems, this means the incoming data looks similar to the data on which the models were trained. Their algorithms are based on the out-of-distribution anomaly algorithm used in this paper.
The image below shows how the input data can vary across regions as well as with time.

Monitoring CV models for algorithmic bias
Just like any machine learning model, biases could also creep into computer vision systems as well.
According to tech target:
“Algorithm bias or AI bias is a phenomenon that occurs when an algorithm produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process”.

For example, it’s found that some of the facial recognition systems are biased towards faces with colour compared to white faces. This could be due to a lack of exposure to a balanced dataset. These biases are often unintentional, but they can create serious repercussions or even legal ramifications. To avoid such scenarios, data scientists should be well aware of the datasets, their source, diversity, etc. Data should represent different races, genders, and cultures that might be adversely affected.

Google search for “nurse” shows mostly female nurses.

Google search for doctors shows mostly male doctors.
The bias can arise from either of the scenarios:
- Algorithmic bias: as the name suggests, the problem lies with the machine learning algorithm.
- Sample bias: in this case, the training dataset may not be representative enough or large enough to give enough representation to the real sample space.
- Prejudice bias: in this case, the system reflects the existing prejudices/stereotypes in society. An example would be an existing gender stereotype illustrated above, such as female nurses and male doctors present in the training dataset.
- Measurement bias: this bias arises due to underlying problems with the accuracy of the data and how it was measured or assessed.
- Unbalanced classes: typical scenarios could include facial feature recognition algorithms mostly built on western white faces struggling to comprehend typical Asian facial features.
While we know there are many ways bias can creep even into the state of the art computer vision systems, awareness, and good governance can prevent this.
Some of the steps that can be adopted here to resolve these issues are:
- 1 Choosing adequately represented training data
- 2 Conduct separate algorithmic bias tests before model deployment
- 3 Actively monitoring biases as they emerge with changing input data
IBM’s AI fairness 360 is an open-source toolkit that can help you examine, report, and mitigate discrimination and bias in machine learning models throughout the AI application lifecycle.
Things to consider with CV model development & deployment
Computer vision and data quality
The quality of the training data is a crucial ingredient to make robust and efficient computer vision models. You can think about scenarios where bad data quality could lead to unwanted outcomes such as making expensive mistakes in manufacturing processes, mistakes created by self-driving systems, etc.

Another Challenge for AI developers is to transform massive amounts of data, for example, by creating video annotations. Depending on the frame rate, the annotations could be highly labor-intensive. A typical Autonomous driving system might need annotated images, videos, GPS data, IoT-sensor data, etc. Also, generating and storing these different data points could be tricky.
So how do we address these issues?
This works through a combination of people, process, and technology/tools.
People
Based on the size & budget of your organization, the annotation workforce could be a mix of employees, contractors, outsourced teams, crowdsourced persons, etc. Basic knowledge of the tools used and the targeted CV application with the workforce is necessary for generating high-quality datasets. Surprisingly, a large part of the project’s costs could solely lie on the data preparation side.
Process
The data annotation process could even evolve while you train, validate and test the computer vision models. Hence what is important here is the team should be agile. They should be able to adjust according to the data types, annotation types, tools used, etc.
Technology / tools
These solutions can be cloud-based, on-premise, or even developed in-house. It will be a good idea to develop in-house annotation tools if your model needs custom annotation types. Since most commercial annotation tools provide far more features than open-source tools, the most important decision here could be whether to build the tool in-house or buy it. Other factors that need to be considered are the usage of integrated platforms, data security, etc.
Deployment hardware
An effective computer vision deployment amalgamates hardware and underlying software. We often think only about on-premise hardware systems or cloud environments where the deployments are hosted. But a plethora of other applications include deployments happening on edge devices. Even if we can develop effective algorithms, some deployments could be on edge devices where you cannot access fast processors, let alone GPUs!. Some systems also integrate with other IoT devices, adding even more complexity.
An autonomous drone is a perfect candidate to discuss in this context, i.e. hardware requirement on an edge device. Several industries now rely on autonomous drones to accomplish more in a short time.
The image shown below represents how militaries around the world are using autonomous drones to carry out active surveillance. Many surveillance drones today are automated, Computer vision embedded on-edge machines.

A device such as a UAV (drone) needs to process videos streamed from the camera at a reasonable frame rate. As a processing tool, OpenCV or Tensorflow Lite would be good candidates. Another standing out example could be automated drones for deliveries. They use embedded vision which helps drones identify what they are “seeing”, like a drone can tell whether an object is static or moving.
The hardware/deployment architecture for a vision-based autonomous drone is nicely explained in this paper.


Other popular edge devices are based on Raspberry Pi. Raspberry Pi 4, Starting at just $35 for the 2GB RAM model, the Raspberry Pi 4 can serve as a media center, web server, or inference engine of an IoT device.
Vizy from Charmed Labs, which comes with a Raspberry Pi 4, is a smart device embedded with a hi-res camera for those starting with computer vision-based applications. Using the power of the Raspberry Pi 4 and a competent, high-quality camera, Vizy makes it easy for students or more advanced users to build computer vision projects or solutions.


Vizy is controlled via a web interface rather than a desktop application with an HTTPS interface from your browser. The online editor and Charmed Labs’ extensive documentation and API reference make it relatively easy to get started. The power board, a GPIO add-on board, has its API controls, such as onboard LEDs, fan controllers, IR remote controllers, etc.
Other interesting deployment applications include AGVs (automated guided vehicles) used primarily in warehouses/logistics applications. More recently called VGVs (Vision guided vehicles), they have evolved from their AGV counterparts. Unlike AGVs, they don’t need any magnetic stripes or reflectors. Since they are ground-based, unlike drones, they can afford heavier built-in hardware.
Bots used in Amazon Robotic fulfillment center is another classic example of computer vision model deployment with edge device computing capability. But again, they use a combination of computer vision, IoT, and sensor data to navigate and perform their intended duties.

The economics & viability of CV model development & deployment
A clear business objective is critical to deploying successful Computer Vision models. Such as:
- Is it improving production efficiency or profitability or improving sales volumes?
- Is it maximizing/minimizing the KPIs associated with the business objective?
- What estimated money value can the model deployment bring to your organization?
- Do the benefits outweigh the costs in the long run?
A cost-benefit analysis makes a lot of sense while building the team or choosing deployment tools. There are strengths and weaknesses associated with each tool. A costly cloud-native integrated platform could save a lot on training time & resources and data ETL costs, but at the same time, the subscription could be costly. A computer vision model development could develop additional tool overheads like specialized annotation tools compared to NLP or classic Machine learning model developments.
It’s important to note that close to 90% of ML models never make it to production; the same goes for Computer vision models. In many companies, some reasons behind this include we cannot ensure a model that works in a small environment works everywhere else, hindrances could come in the form of data unavailability, inadequate cloud storage, etc.
Estimating the volume and costs incurred for computing resources
For skilled AI developers coming up with an algorithm that works is no longer an issue. They already exist out there! The challenge often lies in the availability of computing resources. Leaders often underestimate the hardware needs, and costs incurred while using cloud services. This often results in spending most of their budget on algorithm development, but adequate training and testing fail to happen due to its estimated costs which often happen at a later stage.
How much does it cost to train an ML model?
Some ballpark list-price costs of training differently sized BERT NLP models from AI21 researchers are quoted below.
Two figures are mentioned side by side- the cost of one training run and a typical fully-loaded cost.
- $2.5k – $50k (110 million parameter model)
- $10k – $200k (340 million parameter model)
- $80k – $1.6m (1.5 billion parameter model)
Okay, you might think this is just for the NLP models?. Well then, have a look at the latest CNN architecture sizes!
The same goes there as well! So to get an idea of the incurred cost, it’s important to know the size of the deep learning models, training batch size, training epochs, and the expected number of experiments that need to be conducted to get a satisfactorily trained model.
Building and Deploying CV Models: Lessons Learned From Computer Vision Engineer
Cross-language and tools support issues
Many of the older computer vision models are built with open CV (primarily built with C++). Later, the rise of Python scripting led to widespread usage of Tools Such as Pytorch, Caffe, Tensorflow, etc. More recently, with the arrival of Tensorflow JS (Javascript based), CV is getting embedded into web apps and edge/mobile devices as well. That means you can bring your ML model into the front end too!. And now it’s the dawn of Julia!

Since each language comes with unique sets of libraries and dependencies (or even hardware), ML projects quickly get hard to build and maintain, not to mention our specialized computer vision models! Some pipelines use containerization with Docker and Kubernetes, and others might not. Some pipelines require employing specialized APIs, and others may not.
Some of the deployment tools, as discussed before, are capable of addressing these ever-evolving issues, but it still needs to mature compared to where the traditional software industry is now. This creates a unique problem, the need for full-stack, multi-language AI Engineers. People with such skill sets are hard to come by and even costlier to hire.
Summary
In the article, we touched upon various topics right from annotations, experimentation, UI, deployment platforms, monitoring, data/model validation, best practices, and so on. If carefully brought in with the right level of individual attention, all of them form the recipe for a successful ML model deployment.
MLOps is a renowned term used in the ML world. But it would be great if we could start using the term CVOps for deployment activities pertaining to a Computer vision model. Who knows, this might well become a common term in the future!
If you have not been following these steps, I would say try them out!. Even if it’s a small (proof of concept) PoC or a scalable, high-performance deployment, the practices mentioned above are valuable.
This article is not the end of the road so keep learning!
References
- Building and deploying an object detection computer vision application at the edge with AWS Panorama
- Google cloud Vision AI
- Best MLOps tools for your computer vision project pipeline
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- WILDS: a benchmark of in-the-wild distribution shifts
- Deploying deep learning models using Kubeflow on Azure
- A guide to data collection for computer vision in 2022
- Building a Python scalable Flask application using docker-compose and Nginx load balancer
- Arthur.AI
- Machine learning bias (AI bias)
- When AI meets store layout design: a review
- AI & machine vision based automated weld defect detection for manufacturing industry
- Python and REST APIs: interacting with web services
