
In this article, I have documented the best practices and approaches to build a productive Machine Learning team that creates positive business impact and generates economic value within corporate entities, be it startup or enterprise.
If you do Machine Learning, either as an individual contributor or team manager, I’ll help you understand your current team structure and how to improve internal processes, systems and culture. We’ll explore how to build truly disruptive ML teams that drive successful outcomes.
Why build an ML team?
Artificial Intelligence (AI) is predicted to create global economic value of nearly USD 13 Trillion by 2030 [1]. Most companies across diverse industries and sectors have realized the potential value of AI, and are well on the way to becoming an AI-first entity. From tech companies building cutting-edge AI products like self-driving cars or smart speakers, to traditional enterprises leveraging AI for non-glamorous use cases like fraud detection or customer service automation, the potential of AI to deliver commercial impact is beyond doubt.
The adoption of AI in industry is accelerated by a number of trends:
- Exponentially growing amount of data from internet-enabled devices, sensors, web platforms and so on, combined with drop in costs of storing, accessing and sharing data.
- Cheaper computational costs of training AI models with the advent of GPU and cloud.
- Innovation in algorithmic research and deep learning models that build upon the foundations of data and compute.
Given this paradigm shift in the last decade, the cost of building AI products and services has come down substantially. The door is now open for a diverse variety of players like enterprises, startups, entrepreneurs, students or hobbyists to innovate and create transformational AI.
In the following section, I will describe the challenges in building Machine Learning teams for startups and enterprises respectively.
Challenges for startups
Startups, in the early stages of operations, are typically bootstrapped and have limited budgets to deploy for building machine learning teams.
If your startup has a core product or service founded on AI, then it’s imperative to hire machine learning talent early on to build the MVP, and raise funding to hire more talent and scale the product.
On the other hand, for startups whose core product or service is focused on other domains like finance, healthcare or education, AI will either be incidental to the core operations, or not essential until product-market fit is achieved.
The main challenges of building ML teams in startups are:
- Limited funding or budget for AI.
- Scarce availability of training data to build machine learning models.
- Lack of labelled data or funds to outsource labeling to third-party vendors.
- No structured data warehousing, data pipelines or machine learning deployment infrastructure.
- Require more hands-on machine learning talent that can operate across the entire machine learning lifecycle – from data engineering, algorithmic and model development to deploying and monitoring machine learning models in production instead of specialized talent to focus individually on the various aspects of the machine learning lifecycle.
- Cannot hire the best machine learning talent in the market and match salaries offered by leading technology companies.
- To compete with established players, faster machine learning development cycles are imperative. However, this can often lead to friction and inefficiencies in the absence of structured internal processes and management.
In the face of such daunting challenges of machine learning work combined with general organizational challenges at startups [2], it becomes even more important for startups to hire and build the right machine learning team from the very beginning.
Challenges for enterprise
Unlike startups, big organizations and enterprises don’t suffer from lack of funding or budget to seed a machine learning team. The challenges in an enterprise are unique from one entity to another, but generally arise due to the size of the organization, internal bureaucracy and slower decision making processes – things that tend to benefit startups and help them ship products faster.
Although today, it might appear that technology companies are ubiquitous, they’re still a minority compared to the vast number of traditional enterprises focused on diverse sectors like finance, FMCG, retail, healthcare, education and so on. Technology companies have a headstart when it comes to machine learning and AI, and their strong early focus and investment in AI R&D will ensure their dominance compared to their traditional counterparts.
However, there are numerous challenges that traditional enterprises face in adopting and onboarding AI across the organization [3], which more often than not result in failed AI projects and reduced trust in the capacity and potential of AI [4]:
- Inability to develop a roadmap and vision for using AI to solve business challenges.
- Obstacles in facilitating cross-functional and interdisciplinary collaboration to define valid AI use cases with well-defined KPIs.
- Slow decision-making processes that are not founded on data but instinct and gut.
- Risk-averse cultural mindset that is not conducive to building digital-first organizations.
- Typical AI use cases are domain-agnostic that impact every aspect of the organization e.g. customer service automation, which do not excite or attract most data scientists.
- View AI from a cost-saving perspective rather than a potential revenue-generating stream.
- Inability to mobilize internal teams quickly to build a new AI product or enter a new market that has been validated by fast-moving startups.
Having detailed the core challenges faced by startups and enterprise, in the next section, I will describe the composition of a typical machine learning team and the skills and tools used by various profiles who work across the machine learning lifecycle. A better understanding of the skills and abilities of diverse machine learning teams is essential for hiring managers and teams to build out a complete and productive machine learning team.
Profiles in a machine learning team
Modern machine learning teams are truly diverse. Yet, at the core, they involve candidates who have strong analytical skills and the ability to understand data from different domains, train and deploy predictive models, and derive business or product insights from the same.

As in Figure 1, the machine learning lifecycle has four stages that feed into each other sequentially. Each of these stages is a specialized domain, based on specific knowledge and skillset to execute the associated tasks well.
Scoping
The first stage of scoping out an AI use case requires AI experts along with business or domain experts. Plenty of successful AI projects start with a deep understanding of the potential business problems that can be solved with AI, and require the combined intuition and understanding of seasoned technical and business experts. In this stage, the usual collaborators involve business leaders, product managers, AI team managers and perhaps one or more senior data scientists with deep, hands-on experience with the underlying data.
Data
The second stage is focused on acquiring data, cleaning, processing from the raw form to structured format and storing it in specific on-premise databases or cloud repositories. In this stage, the role of the data engineer is prominent, alongside data scientists. The business and product managers serve a helpful role in providing access to the data, metadata and any preliminary business insights based on rudimentary analytics.
Modeling
The third stage involves core data science and machine learning modeling using the datasets prepared in the previous stage. In this stage data scientists, applied or research scientists are predominant in training initial models, refining them based on test set performance and feedback from cross-functional stakeholders, developing new algorithms if needed, and finally producing one or more candidate models that meet the required accuracy and latency benchmarks to take the models to production.
Deployment
The final stage of the machine learning lifecycle is focused on deploying trained models to production, where they serve predictions from the inputs received from end users. In this stage, machine learning engineers take the models developed by the data/applied/research scientists and prepare them for production. If the models meet the predefined accuracy and latency benchmarks, the models are good to go live. Otherwise, ML engineers work on optimizing the model size, performance, latency and throughput. Models go through systematic A/B testing procedures before deciding which version(s) of the models are best suited for deployment.
Next, I prepared detailed profiles for the different types of experts you may need for your ML team.
Data Engineer
Skills
- Database
- Programming
- Querying languages
- Data Pipelines
- Architecture
- Analytics
- Data manipulation, transformation and preprocessing
- Cloud services
- Workflow management
Responsibilities
- Build data pipelines, architectures and infrastructure
- Clean and process datasets for data science modeling
- Build internal tools to optimize data engineering workflow
- Aggregate disparate datasets for defined use cases
- Support data scientists with data related requirements
Tech stack
- SQL, MySQL
- Java
- Python
- C++
- Scala
- Spark
- Hadoop
- Kafka
- Databases: Postgres, MongoDB, Cassandra, Redis, Hive, Storm
- Cloud: AWS/Azure/GCP, EC2, EMR, RDS, Redshift
Data Scientist
Skills
- Problem solving
- Programming
- Statistics
- Data Analytics
- Data Visualization
- Data Science
- Supervised machine learning
- Unsupervised machine learning
- Written and verbal communication to work with cross-functional teams
- Presentation skills to present results and insights to leadership
- Derive statistically valid insights from data science models to improve product development, marketing or business strategies
Responsibilities
- Identify and validate business use cases that can be solved with AI
- Analyze and visualize data at different stages of the modeling pipeline
- Develop custom algorithms and data science models
- Identify additional datasets or generate synthetic data
- Develop data annotation strategies and validate the same
- Coordinate with cross-functional teams to seek feedback on models, share results and implement models
- Develop custom tools or libraries to optimize the entire data science modeling workflow
Tech stack
- Python
- R
- Java
- Jupyter notebooks
- Visualization: Matplotlib, Seaborn, Bokeh, Plotly etc.
- SQL
- Spark
- Git, Github/Bitbucket
- Cloud: AWS/Azure/GCP; SageMaker, S3, Boto
- Machine learning: Scikit-learn, Fast.ai, AllenNLP, OpenCV, HuggingFace
- Deep learning: TensorFlow, PyTorch, MXNet, JAX, Chainer etc.
- Hyperparameter tuning: Neptune, Comet, Weights & Biases
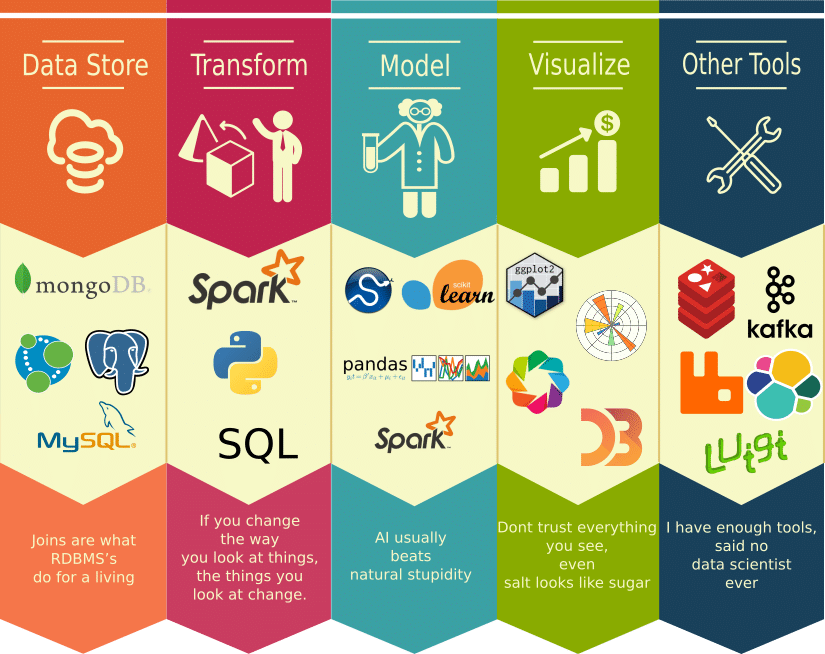
Machine Learning Engineer
Skills
- Data structures
- Data modeling
- Programming
- Software engineering
- ML frameworks like TensorFlow, PyTorch, Scikit-learn etc.
- Statistics
- Conceptual knowledge of ML to understand use cases and interact with data scientists and other stakeholders
Responsibilities
- Deploy models to production
- Optimize models for better latency and throughput
- A/B testing of candidate models
- Inference testing on variety of hardware: edge, CPU, GPU
- Monitoring model performance, maintenance, debugging
- Maintaining model versions, experiments and metadata
Tech stack
- Linux
- Cloud: AWS/Azure/GCP; SageMaker, S3, EC2, Boto
- Machine learning: Scikit-learn, Fast.ai, AllenNLP, OpenCV, HuggingFace
- Deep learning: TensorFlow, PyTorch, MXNet, JAX, Chainer etc.
- Serving: TensorFlow Serving, TensorRT, TorchServe, MXNet Model Server
- Python
- C++
- Scala
- Bash
- Git, Github/Bitbucket
Research Scientist
Skills
- PhD in a quantitative discipline like Computer Science, AI, Physics, Biology, Economics etc.
- Scientific mindset and first-principles thinking
- Depth and breadth of state-of-the-art approaches in science
- Prior experience in conducting academic or industry research
- Creative problem solving
- Machine Learning
- Deep Learning
- Design and develop ML prototypes and models
- Written and verbal communication to work with cross-functional teams
- Presentation skills to present results and insights to leadership
- Derive statistically valid insights from data science models to improve product development, marketing or business strategies
Responsibilities
- Conduct research for novel ML use cases and applications
- Build initial ML prototypes and models
- Conduct systematic experiments across multiple models and hyperparameter combinations
- Create or augment datasets
- Clean, process, analyze and visualize data and model performance
- Keep up-to-date with new research literature and state-of-the-art machine learning and deep learning approaches
- Evangelize new ML approaches and ideas
- Mentor software, data and ML engineers
Tech stack
- Python
- Jupyter notebooks
- Machine learning: Scikit-learn, Fast.ai, AllenNLP, OpenCV, HuggingFace
- Deep learning: TensorFlow, PyTorch, MXNet, JAX, Chainer etc.
- Linux
- Cloud: AWS/Azure/GCP; SageMaker, S3, EC2, Boto
- Hyperparameter tuning: Neptune, Comet, Weights & Biases
- Git, Github/Bitbucket
Product Manager + Business Leader
Skills
- Product design, marketing
- Data analytics
- Subject matter expertise in one or more domains
- Program management
- Business development
- Understanding of product roadmaps and end to end project delivery
- Understanding of software, architecture, data and machine learning best practices
- Basic knowledge of fundamental machine learning concepts, process, metrics and deployment
- Excellent written and verbal communication skills to work across customers, business and technical teams
- Interpersonal skills including persuasion and getting work done from stakeholder teams
- Awareness of distinction between managing and building machine learning vs. software products
Responsibilities
- Create detailed product, feature roadmaps with milestones, deliverables, metrics and business impact
- Conduct surveys with customers of the proposed products to streamline design, UX and reduce friction
- Balance multiple priorities from stakeholders, customers to define and deliver the product
- Work with software engineering and machine learning teams to iterate and improve models as per the roadmap
- Take ownership of the product and ensure delivery of features and the entire product under tight deadlines
Tech stack
- SQL to pull and analyze data to build intuition for the product
- Excel
- Work management tools
- Productivity tools
- Scheduling tools
Data Science / Machine Learning Manager
Skills
- Complete understanding of machine learning lifecycle from conception to production
- Written and verbal communication skills
- Interpersonal and persuasion skills to get buy-in from leaders, work with cross-functional teams
- Vision to create and collaborate on product features and roadmap with product and business managers
- Practical and theoretical understanding of machine learning and deep learning concepts, deployment and continual improvement of ML products
- Mentorship to individual machine learning contributors
- Program management alongside product and project managers
Responsibilities
- Own machine learning products and roadmap
- Create vision for novel machine learning products
- Align stakeholders towards proposed product vision
- Understanding of machine learning metrics vs. business metrics
- Evangelize capabilities and successes of machine learning team within the company as well as in the wider ecosystem
- Hire machine learning talent who specialize across the machine learning lifecycle
- Collaborate and dive deep with product and business teams to identify potential use cases that can be solved with machine learning
- Understand how the business and its products and services work from the point of view of the customer
- Understand the business revenue streams and come up with original ideas for machine learning projects that improve the product or service, reduce costs, and automate manual processes
Tech stack
- Python
- SQL
- Excel
- Productivity, collaboration and communication tools

MLOps Checklist – 10 Best Practices for a Successful Model Deployment
Building productive and impactful machine learning teams
We explored the typical composition of a Machine Learning team, which includes a variety of different profiles specialized in specific aspects of building machine learning projects. However, the reality on the ground is that having a solid machine learning team is not a guarantee that the team will create and deliver massive business impact. The reality on the ground is that the vast majority of corporate AI projects fail, and a lot of these projects fail despite having a great machine learning team.
In this section, I will dive deeper into the cultural, procedural and collaborative aspects of building impactful machine learning teams from first-principles. The success of a machine learning team is founded on several factors related to systems, processes, and culture. When built the wrong way, this will inevitably lead to failed projects and erosion of trust and confidence in the team, as well as machine learning as a business capability and competitive edge.

1. Working on the right AI use cases
For a brand new machine learning team to deliver impact in an organization, it’s paramount that the team starts off on the right foot. Early traction is critical to build trust in the organization, evangelize the potential of AI across business verticals, and leverage early successes to deliver riskier or moonshot projects with greater impact.
Following is a list of do’s and don’ts for brainstorming and defining the right set of AI use cases.

2. Planning for success – measuring impact
As part of the process of selecting and defining the right AI use cases, it’s fundamental to critically assess and evaluate the business impact and return on the investment in the particular machine learning project. The best approach for evaluation is by defining a set of metrics that address several aspects of the project and its potential impact.
Technical metrics
For classification models:
- Accuracy
- Precision
- Recall
- F1 score
- AUC
For regression models:
- Root mean squared error
- Adjusted R2
- Mean absolute error
For deep learning models (depends on the particular application):
- Perplexity, cosine similarity, Jaccard similarity, BLEU (NLP)
- Word Error Rate (speech recognition)
- Intersection Over Union, Average Precision, Mean average precision (computer vision)
Business metrics
Business metrics are defined by first-principles, and are often downstream metrics that are impacted by the machine learning models. For measuring outcomes, it’s crucial to a priori identify the relevant business metrics and track the effect of the machine learning models on the same during A/B testing, deployment, and continuously monitor live models.
Standard business metrics aim to capture levels of trust, satisfaction, faults, and SLAs, among others.
Once a candidate set of machine learning projects is scoped, defined and formulated from conception to production with associated set of metrics, each project needs to be evaluated by leadership teams from the perspective of high-level organizational goals to be achieved in a defined time period. Leaders need to balance the business impact (on the opline or bottomline), budget, team bandwidth, time savings, efficiency savings, and the urgency for delivering projects in the short-term vs. the long term. Executives need to incorporate multiple factors to arrive at a carefully considered decision to give the green signal for one or more machine learning projects.
3. Structured processes – Agile, Sprints
Once a project is defined and has the go ahead from the leadership team, it is important to ensure that systems and structured processes are in place to ensure that the machine learning team can work unhindered and execute the project in a timely fashion as per the agreed plan.
Key operational infrastructure like data warehouse, database management systems, data ETL pipelines, metadata storage and management platforms, data annotation frameworks and availability of labeled data, access to compute on-prem or in the cloud, licensed as well as open source tools and softwares that streamline the model training process, machine learning experiment, results and metadata management tools, A/B testing platforms, model deployment infrastructure and solutions, continuous model monitoring and dashboards are integral for a smooth data processing, model building, and deployment workflow. However, the existence of such key skeletal infrastructure for machine learning varies from one organization to another depending on how mature the machine learning organization or the company is.
Apart from the infrastructure, processes related to planning tasks of the individual contributors of the project using sprints and agile frameworks need to be hardwired and accessible to all stakeholders of the project. While Agile processes have worked well for software projects, machine learning projects are different and may not be that well suited to the same frameworks. Although similarities like iterative model building and refining based on feedback exist, machine learning projects are more sophisticated, as the fundamental blocks include data and models in addition to code.
While software engineering best practices like code review and versioning are very well established, the same rigor and structure is not always applied to data and machine learning models. Documentation is another aspect that is even more critical to keep track of multiple hypotheses, experiments, results and all the moving parts associated with machine learning projects.
In the absence of well entrenched tools and best practices, most data science work tends to be highly inefficient where data scientists end up spending a lot of time on routine chores that can be automated. It’s imperative that managers try to reduce such barriers to more efficient and productive work, so that the machine learning teams can focus exclusively on their work.

4. Clear communication within and across teams
Communication is an essential skill for data scientists. Machine learning is a more intricate discipline and the end results might often be too obscure for generalist and non-technical managers of data science, product or business teams to comprehend easily. However, communication is just the tip of the iceberg, and many more interpersonal skills like persuasion, empathy, collaboration are exercised on a regular basis whilst working in cross-functional teams.
Writing emails of results or updates or slide presentations to stakeholders and leadership, live demos, expounding the project for product review documents, writing up the entire project for a blog meant for lay audience or for a journal or conference meant for a technical audience, requires strong writing skills. Typical data scientists may be more proficient in writing code than words, so the organization should invest in corporate training programs for data scientists that include training in written and spoken communication skills.
Oral communication skills can’t be underestimated either, and are increasingly important in remote-first organizations. Effective stakeholder management involves building rapport and trust and establishing clear channels of communication, which is much harder to do if a data scientist is not able to speak and communicate clearly in an engaging and delightful manner. Although a lot of workplace productivity apps have created digital channels of reduced in-person communication, the power of live in-person communication with peers, stakeholders and leaders often gets the job done faster.
Clear communication destroys information silos, so that each stakeholder is aware, updated and aligned with the progress of various machine learning projects. Regular meetings are important to have checks and balances, in addition to documented progress in tools to ensure that projects are moving in the right direction.
5. Effective collaboration with business
Machine learning teams are typically part of the engineering or technology organizations in a company. While this makes natural sense for effective collaboration across colleagues from data, analytics, engineering functions, regular interaction with business teams is a must. Given the fact that most machine learning models are built on historical ‘business’ data that can change in a predictable manner due to new product or feature launches or seasonality patterns, as well as in an unpredictable manner, for instance, during Covid-19 lockdowns, machine learning teams must have a real-time awareness of how the business data is changing on the ground.
Not only is it important to adjust the underlying hypotheses in the face of massive changes in customer behavior or new product launches, but also to correct the planned course of action if initial assumptions are violated or the data changes too dramatically for the machine learning models to be relevant or have the same impact as before.
Business teams are in the best position to give feedback on early prototypes based on their domain expertise, validate new assumptions or ideas by doing customer research and surveys, and evaluating the impact of deployed machine learning models. For these reasons, the partnership between machine learning and business teams needs to be mutually beneficial and symbiotic.
Leaders of machine learning teams need to build close ties with business teams and encourage team members to do the same.
Aside
Explain how your model works, monitor performance over time, visualize your findings, discuss bugs, and showcase the progress made.
-

Check the documentation
-
Play with an interactive example project
-
Get in touch if you’d like to go through a custom demo with our product team


6. Creating a culture of innovation
For long-term success of machine learning teams, apart from working on the right use cases and facilitating collaborative work across the organization, it’s imperative to build a culture that embraces and rewards innovation. Here, leadership should lead by example and encourage innovation and R&D across different business verticals.
For a machine learning team, it’s critical to make a mark in the ecosystem through patent applications, journal or conference publications, outreach and dissemination via meetups, workshops, seminars by leading experts, collaboration with startups and academic organizations as needed, and so on. Most organizations don’t focus on building such a thriving culture that promotes exchange and cross-fertilization of new ideas and technologies, which can often impact current organizational processes and thinking in a substantial way.
Leaders also need to build strong diverse teams and hire new talent, from entry level graduates to experienced engineers and scientists. The inflow of new talent brings in novel ideas that can positively impact the work culture. Otherwise stasis sets in, teams can become narrow-minded, and decline in their capacity to innovate and launch impactful products. Meritocratic executive decisions strongly impact culture, both in terms of promoting talent that demonstrates a consistent track record of exceptional bar-raising work, as well as letting go of non-performing individuals or managers. The appropriate balance and culture in a team is an ongoing process, but it’s important for leaders to ensure that at no point in time, the members of a machine learning team are unmotivated and uninspired by the systems, processes, and culture within the organization.
7. Celebrating and sharing AI success stories
Finally, given the low odds of success for AI projects at present, it’s important to make sure that any AI success stories are widely shared within the organization to attract the attention of other business teams who could potentially partner with the machine learning team. Furthermore, given the immense popularity of AI as a discipline, success stories might also attract potential new team members from within the company who feel motivated to upskill in machine learning and become a data scientist.
It’s important to recognize the effort of the core contributors to the success of AI projects in a public manner within the company and not behind closed doors. It helps to build morale and confidence and foster a meritocratic culture within the team that will help them in their career development. Additionally, wherever possible, the leadership should take steps to share such AI success stories widely within the broader ecosystem in which the company operates, for instance, via company blogs, social media posts, podcasts or talks at meetups, workshops or conferences.
For a machine learning team to continue to deliver strong performance and results, it’s critical to build a portfolio of successful projects starting from simpler ones to gradually more sophisticated ones with an ever increasing scope and commercial impact. The success of a machine learning team acts as a trigger and accelerates the digital and AI transformation of a company. In the highly competitive digital economy, companies that have invested early and invested a lot in AI have emerged as the early winners, for instance, the big tech companies. Thus, impactful machine learning teams act as a lever in the journey towards embracing and onboarding AI and transforming the company into a forward-looking, data-driven, AI-first company.
