
A successful machine learning project isn’t just about deploying a working app. It’s about delivering positive business value and making sure that you keep delivering it.
When you work on a lot of machine learning projects, you find that some of them work well during development but never reach production. Other projects make it to production but can’t scale to meet user demand. Yet another project will be too expensive to generate profit after it’s scaled up.

Conventional software has DevOps, we have MLOps, which is even more important. If you want to succeed, you need an optimal MLOps architecture for your development and production workloads.
The image below might be the most common diagram in the whole MLOps community, and it comes from one of the most referenced ML papers.

The diagram tells us that there’s more to production-grade machine learning systems than designing learning algorithms and writing code. Being able to select and design the most optimal architecture for your project is often what bridges the gap between machine learning and operations, and ultimately what pays for the hidden technical debt in your ML system.
In this article, you will learn:
Somewhere in the article, I also give you the challenge to come up with the best architecture given a business question/problem. I hope you have fun, let’s get right into the article!
MLOps Checklist – 10 Best Practices for a Successful Model Deployment
The reality of production-grade Machine Learning systems
When you think of working on a machine learning project, a very detailed workflow for you may be:

In fact, you might have already developed your model with a workflow like this, and want to deploy your model and prepare it for production challenges, like deterioration, scalability, speed, maintenance, and so on.
If you’re thinking of life beyond experimentation and development, you might have to do a thorough re-think—and that starts with choosing the right architecture to operationalize your solution in the wild.
To operationalize a machine learning system at a general level requires a complex architecture—or so it goes in the famous “Hidden Technical Debt in Machine Learning Systems” paper.
For a machine learning project that serves users in real-time, what do you think the architecture should look like? What will you consider? What should you account for?
Below is an illustration of the added complexities you may discover when looking for the right architecture for your project (even though it’s a lot, it still doesn’t take into account everything needed to build a production-grade machine learning system that delivers continuous value).

That’s quite a lot of considerations! As you can see, there’s a machine learning (ML) section of the system and an operations (Ops) section of the system. Together, they both define the architecture of a machine learning system.
In common architectural patterns for MLOps, architectural changes occur at the ML stage as well as the Ops stage, where you can have various development and deployment patterns that depend on the problem and the data. In the next section, we’ll take a look at the common MLOps architectural patterns for ML systems.
Common architectural patterns for MLOps
As you saw in the (fairly) complex representation of a machine learning system above, MLOps is simply machine learning and operations mixed together and running on top of infrastructure and resources.
The architectural patterns in MLOps are about the training and serving design. The data pipeline architectures are often tightly coupled with the training and serving architectures.
Machine Learning dev/training architectural pattern
In your training and experimentation phase, architectural decisions are often based on the type of input data you’re receiving and the problem you’re solving.
For example, if the input data changes often in production, you might want to consider a dynamic training architecture. If the input data changes rarely, you might want to consider a static training architecture.
Dynamic training architecture
In this case, you constantly refresh your model by retraining it on the always-changing data distribution in production. There are 3 different architectures that are based on the input received and the overall problem scope.
1. Event-based training architecture (push-based)

Training architecture for event-based scenarios where an action (such as streaming data into a data warehouse) causes a trigger component to turn on either:
- A workflow orchestration tool (helps orchestrate the workflow and interaction between the data warehouse, data pipeline, and features written out to a storage or processing pipeline),
- Or a message broker (serves as the middle-man to help coordinate processes between the data job and the training job).
You may need this if you want your system to continuously train on real-time data ingestion from an IoT device for stream analytics or online serving.
2. Orchestrated pull-based training architecture

Training architecture for scenarios where you have to retrain your model at scheduled intervals. Your data is waiting in the warehouse and a workflow orchestration tool is used to schedule the extraction and processing, as well as the retraining of the model on fresh data. This architecture is particularly useful for problems where users don’t need real-time scoring, like a content recommendation engine (for songs or articles) that serves pre-computed model recommendations when users log into their accounts.
3. Message-based training architecture

This sort of training architecture is useful when you need continuous model training. For example:
- new data arrives from different sources (like mobile app, web interaction, and/or other data stores),
- the data service subscribes to the message broker so that when data comes into the data warehouse, it pushes a message to the message broker,
- the message broker sends a message to the data pipeline to extract data from the warehouse.
Once the transformation is over and data is loaded to storage, a message is pushed to the broker again to send a message to the training pipeline to load data from the data storage and kick off a training job.
Essentially, it joins the data service (data pipeline) and the training service (training pipeline) into a single system, so that training is continuous across each job. You may need this training architecture, for example, when you need to refresh your model on real-time transactions (fraud detection applications).
You can also have a user-triggered training architecture, where a user sends a request to the training pipeline service to begin training on available data and write out the model data, perhaps the training report as well.
Static training architecture
Consider this architecture for problems where your data distribution doesn’t change much from what it was trained on offline. An example of a problem like this could be a loan approval system, where the attributes needed to decide whether to approve or deny a loan undergo gradual distribution change, and a sudden change only in rare cases like a pandemic.
Below is how a reference architecture for static training looks like—train once, retrain occasionally.

Serving architecture
Your serving architecture has a lot of variety. To successfully operationalize the model in production, it goes beyond just serving. You have to also be monitoring, governing, and managing them in the production environment. Your serving architecture may vary, but it should always take into account these aspects.
The serving architecture you choose will depend on the business context and the requirements you come up with.
Common operations architecture patterns
Batch architectural patterns
This is arguably the simplest architecture to use to serve your validated model in production. Basically, your model makes predictions offline and puts them in a data storage that can be served on-demand.
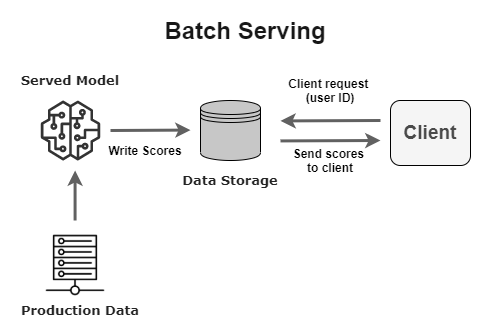
You might want to use this sort of serving pattern if the requirement doesn’t involve serving predictions to clients in seconds or minutes. A typical use case will be a content recommendation system (pre-computing recommendations for a user before they sign into their account or open an application).
Online/real-time architectural patterns
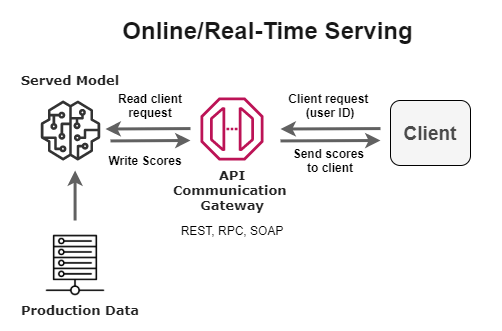
There are scenarios when you want to serve model predictions to users with very minimal delay (within a few seconds or minutes). You may want to consider an online serving architecture that’s meant to serve predictions to users in real-time, as they request them.
An example of a use case that fits this profile is detecting fraud during a transaction before it goes through complete processing.
Other architectures worth your time are:
- Near real-time serving architecture – useful for personalization use cases.
- Embedded serving architecture – for use cases where data and/or compute must stay on-premise or on an edge device (like a mobile phone or micro-controller).
Now that you’ve seen common MLOPs architectural patterns, let’s go ahead and implement one!
How to select the “best” MLOps architecture for the project
Like any other product or solution, you want to architect, coming up with the right design is very much problem-specific. You will often find that similar problems may have only slight variations in their architecture. So, “best” can be very subjective, and I want to make it very clear in this article. What I define as the “best” architecture is one that;
- Is designed around the needs of the end-user.
- Takes into account the necessary project requirements needed for the business success of the project.
- Follows template best practices, principles, methodologies, and techniques; for best practices and design principles, I referenced the Machine Learning Lens – AWS Well-Architected Framework practices, seemingly the most generalizable template so far.
- Is implemented with robust tooling and technologies.
You will also find that some of these may or may not apply to you based on your MLOps maturity level, driving even more subjectivity in the choice of architecture. Regardless, I tried to give full details on the project including the MLOps maturity level, taking the cost of running the system into account as well.
To keep things consistent, our project use case takes into account the four pillars of MLOps:
- Production model deployment,
- Production model monitoring,
- Model governance in production,
- Model lifecycle management (retraining, remodeling, automated pipelines).
To show you how to think about these architectures, I follow the same template:
- Problem analysis: What’s the objective? What’s the business about? Current situation? Proposed ML solution? Is Data available for the project?
- Requirements consideration: What are the requirements and specifications needed for a successful project run? The requirement is what we want the entire application to do and the specifications, in this case, is how we want the application to do it—in terms of data, experiment, and production model management.
- Defining system structure: Defining the architecture backbone/structure through methodologies.
- Deciding implementation: Filling up the structure with recommended robust tools and technologies.
- Deliberating on why such architecture is “best” using the AWS Well-Architected Framework (Machine Learning Lens) practices.
Adapting good design principles from AWS well-architected framework (Machine Learning Lens)
We adopt the 5 pillars of a well-architected solution developed by AWS. They help build solutions with optimal business value using a standard framework of good design principles and best practices:
- Operational Excellence: Focuses on the ability to operationalize your models in production, monitor, and gain insights into ML systems to deliver business value and to continually improve supporting processes and procedures.
- Security: Focuses on the ability to protect information, systems, and assets (data) while delivering business value through risk assessments and mitigation strategies.
- Reliability: Focuses on the ability of a system to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues.
- Performance Efficiency: Focuses on the efficient use of computing resources to meet requirements and how to maintain that efficiency as demand changes and technologies evolve.
- Cost Optimization: Focuses on the ability to build and operate cost-aware ML systems that achieve business outcomes and minimize costs, thus allowing your business to maximize its return on investment.
Well-architected framework architecture design principles for Machine Learning summary
I have created a summary table for you based on the design principles of these 5 pillars you should take note of when planning your architecture:
|
Well-Architected Pillar
|
Design Principles for ML Systems
|
|
Operational Excellence |
– Establish cross-functional teams. |
|
Security |
– Restrict Access to ML systems. |
|
Reliability |
– Manage changes to model inputs through automation. |
|
Performance Efficiency |
– Optimize compute for your ML workload. |
|
Cost Optimization |
– Use managed services to reduce cost of ownership. |
Best MLOps architectures on a defined project
We’ve selected a project below where we can think through the process of selecting an architecture for each of the projects. Here it goes!
Project: news article recommendation system

Content recommendation systems help businesses keep users engaged with relevant content to make them spend more on a platform. Especially in media, where the goal has always been to increase customer engagement.
Scenario
A business analyst in our company, a news article recommendation company, realized that there’s been a lot of customer churn lately. After analyzing the situation, they concluded that users don’t feel engaged with the platform, so they either don’t keep their subscription or just move on to other media platforms. We’ve worked closely with the business analysis team and some loyal customers, and saw that until we can personalize the platform for users, we might keep seeing them completely disengage or even worse, completely churn.
The first step to this is to build a feature that will integrate with the existing product that will recommend news articles the readers are likely to read when they log in and send them to their emails.
The management agrees on the condition that we build the system and test on a select number of users before increasing the scope.
… and that’s how we got here. What do we do now? Well, let’s start architecting!
Problem Analysis
Business understanding
- The business currently has over 521,000 paying customers in 3 regions (Latin America, Africa, and Northern America).
- They curate articles from various publications to serve their paid subscribers.
- When a user first visits the platform and activates a free trial, they’re prompted to select relevant categories of articles they’re interested in. They get served the latest articles in that category and data is collected on their interaction with the article and how long they stay on a page on the application or website.
What’s the business goal? To improve subscriber engagement by recommending the most relevant articles for any given login session to them so they can keep coming back and in turn stay subscribed to the service.
What’s the business metric? An increase in the number of minutes a user spends on an article. The reason we used this metric over clicks is simply that there are a lot more external factors outside of the system that can affect whether or not a user clicks on an article. From the headline to the cover photo, or sub-headline, to the UI design, and so on.
What’s the scope of the project?
- The project scope is low risk, mostly because there’s a template out there that can be adopted.
- It’s an externally-facing project where the experience of the users will be directly impacted.
- We’re only building the project and testing with a select number of users around ~15,000 for now, so the business can properly control the project and manage the impact.
- The business stakeholders have also requested that we run the entire system on-premise as we’re testing it out on ~15,000 users, and when a final report comes back on what running the entire project cost, we can have a more definitive discussion on this.
- Sometimes articles propagate misinformation and propaganda, so we should watch out for this while managing the system.
Technical considerations
- Team: We’re currently a team of two; myself and a data engineer which is pretty okay for this scope—we have to find ways to make operations less stressful for each of us! We also have access to the organization’s Ops team already deploying applications and internal systems on Kubernetes clusters both for our on-premise systems and private cloud platform.
- Hardware/Infrastructure Provision: We’ve been provisioning our own resources on-premise to run the project. We’ve also been given a free pass to choose our tools—this might not be the case for you, especially if your Ops team has existing tools.
Data understanding
- The historical data available includes the content details of the article, the content category, time the user spent on a particular article, the unique identifier of the user, the total number of times they visited an article;
- ~144,000 new articles are expected per day from various publications;
- The articles come with links, categories, release date, publication name, and other metadata.
Requirements consideration
When considering the requirements for your system, you want to understand a couple of things:
- What will ensure a good user experience? Remember, the user could be an actual person, or a consumer (downstream service) such as a backend service.
- What parts of the solution are the most critical to implement for a good user experience?
- What is the minimum valuable product we can implement as soon as possible to get the first version to our users and collect feedback?
For coming up with the requirements for your project, you can adapt this requirements specification template from Volere for your needs. For my requirements, I used questions from this checklist on GitHub curated by Michael Perlin.
Requirement: The service should recommend the top 10 articles a user is likely to read based on their interest for a given log-in session through the mobile application or the website homepage.
We can now take a closer look at the specifications for each component of the ML system.
Data acquisition and feature management specifications
- Since the articles are acquired from a variety of sources, it makes sense to centralize the data access into a data warehouse so we can easily ingest the production data into a data pipeline.
- We will need a feature store to store the transformed feature values extracted from the production data for retraining the machine learning model offline.
- Data versioning should also be enabled so we can properly trace the data lineage for auditing, debugging, or other purposes.
- We should also monitor the quality of the data so that it’s what our automated workflow expects.
Experiment management and model development specifications
- Training should happen offline with existing data on users and their interaction with previous articles.
- We’ll need a dynamic training architecture to compensate for the freshness in the articles released to avoid a stale model and ultimately stale recommendations.
- We’ll need a model registry to store details of the experiments and metadata from our training runs. This will also enable lineage traceability of the model being deployed and that of the data as well.
- A training pipeline will be needed because we’d need to automate the retraining process as fresh articles come in every day.
- Because we have a limited budget, our model will need to train every day at a reasonable amount of time and we may have to cap the amount of data it trains on for each training run as we can’t afford to take long to train and on very high volumes of new article releases.
- In our training architecture we might also want to take advantage of model checkpoints so that training and retraining don’t take too long (preferably under a few hours from the time they come in as that is often the peak log-in time for our users).
Production Model Management Specifications
1. Deployment and Serving Specifications
- Looks like a batch inference system would be worthwhile since we don’t need to serve predictions to the user in real-time while they browse the platform. The recommendations can be computed offline, stored in a database, and served to the user when they log in.
- To interface with the existing system, we can serve the model as a service with a RESTful interface.
- We would need to try avoiding dealing with serving dependency changes so that our automated pipeline runs don’t fail due to these changes.
- We want to ensure it’s easy to continuously deploy new model versions after successful evaluation, and track them as training will occur every day.
2. Model Monitoring Specifications
- Model drift should be monitored in real-time so that users aren’t getting stale recommendations as the news events are quite dynamic and users’ reading behavior can become uncertain too.
- We need to monitor data quality issues because there will be some times when there might be fewer fresh articles than is typically expected in a single day. Also taking into account corrupt data.
- Since we’ll frequently be retraining our model, we need to keep track of the training metadata for each run so that when a model fails to perform, we can audit its training details and troubleshoot.
- We’re dealing with pipelines, so we will need monitoring components to gauge the health of the pipelines.
- We’ll need to collect ground truth labels on how long a person spends on an article to measure our model performance and the model drift.
- Data drift should also be monitored alongside model drift to capture changes in user preferences and article features.
- We should also be able to get reports in the form of dashboard views and alerts when a pipeline fails, as we want to make sure our model is constantly updated.
3. Model Management Specifications
- Since a large number of articles come in at random based on events, we can set up a pull-based architecture that executes a workflow on schedule to retrain our model on new data.
- Model versioning will also need to be in place for each retrained and redeployed model version so we can easily roll back if the retrained model performs worse.
- Retraining will happen with data that has been transformed and loaded to a feature store.
4. Model Governance Specifications
- Model decisions should be explainable because misinformation could be audited and needs to be regulated.
System Operations (Ops) Specifications
- We need to define how your models will be able to run in production environments. What are the criteria for services to interact with each other and how will that define the operations of the entire system? Basically, the performance requirements for an optimal system operation.
- 95% Service Level Agreement (SLA) between the recommendation service and the backend server.
- Low serving latency and high throughput serving when serving batch predictions through the data storage to thousands of users.
- Track the number of successful, failed, and timed-out API calls.
- Training pipelines and the overall system should be monitored in terms of how much resources they consume; I/O, CPU usage, and memory.
- Infrastructure has to be model and run-time agnostic.
- Our production environment should not require frequent dependency changes that might cause our data and model pipelines to fail while executing. It should mostly be deterministic.
- We also need a reproducible environment because it will enable our rollback strategy when the system fails.
- We should ensure we properly version every infrastructure package so conflicts due to dependency changes can be easily debugged.
Defining system structure
Based on the goals, requirements, and specifications listed above, we can come up with the structure below for our system. You may notice that there are zero mentions of tooling or implementation. Right! This is more about designing a system with the business goal and end-user in mind. While designing your architecture, you should be as technology-agnostic as possible, and only focus on the requirements and specs.

The structure of a system is based on the requirements and specifications that were based on the goals of the business. Once you’ve been able to get the structure in place, you can now start choosing the tools and technologies to implement the structure.
Besides the architecture diagram like the one above, often referred to as the component-based architecture – you may want to dig deeper into each section of the diagram to make sure you don’t miss out on important things. Also, consider other diagrams such as:
- State and sequence diagrams that show the specifications of your architecture (such as those of the data, experiment, and production management phase) and how various phases and objects interact with each other. See an example of a state diagram here.
- Another diagram you may want to look at is the activity diagram.
As you may have guessed, this architecture is somewhat at level 1 of the MLOps maturity levels.
By the way, this structure is completely agnostic to the ML problem you’re solving. This means that it could work whether you’re working on a computer vision project or a natural language processing task—stating the obvious here but, of course, some data management specifications will change.
Deciding implementation
Considerations when deciding implementation
To reiterate a previous point, because MLOps is still a pretty nascent field, building an efficient ML system requires a combination of following templatized best practices and using robust tools (credits to Raghav Ramesh for the original idea). This essentially means that while deciding the tools to use in implementing the various components of your structure in line with your requirements and specifications, you have to be deliberate.
For now, it would be beneficial to look out for tools that are robust enough for the component you want to implement them for. Preferably, one platform that has you covered across the horizontal stack (of managing your data, experiments, and model) and is dynamic enough for you to integrate with your existing ecosystem, or can allow for easy migration across environments. Thankfully, the MLOps community is amazing and you can find a whole list of curated tools for MLOps on this website.
When deciding on the tools (or “toys” ) for implementing your MLOps architecture, you may want to consider the following:
- How soon do you need an MVP out and what will it take you to release one?
- What are the results from the risk assessment you carried out? How crucial are the security needs of the platform in terms of data, model, and the entire system?
- Will this tool be hard to learn and integrate with our existing ecosystem of tools?
- (If you’re working on a team) Do you have the right experience on the team to use a particular tool or set of tools?
- Is the cost of these tools reasonably in the budget you have set aside for this project? In terms of subscription or licensing fee (if you’re buying), hosting fee (if you’re building), maintenance fee, and so on.
Essentially, in terms of deciding your implementation, you want to choose what’s optimal for your project based on the scope, requirements, risks, and constraints (like costs, stakeholder skepticism, and so on).
Back to the project! In this case, I’ll work with using various robust tools to implement the components. I’ll also consider open-source MLOps solutions because of my budget constraints and the scope of the project for now. I’ll work my way up from infrastructure considerations.
Infrastructure tools
- We’ll start with making infrastructure decisions. For that, we prefer the entire system to be portable and executable anywhere and it should be model-agnostic too.
- We’ll use the Kubernetes engine for our runtime environment as this is reasonable in terms of the specifications, and it’s open-source.
- Making the entire system portable through Kubernetes will also ensure that we can easily move from an on-premise solution to a Cloud or hybrid solution if the need arises.
- Because of the budget constraint, we can specify a system resource limit using Kubernetes and it will constrain the entire system to that limit. It’s also open-source and we have an internal Ops team already familiar with it (recall our “Technical Considerations” section).
- We can also use Kubernetes extensions for system-wide access control, as a security measure.
NB: I’m aware of the rabbit hole of using K8s (Kubernetes) for Machine Learning, but let’s just pretend that we don’t know about Kubeflow right now. After all, this wouldn’t be the final form of the architecture, right? We’ll definitely learn our lessons and revisit the architecture sometime later!
Data acquisition and feature management tools
- For data storage, we’ll adopt PostgreSQL, an open-source, efficient database for structured data. Also, most managed solutions are popularly based on PostgreSQL and MySQL.
- We’ll also need a data pipeline, and we’ll use Apache Beam for writing our ETL (Extract, Transform, Load).
- To version the data pipeline, we’ll use Data Version Control (DVC), a GIT-like open-source tool for versioning datasets.
- For the feature store, we’ll have to go with Feast, it’s open-source and integrates well with the other storage tool (PostgreSQL).
Experiment management and model development tools
- For experiment management, we’ll go for neptune.ai, so the necessary metadata on hardware usage (CPU and memory usage) and hyperparameter values is logged, easy to visualize, and the training is reproducible.
- Neptune also helps with versioning the dataset and tracking the dataset version used in training.
- For model development, we’ll go with a framework that supports Python; we’ll choose it during implementation.
- I don’t have a specification to carry out distributed training right now, so I’ll leave this one for now.
ML Experiment Tracking: What It Is, Why It Matters, and How to Implement It
Production model management
1. Deployment and Serving Tools
- For packaging our model for deployment, we’ll use Docker. It’s pretty much supported by all platforms, runs on-premise, and can be managed within Kubernetes. The free version will do for now as there’s no compromise looking at the scope of our project.
- Our API protocol will be REST API and the API Gateway we’ll use Kong Gateway, it’s open-source, supports Kubernetes natively, and can run on-premise. And it’s really easy to set up!
- For deploying our model code, we’ll use GitHub Actions as all our project code will pretty much reside in our private GitHub repository. This will also enable our CI-CD pipeline too. Hosting is free on-premise, but we’ll closely monitor the number of minutes our workflow expends to see if the free version for a private repository will be sufficient for us.
- Depending on the framework we use, we’ll consider the serving tool to use to deploy our model as a service. We’re considering Flask or FastAPI for now. Perhaps we may also look into TensorFlow Serving but based on the scope, any of the two frameworks above should be sufficient.
2. Monitoring Tools
- For monitoring our model in production, we’ll use the perfect open-source combo of Prometheus and Grafana—Prometheus is a time-series database to collect monitoring data and Grafana visualizes monitored metrics and components on charts. There are very useful documentation and tutorials out there on how we can convert them to an ML monitoring service. They’re very robust tools.
- We will also consider using Prometheus’ Alertmanager for sending notifications beyond the service reports from our tools, for continuous monitoring and observability.
- For logging system metrics, we’ll use Elasticsearch from the ELK stack, as it’s open-source and supported by popular platforms.
- We can also log details on the API calls to our system; successful, failed, and timed-out calls.
- We can also track the throughput as that’s a core specification, in terms of volume of transactions the system makes, the number of requests it attended to, and the time it took to deliver the top n (this could be top 5 or top 10, depending on the request from the client) recommended articles with their similarity scores from the database.
3. Model Management Tools
- Even though neptune.ai is primarily an experiment tracker, it can serve as the model registry for every training run. Model versions can be logged for lineage traceability.
- For workflow scheduling and orchestration, we’ll use Apache Airflow, perhaps the most widely used orchestration tool.
4. Model Governance Tools
- In terms of being able to explain model recommendations, we’ll use SHAP as it can give us an overall explanation of why the model makes certain predictions.
That’s it for implementation choices—you can see that it was built on the structure and was in line with the requirements and the scope we defined during the planning phase. We’ll now go on using the AWS Well-Architected Framework (Machine Learning Lens) we previously looked at.
Reviewing architecture in line with the well-architected framework
Operational excellence
- We were able to identify the end-to-end architecture and operational model early in the ML workflow.
- We made sure to integrate continuous monitoring and measurement of our machine learning workload.
- We established a model retraining strategy based on our problem statement, requirements, and budget.
- We implemented components for versioning our model and artifacts in the training pipeline.
- Our automated workflow and committing our training code to a workflow tool ensures the continuous integration and deployment of our model.
Security
- So far, we’ve only enforced data and model lineage traceability—which is a good addition.
- During implementation, most of the tools we’ll be using provide access level control so we can follow security best practices.
- We can look forward to planning other measures such as operations security for our production environment, disaster recovery, and encrypting data from streaming data sources in transit and at rest.
- Auditing security measures will also be something this architecture will allow us to do.
Reliability
- So far, we’ve been able to make our system runtime-agnostic and train our model once and run it anywhere.
- One thing we’ll need to enforce with Apache Beam and Apache Airflow is implementing testability for the data that’s ingested into the data pipeline.
Performance efficiency
- Kubernetes can constrain the resources to run our workload, and it automatically scales our workload to optimize the resources for our ML workload.
- Monitoring system metrics with Prometheus and Grafana can help us track the resource usage by our model.
- Our monitoring tools will enable continuous monitoring and measurement of the system performance via the system metrics.
Cost optimization
- Our architecture allows for streaming any size of dataset large or small—we can always consider experimenting with varying sizes.
- The majority of our tools are currently on-premise but since our runtime environment is portable, we can always move it to a managed infrastructure.
- We can constrain the resources used by our ML workload by specifying that in the YAML file for Kubernetes.
Your challenge
In the beginning, I said I was going to give you a challenge. Here it is:
How would you build a fraud detection system that needs to integrate with an order management service for a business that promises next-day fulfillment?
Feel free to define the business however you want, but you may want to think of a larger scope than the previous project.
If you’re up for the challenge, you can find an example of the reference architecture I came up with (based on that question) in the “Resources for Choosing The Best MLOps Architecture For Your Project” section at the end of this article. Good luck!
Now it’s your turn: How should you select the most optimal MLOps architecture for your project?
To select the best architecture for your project, I recommend you do the following:
- Clearly understand and articulate the requirements, scope, and constraints needed for the project: Here’s a 3-part video series by Michael Perlin you can use to get started with for this. Other resources can be found in the reference and resource section. Your requirements should clearly state the business goals as well as what constitutes a good user experience.
- Design the structure of the system based on the requirements and don’t think of implementation or technologies that will fit into the structure at this time. Your main aim is to define the structure in line with the requirements from the previous step. I recommend looking at what others have done/are doing at this point in terms of their own system structure/architecture. (I have linked to architecture centers you can learn from in the resources section at the end of this article.)
- It’s now time for you to decide your own implementation! When choosing your tools and technologies, ensure they are robust enough for any phase of the ML pipeline they will be used in. If it’s a monitoring tool, ensure it’s scalable and has all the necessary features.
- Finally, justify your architecture by using the Machine Learning Well-Architected Framework design principles and best practices from AWS or any other good template out there.
Understand that your architecture only forms the foundation and gives you the path for how your ML system should be built. It shouldn’t lock you up in an implementation box but should only give you a clear path—understand that you can tweak things as you iteratively build your ML system. This is why Agile ML software building is the way to go, so you can spot issues quickly or even see better tools or platforms that can aid your implementation and help you deliver the most optimal ML system over the necessary period of time.
A couple of tips you may find useful…
- Following established best practices + robust tooling and implementation + putting an MVP out in the wild as soon as you can to iteratively build an optimal solution.
- You should start to think about—and plan—your MLOps architecture early on in the machine learning project lifecycle. This will help you coordinate activities and find blindspots in development and operationalization.
- Give others the chance to “roast” your architecture. Something that happens often in the MLOPs Community Slack channel is that I see others upload a public version of their architecture to give others the chance to critique it and give useful feedback. You can join such a community and interact with other practitioners, design what you think your system should look like. Allow other practitioners to critique it by sharing a public version alongside the necessary requirements.
- You may also delve into hybrid ML systems with multi-cloud or multi-platform solutions and also embedded systems MLOps architectures if you find that your requirements might involve training your model on one platform and serving it on another platform be it on-premise, a different cloud vendor, or on microcontrollers/edge devices.
Conclusion
In this article, we learned:
- Common MLOps architectural patterns for both training and serving,
- How to select the best MLOps architecture for your project,
- The framework for selecting optimal MLOps architecture for your project,
- And, most importantly:

Thank you for reading!
Resources for choosing the best MLOps architecture for your project
- If you want to learn more about analyzing business requirements for data science, check out this course on Pluralsight.
- For architecture templates, check out;
- Cloud Reference Architectures and Diagrams | Cloud Architecture Center (google.com).
- Machine Learning | AWS Architecture Center.
- Artificial intelligence (AI) – Azure Architecture Center | Microsoft Docs
- Thinking about choosing robust tools for your MLOps implementation? Check out this category of articles on Neptune’s blog.
- Want to see this in practice? Check out;
- You can take Kumaran Ponnambalam’s courses on LinkedIn Learning on “Architecting Big Data Applications: Real-Time Application Engineering” and “Architecting Big Data Applications: Batch Mode Application Engineering”.
- Again, another way to get better at designing ML systems is to see what others are doing. There are a couple of webinars and blog posts on how companies like Quora, Uber, Netflix, DoorDash, Spotify, or other lesser-known companies are architecting their own system. Check out;
- MLconf on YouTube for very good sessions.
- Databricks videos on YouTube.
- I wrote an article recently on how 8 companies are implementing MLOps, you can check it out here.
- Here’s a fairly recent release of how to build an ML platform from scratch that I thought you’d find useful.
- If you want to abstract yourself and your team from all the 3rd party tools and using a separate tool for each component, you want to consider using some good MLOps platforms out there: Best MLOps Platforms to Manage Machine Learning Lifecycle
- My solution for the challenge given.
References
- (2688) Michael Perlin – YouTube
- Google Cloud’s training on Production Machine Learning Systems
- Machine Learning Lens – AWS Well-Architected Framework – Machine Learning Lens (amazon.com)
- AWS re: Invent 2020: Architectural best practices for machine learning applications – YouTube
- What is the difference between requirements and specifications? – Software Engineering Stack Exchange
- (1441) Architectural and Organizational Patterns in Machine Learning with Nishan Subedi – #462 – YouTube
- Spring 2021 Schedule – Full Stack Deep Learning
