
Version control is important in any software development environment, and even more so in machine learning. In ML, the development process is very complex. It includes huge amounts of data, testing of multiple models, optimization of parameters, tuning of features, and more.
If you want your research to be reproducible, you need proper version control tools to manage and track all of the above. So, in this article, we’re going to explore what version control is in machine learning, why you need it, and how to implement it.
What does ‘version control’ mean?
Version Control is the process of tracking and managing software changes over time. Whether you’re building an app or an ML model, you need to track every modification done by members of the software team to fix bugs and avoid conflicts.
To achieve that, you can use a version control framework. Frameworks were developed to track every individual change by each contributor and save it in a special kind of database, where you can identify the differences and help prevent conflicts in concurrent work while merging.
Why do we need version control in ML?
The machine learning development process includes a lot of iterative work, where the developers are searching for the best performing model while changing hyperparameters, code, and data. It’s important to keep a history of these changes to track model performance relative to the parameters, which saves you the time you’d spend retraining the model for experimentation.

Machine learning version control has three parts:
- Code
There’s modelling code, and there’s implementation code. Modelling code is used to implement the model, and implementation code is used for inference. They can both be written in different programming languages, but it might make it more difficult to maintain all of your code and dependencies.
- Data
There’s metadata, which is information about your data and model. Then there’s the actual data, the datasets you use to train and run your model. Metadata can change without any change in the data, and versioning should link the data to the appropriate meta.
- Model
The model connects all of the above with model parameters and hyperparameters. When you use a model version control system, you get plenty of benefits:
- Collaboration: if you’re a solo researcher, this might not be important. When you work with a team and your project is complex, it becomes very difficult to collaborate without a version control system.
- Versioning: while making changes, the model can break. With a version control system, you get a changelog which will be helpful when your model breaks and you can revert your changes to get back to a stable version.
- Reproducibility: by taking snapshots for the entire machine learning pipeline, you make it possible to reproduce the same output again, even with the trained weights, which saves the time of retraining and testing.
- Dependency tracking: tracking different versions of the datasets (training, evaluation, and development), tuning the model hyperparameters and parameters. By using version control, you can test more than one model on different branches or repositories, tune the model parameters and hyperparameters, and monitor the accuracy of each change.
- Model Updates: model development is not done in one step, it works in cycles. With the help of version control, you can control which version is released while continuing the development for the next release.
Machine learning version control types
There are two types of ML version control:
- Centralized Version Control System.
- Distributed Version Control System.
A Distributed Version Control System (DVCS) is a version control system where the full codebase is available locally on the developer’s computer, including the history. This enables the developer to merge and create branches locally, without being connected to a remote server or any network at all. An example of these systems is Git.
Using this approach for model development has the advantage of working privately on your machine without the need to be online and not relying on a single server for backup. This can be useful for training purposes and while the project is still small. However, when the project repository becomes bigger, this will require a large storage to keep all the history and all the branches data on the developer computer, which is why another centralized version control approach was introduced.

A Centralized Version Control System (CVCS) is a version control where the developer has to check out the repository from a single centralized server containing all the files and file history.
These systems make it easy to control the full codebase in one place, and everyone is aware of any changes that happen. However, it can be slow in case of central server connection issues, plus it’s risky to have all the backups in one place.
This can be used when your model is mature enough and used as part of a product. You have different teams working with a lot of features and changes, you don’t need to have all the code on the developer computer, and you want to reduce the complexity of merging and adding changes.
Also, CVCS reduces the storage size needed for the development, as you will have only one server containing all the code changes, and developers only need a single version of the system to work on locally.

Model version control
During the model development process, the developer encounters some questions:
- Which hyperparameters the model was trained on?
- What are the code changes made after the last model training?
- Which dataset was the model trained on?
- What changes were made to the dependencies from the last model training?
- What was the change that made the model fail?
- What were the changes that made the model perform better?
- Which version of the model was last released?
In order to answer the questions, you need to keep track of the changes made during model development, which bring up the question of what needs to be versioned.
What needs to be versioned in ML development?
Answering this question depends on which step of model development you’re in. Let’s see what needs to be versioned in each development step.
- Model Selection:
First, you need to decide which algorithm to use. You might need to try more than one algorithm and compare the performance. Each selected algorithm should have its own versioning to track the changes separately and choose the best performing model.
While writing your model or making performance changes to the model, you should keep track of the changes to understand what caused the performance to change.
This can be implemented by using different repositories for each model. This way you can test multiple models in parallel and provide some isolation between the models.
- Model Training:
Hyperparameters used for training should be tracked. You can create different branches for each hyperparameter to tune it and keep track of the model performance on each hyperparameter change.
Trained parameters should also be versioned along with the model code and hyperparameters, to ensure the reproducibility of the same trained weights and even save the time needed for retraining the model when you revert to this version.
To implement this using version control systems, you need to create a branch for each feature, parameter, and hyperparameter you’re going to change. This enables you to perform the analysis using one change at a time and maintain all the changes related to the same model in one repository.

- Model Evaluation:
Evaluation is when the developer uses the hold-out, or test-set, to check how the model is performing on data that it has never seen.

The hold-out and the performance results should be kept on the versioning system, as well as a record of the performance matrices on each step. As mentioned in the model training part, after you select the parameters that best fit your needs, you will need to merge the change to an integration branch and run the evaluation on this branch.
- Model Validation:
Model Validation is the process of validating that the model is performing as expected on real data. In this step, you have to keep track of each validation result and track the performance of the model during the model lifetime. What were the model changes that enhanced the performance of the model? If you’re comparing between different models, then you should track the validation matrices used to evaluate different models. To implement this, and after evaluating the performance on the integration branch, model validation can be done on the main branch where you can merge the evaluated changes to it, perform your validation on it, and label the changesets that meet your customer specs as a version ready for deployment.
- Model Deployment:
When your model is ready to be deployed, you should keep track of which version was deployed and what were the changes in each version. This will enable you to have a staged deployment as you start by deploying your latest version on the main branch, while still developing and improving your model. This will also give you the fault tolerance needed if your model fails on the deployment to revert back to the previous working version.
Lastly, having model versioning can help the ML engineers to understand what was changed in the model, which functionality was updated by the researchers, and how the functionality was changed. Knowing what was done, and how, can affect the deployment speed and simplicity when integrating multiple features together.
How to implement model version control
To summarize what was mentioned in the previous section, the steps to implement model version control are as follows:
- Create separate repositories for each model you’re going to implement;
- Create a separate branch for each model parameter, hyperparameter or feature you want to evaluate;
- Create an integration branch where you collect the features that you need based on the performance analysis done on each feature separately;
- Evaluate the model on the integration branch;
- Merge from the integration branch to the main branch and perform your validation;
- Label the versions on the main branch with the version number.
Machine learning model version control tools
Choosing the right tool to perform your versioning is very important, The chosen tool should provide a clear vision on each part of the pipeline, and means to link between different types of versioning like data, code and model versioning (not just a simple managing and tracking files changes).
A good model versioning system will smooth the collaboration between team members, provide a way to visualize the data changes, and automate the development process.
neptune.ai


neptune.ai is an experiment tracker designed with a strong focus on collaboration and scalability. The tool is known for its user-friendly interface and flexibility, enabling teams to adopt it into their existing workflows with minimal disruption. Neptune gives users a lot of freedom when defining data structures and tracking metadata.
DVC
An open-source version control system designed especially for machine learning projects, built to enable reproducibility and sharing of machine learning models.
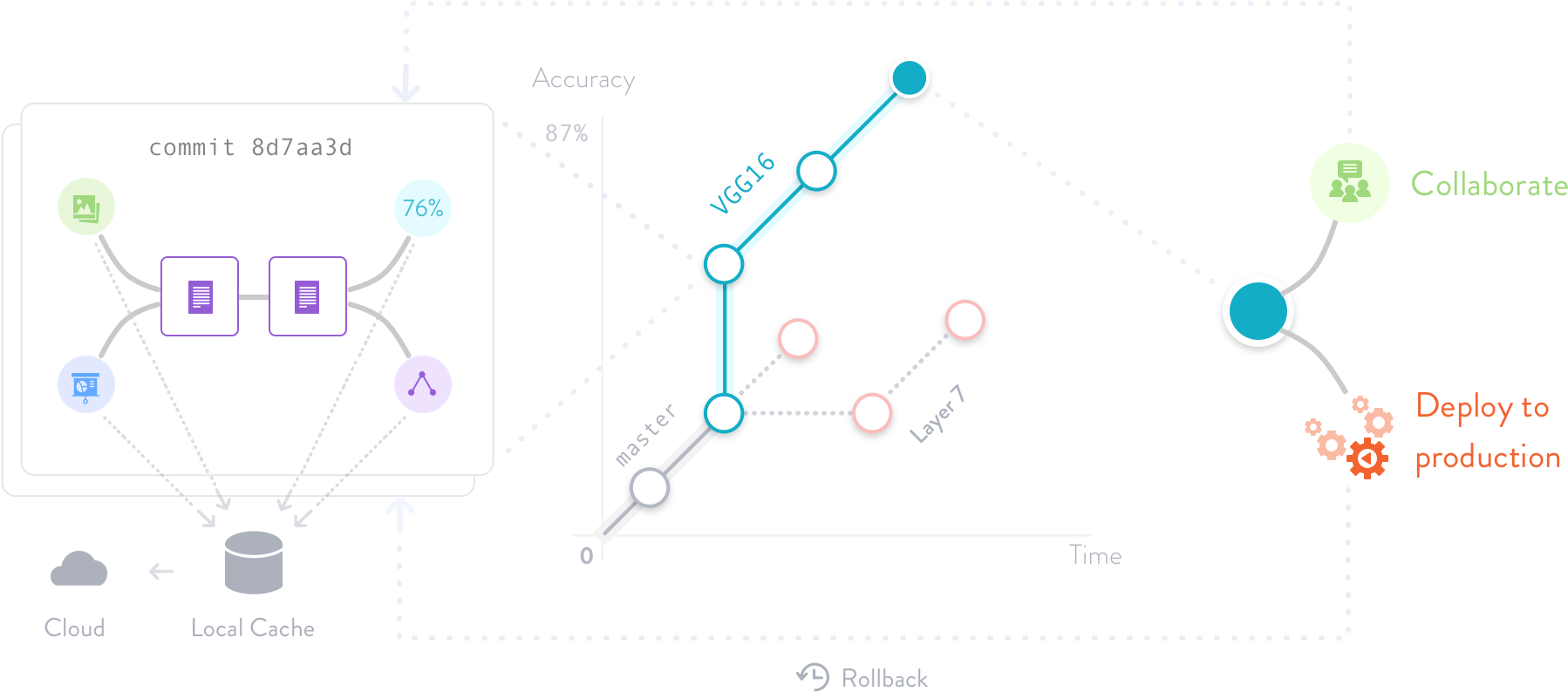
How DVC compares with neptune.ai
ML Metadata (MLMD)
A library that stores Models Metadata generated on each run from different components, including the trained models and their executions. Designed initially to work with Tensorflow, but can be used independently.

Summary
Versioning is a very important step during and after model development. It enables collaboration, history keeping, and performance monitoring over multiple versions.
What needs to be versioned in your project? This depends on which state of the development process you are currently in. Whether you will use a centralized version control system or a distributed one, you have to choose the appropriate tool that satisfies your needs.
