How to Do Data Exploration for Image Segmentation and Object Detection (Things I Had to Learn the Hard Way)

I’ve been working with object detection and image segmentation problems for many years. An important realization I made is that people don’t put the same amount of effort and emphasis on data exploration and results analysis as they would normally in any other non-image machine learning project.
Why is it so?
I believe there are two major reasons for it:
- People don’t understand object detection and image segmentation models in depth and treat them as black boxes, in that case they don’t even know what to look at and what the assumptions are.
- It can be quite tedious from a technical point of view as we don’t have good image data exploration tools.
In my opinion image datasets are not really an exception, understanding how to adjust the system to match our data is a critical step to success.
In this article I will share with you how I approach data exploration for image segmentation and object detection problems. Specifically:
- Why you should care about image and object dimensions,
- Why small objects can be problematic for many deep learning architectures,
- Why tackling class imbalances can be quite hard,
- Why a good visualization is worth a thousand metrics,
- The pitfalls of data augmentation.
The need for data exploration for image segmentation and object detection
Data exploration is key to a lot of machine learning processes. That said, when it comes to object detection and image segmentation datasets there is no straightforward way to systematically do data exploration.
There are multiple things that distinguish working with regular image datasets from object and segmentation ones:
- The label is strongly bound to the image. Suddenly you have to be careful of whatever you do to your images as it can break the image-label-mapping.
- Usually much more labels per image.
- Much more hyperparameters to tune (especially if you train on your custom datasets)
This makes evaluation, results exploration and error analysis much harder. You will also find that choosing a single performance measure for your system can be quite tricky – in that case manual exploration might still be a critical step.
Data quality and common problems
The first thing you should do when working on any machine learning problem (image segmentation, object detection included) is assessing quality and understanding your data.
Common data problems when training Object Detection and Image Segmentation models include:
- Image dimensions and aspect ratios (especially dealing with extreme values)
- Labels composition – imbalances, bounding box sizes, aspect ratios (for instance a lot of small objects)
- Data preparation not suitable for your dataset.
- Modelling approach not aligned with the data.
Those will be especially important if you train on custom datasets that are significantly different from typical benchmark datasets such as COCO. In the next chapters, I will show you how to spot the problems I mentioned and how to address them.
General data quality
This one is simple and rather obvious, also this step would be the same for all image problems not just object detection or image segmentation. What we need to do here is:
- get the general feel of a dataset and inspect it visually.
- make sure it’s not corrupt and does not contain any obvious artifacts (for instance black only images)
- make sure that all the files are readable – you don’t want to find that out in the middle of your training.
My tip here is to visualize as many pictures as possible. There are multiple ways of doing this. Depending on the size of the datasets some might be more suitable than the others.
- Plot them in a jupyter notebook using matplotlib.
- Use dedicated tooling like google facets to explore image data
- Use HTML rendering to visualize and explore in a notebook.
I’m a huge fan of the last option, it works great in jupyter notebooks (even for thousands of pictures at the same time!) Try doing that with matplotlib. There is even more: you can install a hover-zoom extension that will allow you to zoom in into individual pictures to inspect them in high-resolution.
Image sizes and aspect ratios
In the real world, datasets are unlikely to contain images of the same sizes and aspect ratios. Inspecting basic datasets statistics such as aspect ratios, image widths and heights will help you make important decisions:
- Can you and should you? do destructive resizing ? (destructive means resizing that changes the AR)
- For non-destructive resizing what should be your desired output resolution and amount of padding?
- Deep Learning models might have hyper parameters you have to tune depending on the above (for instance anchor size and ratios) or they might even have strong requirements when it comes to minimum input image size.
A special case would be if your dataset consists of images that are really big (4K+), which is not that unusual in satellite imagery or some medical modalities. For most cutting edge models in 2020, you will not be able to fit even a single 4K image per (server grade) GPU due to memory constraints. In that case, you need to figure out what realistically will be useful for your DL algorithms.
Two approaches that I saw are:
- Training your model on image patches (randomly selected during training or extracted before training)
- resizing the entire dataset to avoid doing this every time you load your data.
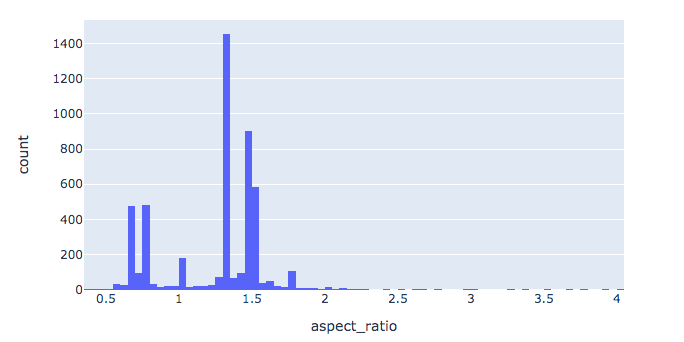
In general I would expect most datasets to fall into one of 3 categories.
- Uniformly distributed where most of the images have the same dimensions – here the only decision you will have to make is how much to resize (if at all) This will mainly depend on objects area, size and aspect ratios)
- Slightly bimodal distribution but most of the images are in the aspect ratio range of (0.7 … 1.5) similar to the COCO dataset. I believe other “natural-looking” datasets would follow a similar distribution – for those type of datasets you should be fine by going with a non-destructive resize -> Pad approach. Padding will be necessary but to a degree that is manageable and will not blow the size of the dataset too much.
- Dataset with a lot of extreme values (very wide images mixed with very narrow ones) – this case is much more tricky and there are more advanced techniques to avoid excessive padding. You might consider sampling batches of images based on the aspect ratio. Remember that this can introduce a bias to your sampling process – so make sure its acceptable or not strong enough.
The mmdetection framework supports this out of the box by implementing a GroupSampler that samples based on AR’s
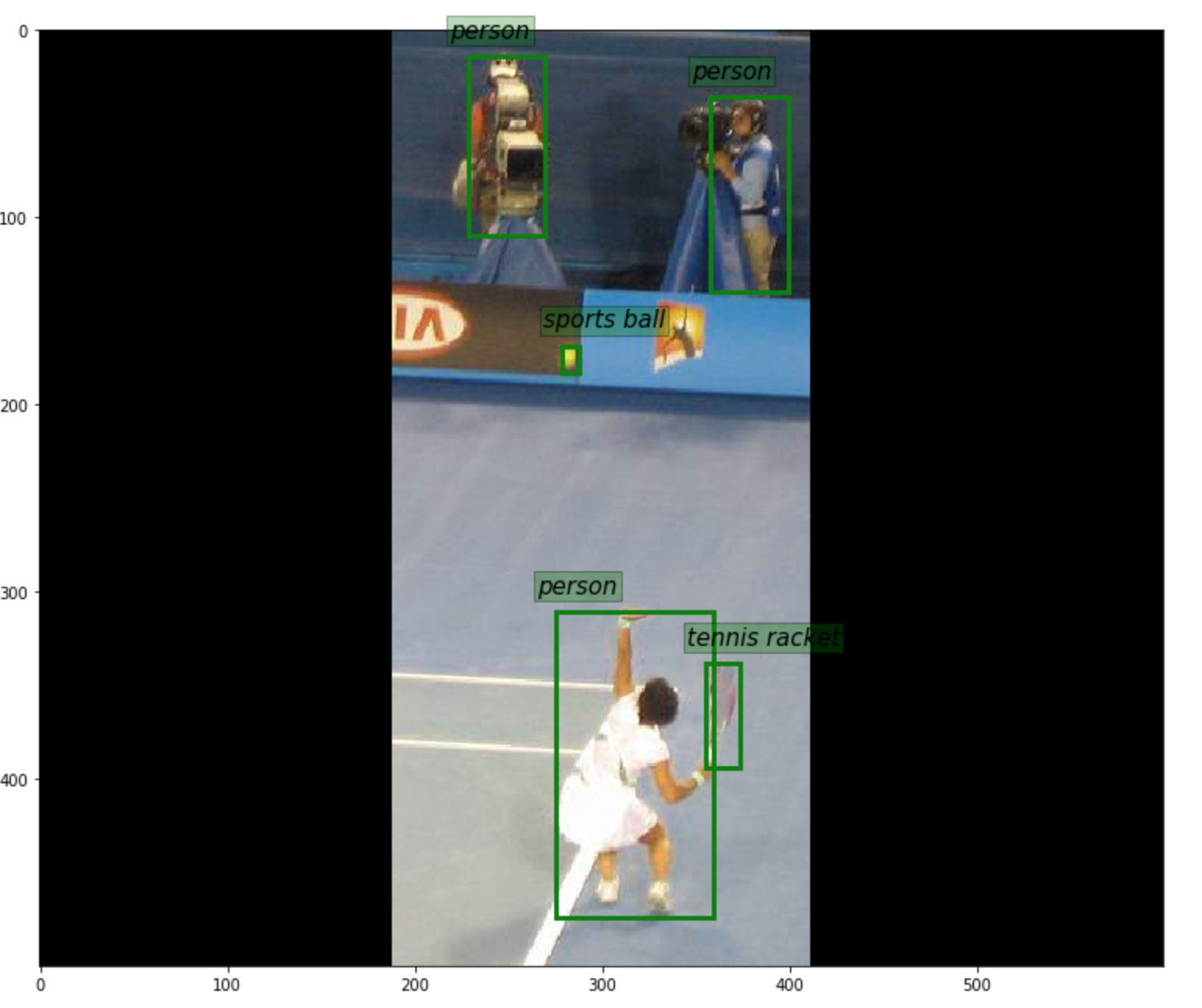

Fig 3 and 4. Example Images (resized and padded) with a extreme aspect ratios from the coco dataset
Label (objects) sizes and dimensions
Here we start looking at our targets (labels). Particularly we are interested in knowing how the sizes and aspect ratios are distributed.
Why is this important?
Depending on your modelling approach most of the frameworks will have design limitations. As I mentioned earlier, those models are designed to perform well on benchmark datasets. If for whatever reason your data is different, training them might be impossible. Let’s have a look at a default config for Retinanet from detectron2:
ANCHOR_GENERATOR:
SIZES: !!python/object/apply:eval ["[[x, x * 2**(1.0/3), x * 2**(2.0/3) ] for x in [32, 64, 128, 256, 512 ]]"]
What you can see there is, that for different feature maps the anchors we generate will have a certain size range:
- for instance, if your dataset contains only really big objects – it might be possible to simplify the model a lot,
- on the other side let’s assume you have small images with small objects (for instance 10x10px) given this config it can happen you will not be able to train the model.
The most important things to consider when it comes to box or mask dimensions are:
- Aspect ratios
- Size (Area)

The tail of this distribution (fig. 3) is quite long. There will be instances with extreme aspect ratios. Depending on the use case and dataset it might be fine to ignore it or not, this should be further inspected.

This is especially true for anchor-based models (most of object detection / image segmentation models) where there is a step of matching ground truth labels with predefined anchor boxes (aka. Prior boxes).
Remember that you control how those prior boxes are generated with hyperparameters like the number of boxes, their aspect ratio, and size. Not surprisingly you need to make sure those settings are aligned with your dataset distributions and expectations.

An important thing to keep in mind is that labels will be transformed together with the image. So if you are making an image smaller during a preprocessing step the absolute size of the ROI’s will also shrink.
If you feel that object size might be an issue in your problem and you don’t want to enlarge the images too much (for instance to keep desired performance or memory footprint) you can try to solve it with a Crop -> Resize approach. Keep in mind that this can be quite tricky (you need to handle cases what happens if you cut through a bounding box or segmentation mask)
Big objects on the other hand are usually not problematic from a modelling perspective (although you still have to make sure that will be matched with anchors). The problem with them is more indirect, essentially the more big objects a class has the more likely it is that it will be underrepresented in the dataset. Most of the time the average area of objects in a given class will be inversely proportional to the (label) count.
Partially labeled data
When creating and labeling an image detection dataset missing annotations are potentially a huge issue. The worst scenario is when you have false negatives already in your ground truth. So essentially you did not annotate objects even though they are present in the dataset.
In most of the modeling approaches, everything that was not labeled or did not match with an anchor is considered background. This means that it will generate conflicting signals that will hurt the learning process a LOT.
This is also a reason why you can’t really mix datasets with non-overlapping classes and train one model (there are some way to mix datasets though – for instance by soft labeling one dataset with a model trained on another one)
Imbalances
Class imbalances can be a bit of a problem when it comes to object detection. Normally in image classification for example, one can easily oversample or downsample the dataset and control each class contribution to the loss.
You can imagine this is more challenging when you have co-occurring classes object detection dataset since you can’t really drop some of the labels (because you would send mixed signals as to what the background is).
In that case you end up having the same problem as shown in the partially labeled data paragraph. Once you start resampling on an image level you have to be aware of the fact that multiple classes will be upsampled at the same time.
Note:
You may want to try other solutions like:
-
t
- Adding weights to the loss (making the contributions of some boxes or pixels higher)
- Preprocessing your data differently: for example you could do some custom cropping that rebalances the dataset on the object level
t
Understanding augmentation and preprocessing sequences
Preprocessing and data augmentation is an integral part of any computer vision system. If you do it well you can gain a lot but if you screw up it can really cost you.
Data augmentation is by far the most important and widely used regularization technique (in image segmentation / object detection ).
Applying it to object detection and segmentation problems is more challenging than in simple image classification because some transformations (like rotation, or crop) need to be applied not only to the source image but also to the target (masks or bounding boxes). Common transformations that require a target transform include:
- Affine transformations,
- Cropping,
- Distortions,
- Scaling,
- Rotations
- and many more.
It is crucial to do data exploration on batches of augmented images and targets to avoid costly mistakes (dropping bounding boxes, etc).
Note:
Basic augmentations are a part of deep learning frameworks like PyTorch or Tensorflow but if you need more advanced functionalities you need to use one of the augmentation libraries available in the python ecosystem. My recommendations are:
-
t
- Albumentations (I’ll use it in this post)
- Imgaug
- Augmentor
t
t
The minimal preprocessing setup
Whenever I’m building a new system I want to keep it very basic on the preprocessing and augmentation level to minimize the risk of introducing bugs early on. Basic principles I would recommend you to follow is:
- Disable augmentation
- Avoid destructive resizing
- Always inspect the outputs visually
Let’s continue our COOC example. From the previous steps we know that:
the majority of our images have:
- aspect ratios = width / height = 1.5
- the average avg_width is = 600 and avg_height = 500.
Setting the averages as our basic preprocessing resize values seems to be a reasonable thing to do ( unless there is a strong requirement on the model side to have bigger pictures ) for instance a resnet50 backbone model has a minimum size requirement of 32×32 (this is related to the number of downsampling layers)
In Albumentations the basic setup implementation will look something like this:
- LongestMaxSize(avg_height) – this will rescale the image based on the longest side preserving the aspect ratio
- PadIfNeeded(avg_height, avg_width, border_mode=’FILL’, value=0)


Fig 10 and 11. MaxSize -> Pad output for two pictures with drastically different aspect ratios
As you can see on figure 10 and 11 the preprocessing results in an image of 500×600 with reasonable 0-padding for both pictures.
When you use padding there are many options in which you can fill the empty space. In the basic setup I suggest that you go with default constant 0 value,
When you experiment with more advanced methods like reflection padding always explore your augmentations visually. Remember that you are running the risk of introducing false negatives especially in object detection problems (reflecting an object without having a label for it)

Augmentation – Rotations
Rotations are powerful and useful augmentations but they should be used with caution. Have a look at fig 13. below which was generated using a Rotate(45)->Resize->Pad pipeline.
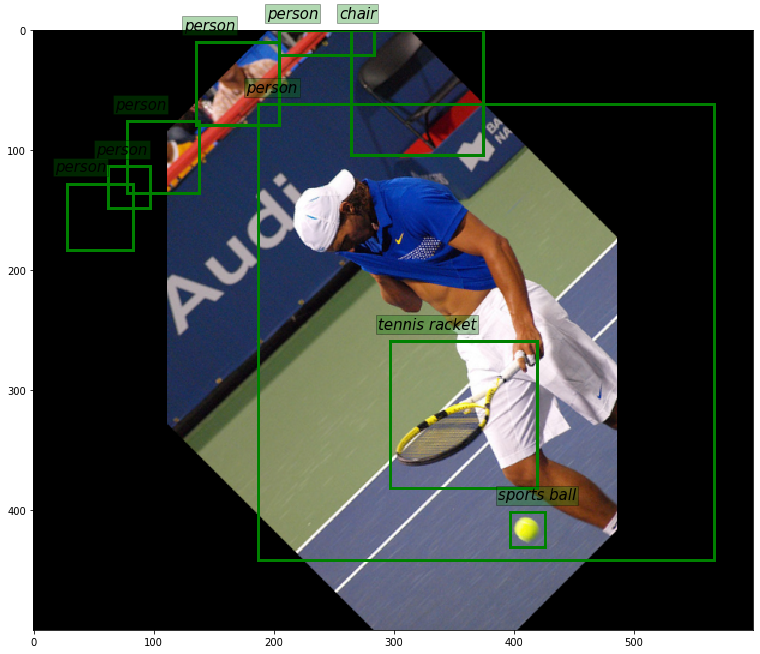
The problem is that if we use standard bounding boxes (without an angle parameter), covering a rotated object can be less efficient (box-area to object-area will increase). This happens during rotation augmentations and it can harm the data. Notice that we have also introduced false positive labels in the top left corner. This is because we crop-rotated the image.
My recommendation is:
- You might want to give up on those if you have a lot of objects with aspect ratios far from one.
Another thing you can consider is using 90,180, 270 degree non-cropping rotations (if they make sense) for your problem (they will not destroy any bounding boxes)
Augmentations – key takeaways
As you see, spatial transforms can be quite tricky and a lot of unexpected things can happen (especially for object detection problems).
So if you decide to use those spatial augmentations make sure to do some data exploration and visually inspect your data.
Note:
Do you really need spatial augmentations? I believe that in many scenarios you will not need them and as usual keep things simpler and gradually add complexity.
From my experience a good starting point (without spatial transforms) and for natural looking datasets (similar to coco) is the following pipeline:
transforms = [
LongestMaxSize(max_size=500),
HorizontalFlip(p=0.5),
PadIfNeeded(500, 600, border_mode=0, value=0),
JpegCompression(quality_lower=70, quality_upper=100, p=1),
RandomBrightnessContrast(0.3, 0.3),
Cutout(max_h_size=32, max_w_size=32, p=1)
]
Of course things like max_size or cutout sizes are arbitrary and have to be adjusted.

Best practice:
One thing I did not mention yet that I feel is pretty important: Always load the whole dataset (together with your preprocessing and augmentation pipeline) .
%%timeit -n 1 -r 1
for b in data_loader: pass
Two lines of code that will save you a lot of time.
First of all, you will understand what the overhead of the data loading is and if you see a clear performance bottleneck you might consider fixing it right away. More importantly, you will catch potential issues with:
- corrupted files,
- labels that can’t be transformed etc
- anything fishy that can interrupt training down the line.
Results understanding
Inspecting model results and performing error analysis can be a tricky process for those types of problems. Having one metric rarely tells you the whole story and if you do have one interpreting it can be a relatively hard task.
Let’s have a look at the official coco challenge and how the evaluation process looks there (all the results i will be showing are for a MASK R-CNN model with a resnet50 backbone).

It returns the AP and AR for various groups of observations partitioned by IOU (Intersection over Union of predictions and ground truth) and Area. So even the official COCO evaluation is not just one metric and there is a good reason for it.
Lets focus on the IoU=0.50:0.95 notation.
What this means is the following: AP and AR is calculated as the average of precisions and recalls calculated for different IoU settings (from 0.5 to 0.95 with a 0.05 step). What we gain here is a more robust evaluation process, in such a case a model will score high if its pretty good at both (localizing and classifying)
Of course, your problem and dataset might be different. Maybe you need an extremely accurate detector, in that case, choosing AP@0.90IoU might be a good idea.
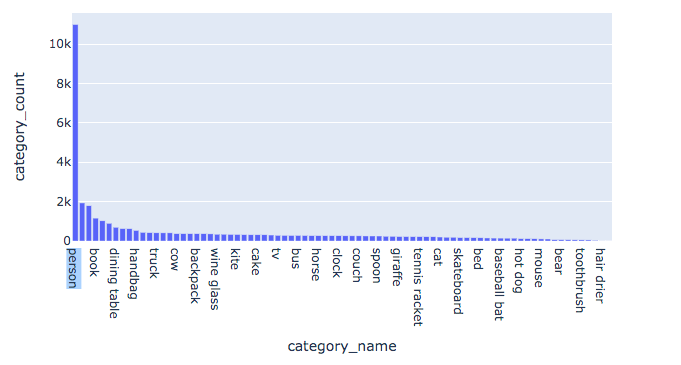
The downside (of the coco eval tool) is that by default all the values are averaged for all the classes and all images. This might be fine in a competition-like setup where we want to evaluate the models on all the classes but in real-life situations where you train models on custom datasets (often with fewer classes) you really want to know how your model performs on a per-class basis.
Looking at per-class metrics is extremely valuable, as it might give you important insights:
- help you compose a new dataset better
- make better decisions when it comes to data augmentation, data sampling etc.

Figure 16. gives you a lot of useful informations there are few things you might consider:
- Add more data to low performing classes
- For classes that score well, maybe you can consider downsampling them to speed up the training and maybe help with the performance of other less frequent classes.
- Spot any obvious correlations for instance classes with small objects performing poorly.
Visualizing results
Ok, so if looking at single metrics is not enough what should you do?
I would definitely suggest spending some time on manual results exploration, with the combination of hard metrics from the previous analysis – visualizations will help you get the big picture.
Read next
![]() The Best Tools to Visualize Metrics and Hyperparameters of Machine Learning Experiments
The Best Tools to Visualize Metrics and Hyperparameters of Machine Learning Experiments
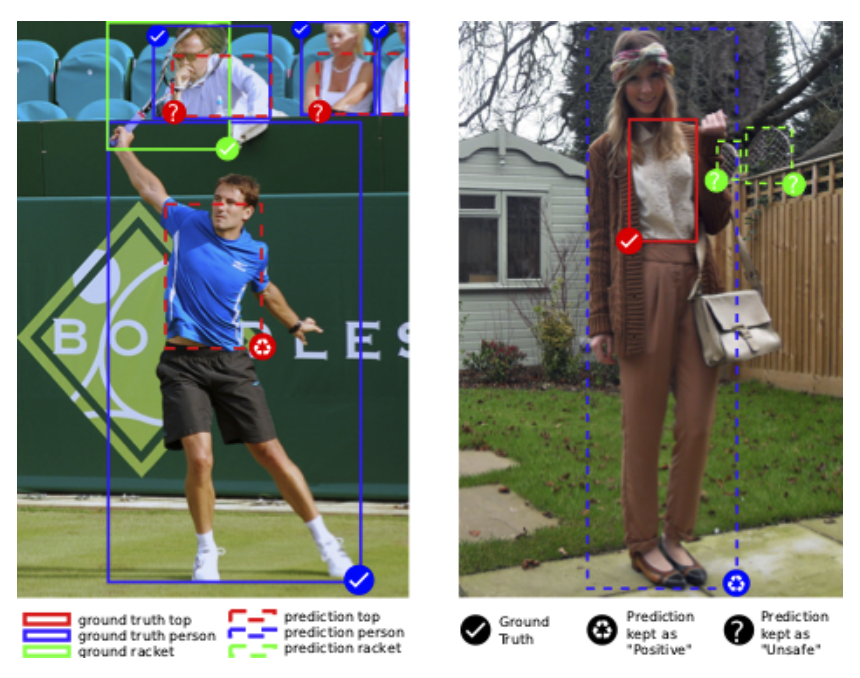
Since exploring predictions of image detection and image segmentation models can get quite messy I would suggest you do it step by step. On the gif below I show how this can be done using the coco inspector tool.
On the gif we can see how all the important information is visualized:
- Red masks – predictions
- Orange masks – overlap of predictions and ground truth masks
- Green masks – ground truth
- Dashed bounding boxes – false positives (predictions without a match)
- Orange boxes true positive
- Green boxes – ground truth
Results understanding – per image scores
By looking at the hard metrics and inspecting images visually we most likely have a pretty good idea of what’s going on. But looking at results of random images (or grouped by class) is likely not an optimal way of doing this. If you want to really dive in and spot edge cases of your model, I suggest calculating per image metrics (for instance AP or Recall).
Below and example of an image I found by doing exactly that.

In the example above (Fig 18.) we can see two false positive stop sign predictions – from that we can deduce that our model understands what a stop sign is but not what other traffic signs are.
Perhaps we can add new classes to our dataset or use our “stop sign detector” to label other traffic signs and then create a new “traffic sign” label to overcome this problem.

Sometimes we will also learn that our model is doing better that it would seem from the scores alone. That’s also useful information, for instance in the example above our model detected a keyboard on the laptop but this is actually not labeled in the original dataset.
COCO format
The way a coco dataset is organized can be a bit intimidating at first.
It consists of a set of dictionaries mapping from one to another. It’s also intended to be used together with the pycocotools / cocotools library that builds a rather confusing API on top of the dataset metadata file.
Nonetheless, the coco dataset (and the coco format) became a standard way of organizing object detection and image segmentation datasets.
In COCO we follow the xywh convention for bounding box encodings or as I like to call it tlwh: (top-left-width-height) that way you can not confuse it with for instance cwh: (center-point, w, h). Mask labels (segmentations) are run-length encoded (RLE explanation).

There are still very important advantages of having a widely adopted standard:
- Labeling tools and services export and import COCO-like datasets
- Evaluation and scoring code (used for the coco competition) is pretty well optimized and battle tested.
- Multiple open source datasets follow it.
In the previous paragraph, I used the COCO eval functionality which is another benefit of following the COCO standard. To take advantage of that you need to format your predictions in the same way as your coco dataset is constructed- then calculating metrics is as simple as calling: COCOeval(gt_dataset, pred_dataset)
COCO dataset explorer
In order to streamline the process of data and results exploration (especially for object detection) I wrote a tool that operates on COCO datasets.
Essentially you provide it with the ground truth dataset and the predictions dataset (optionally) and it will do the rest for you:
- Calculate most of the metrics I presented in this post
- Easily visualize the datasets ground truths and predictions
- Inspect coco metrics, per class AP metrics
- Inspect per-image scores
To use COCO dataset explorer tool you need to:
- Clone the project repository
git clone https://github.com/i008/COCO-dataset-explorer.git
- Download example data I used for the examples or use your own data in the COCO format:
Example COCO format dataset with predictions.
If you downloaded the example data you will need to extract it.
tar -xvf coco_data.tar
You should have the following directory structure:
COCO-dataset-explorer
|coco_data
|images
|000000000139.jpg
|000000000285.jpg
|000000000632.jpg
|...
|ground_truth_annotations.json
|predictions.json
|coco_explorer.py
|Dockerfile
|environment.yml
|...
- Set up the environment with all the dependencies
conda env update; conda activate cocoexplorer
- Run streamlit app specifying a file with ground truth and predictions in the COCO format and the image directory:
streamlit run coco_explorer.py --
--coco_train coco_data/ground_truth_annotations.json
--coco_predictions coco_data/predictions.json
--images_path coco_data/images/
Note: You can also run this with docker:
sudo docker run -p 8501:8501 -it -v "$(pwd)"/coco_data:/coco_data i008/coco_explorer
streamlit run coco_explorer.py --
--coco_train /coco_data/ground_truth_annotations.json
--coco_predictions /coco_data/predictions.json
--images_path /coco_data/images/
- explore the dataset in the browser. By default, it will run on http://localhost:8501/
FURTHER READING
Final words
I hope that with this post I convinced you that data exploration in object detection and image segmentation is as important as in any other branch of machine learning.
I’m confident that the effort we make at this stage of the project pays off in the long run.
The knowledge we gather allows us to make better-informed modeling decisions, avoid multiple training pitfalls and gives you more confidence in the training process, and the predictions your model produces.
