
Chances are that you’ve come across a machine learning paper and tried to replicate it, only to find that you get very different results. You tweak your code but keep getting it wrong. At this point, you’re doubting your skills as a data scientist, but don’t worry. I’m here to tell you that it’s completely okay, and it is not your fault!
This is the classic case of the reproducibility challenge, a problem that isn’t unique to machine learning.
In the sciences, reproducibility is a major principle of the scientific method. It shows that results or observations obtained from an experiment or study should be replicated with the same methodology but different researchers and the results obtained by these different researchers must be similar to the result obtained by the original researchers. Because a result becomes a scientific fact only after several successful replications by different teams of researchers.
But, let’s circle back to machine learning. What exactly does reproducibility mean in ML?
What is reproducibility in machine learning?
Reproducibility in machine learning means that you can repeatedly run your algorithm on certain datasets and obtain the same (or similar) results on a particular project.
Reproducibility in machine learning means being able to replicate the ML orchestration carried out in a paper, article, or tutorial and getting the same or similar results as the original work.
Most ML orchestrations are usually end-to-end, by this I mean from data processing to model design, reporting, model analysis, or evaluation to successful deployment.
Being able to replicate results is very important, as it means the project is scalable and ready to push for production with large-scale deployment.
Reproducibility doesn’t come easy. Complex challenges make it seem almost impossible to replicate ML results from papers, and we’re going to explore these challenges in a second.
It can be said that reproducibility in machine learning hangs on the three core elements of any model:
- Code
- Data
- Environment.
Code: To achieve reproducibility, you must track and record changes in code and algorithms during experimentation.
Data: Adding new datasets, data distribution and sample changes will affect the outcome of a model. Dataset versioning and change tracking must be recorded to achieve reproducibility.
Environment: For a project to be reproducible, the environment it was built in must be captured. Framework dependencies, versions, the hardware used, and all other parts of the environment must be logged and easy to reproduce. Our environment should fulfil the following criteria:
- Use the latest library and document version,
- Be able to return to the previous state without destroying the setup,
- Use identical versions on multiple machines,
- Set randomization parameters,
- Use all available computational power.
These three core elements combined make your model. The bridge between all three is what’s called the ML pipeline.
Now that we’ve covered the elements, let’s move on to reproducibility challenges in machine learning.
Reproducibility challenges in Machine Learning
1. Lack of records
This is arguably the biggest challenge to reproducible experiments in ML. When inputs and new decisions aren’t recorded, it generally makes it hard to replicate the results achieved. While experimenting, parameters such as hyperparameter values, batch sizes, changes. Without proper logging of changes in these parameters, it becomes difficult to understand and replicate the model.
2. Changes in data
It’s almost impossible to get the same result when the data on the original work has been changed. For instance, when new training data is added to the dataset after the results have been achieved, it’s impossible to get the same result.
Incorrect data transformation(cleaning, etc) on a dataset, changes in data distribution, etc also affects the chances of reproducibility.
3. Hyperparameter inconsistency
When default hyperparameters are changed during experimentation and aren’t properly recorded, they will yield a different result.
4. Randomness
ML is full of randomization, especially in projects where lots of randomizations happen (random initializations, random noise introductions, random augmentations, selecting hidden layers, dropout, shuffling data, etc).
5. Experimentation
Machine learning is experimental, lots of iterations go into developing a model. Changes in algorithms, data, environments, parameters, etc are all part of the model building process, and while this is fine, it comes with the difficulty of losing important details.
6. Changes in ML Framework
ML frameworks and libraries are constantly getting upgraded on the go, a particular library version that was used to achieve a certain result might no longer be available. These updates can cause changes in the result. For instance, Pytorch 1.7+ supports mixed-precision natively from the apex library from NVIDIA but previous versions did not.
Also, changing from one framework to another (say, Tensorflow to Pytorch) will generate different results.
7. GPU floating-point discrepancy
Another challenge to reproducibility is different results from floating-point, either due to hardware settings, software settings, or compilers. Changes in GPU architectures also make reproducibility impossible unless some of these operations are enforced.
8. Nondeterministic algorithms
Nondeterministic algorithms, where the output is different for the same kind of input at different runs pose a greater reproducibility challenge. In deep learning algorithms such as stochastic gradient descent, Monte Carlo methods, etc non-determinism is often seen when during experimentations. Deep reinforcement learning is also susceptible to nondeterminism in the way the agents learn from a somewhat nonstationary distribution of experiences, which most times is influenced by non-deterministic environments and nondeterministic policies. Other sources of nondeterminism are GPUs, random network initialization, and minibatch sampling.
To overcome these challenges us, data scientists, must be able to:
- Track changes made in the code, data, and environment during experimentation.
- Record all the code parameters, data, and environment used in the experimentation.
- Reuse all the code parameters, data, and environment used in the experimentation.
Now let’s take a look at solutions and tools to solve this reproducibility challenge.
How Did We Get to ML Model Reproducibility
Solutions and tools to make ML projects reproducible
Experiments tracking and logging
Model training is an iterative process, changing the values of the parameter, checking each algorithm performance, and fine-tuning it to get ideal results, etc. During this process, without proper logging details would be lost, and like they say ”the beauty is in the details”.
During model training and experimentation you need to be able to keep track of every change that happens. Let’s take a look at some tools:
- With DVC, the dvc exp command tracks every metric along with the project, it has a metric list where it stores metric values to track progress. So you can track your experiments with automatic versioning and checkpoint logging. Compare differences in parameters, metrics, code, and data. Apply, drop, rollback, resume, or share any experiment. Check here for a more hands-on introduction to DVC experiments.
- neptune.ai allows you to log anything that happens during ML runs, including metrics, hyperparameters, learning curves, training code, configuration files, predictions (images, tables, etc), diagnostic charts (Confusion matrix, ROC curve, etc), and console logs. The tool is designed with a strong focus on collaboration and scalability, making it easy to reproduce experiments and share the results with team members, outside collaborators, or stakeholders.


- MLflow Tracking automatically tracks and logs parameters, metrics, code versions for each model run and deployment with the mlflow.autolog() function. This must be done before training and It saves each experiment logs both locally and remotely.
The Best MLflow Alternatives
- Pachyderm automatically reports anonymized usage metrics. It also keeps track of all the code and data used during model development.

- WandB allows you to track experiments, provides a dashboard where you can visualize experiments in real-time, and allows you to log hyperparameters and output metrics from every experimental run.
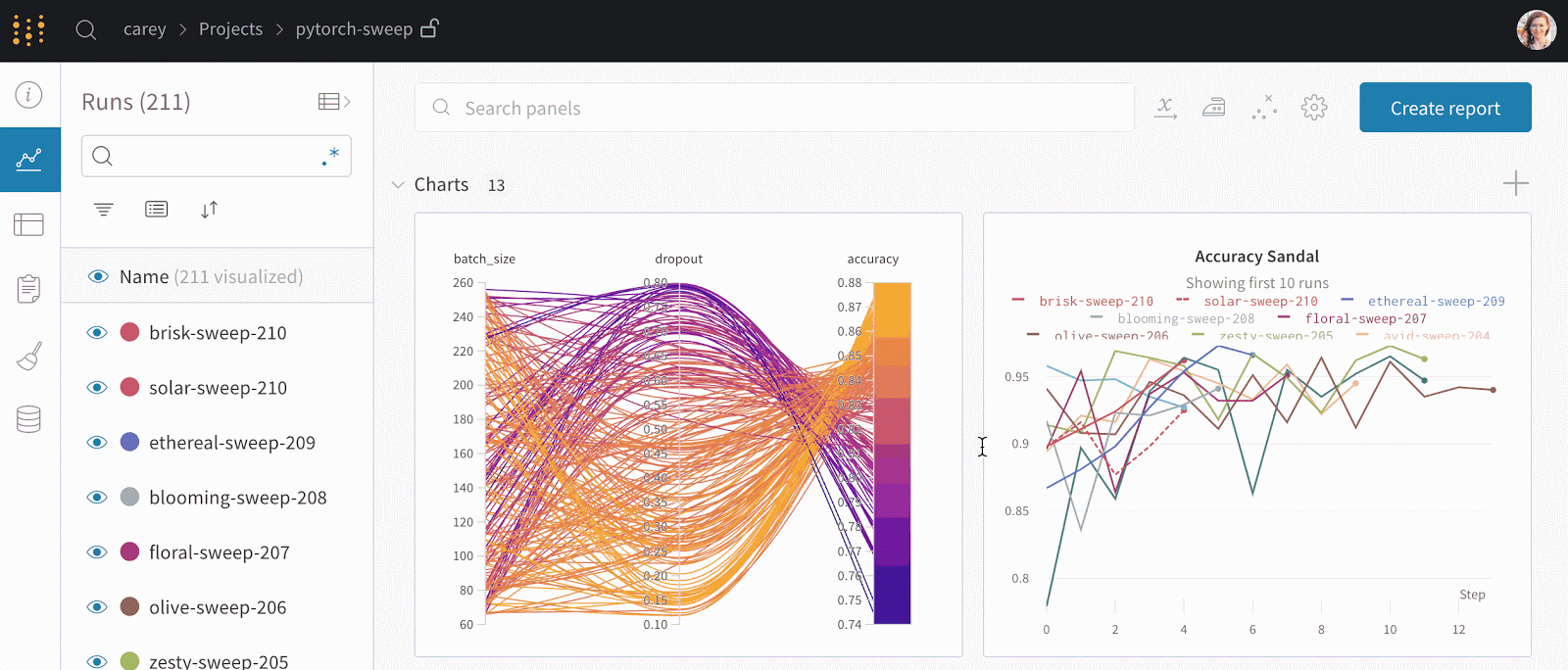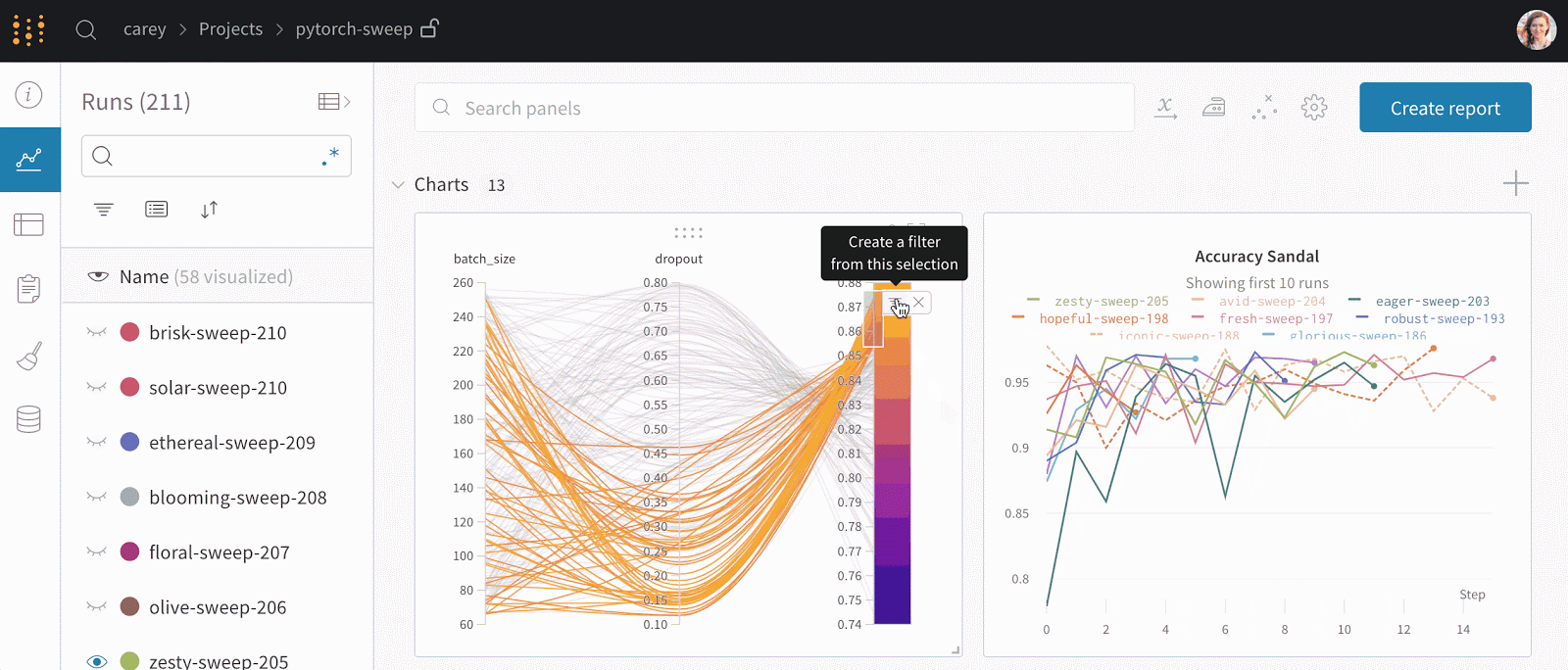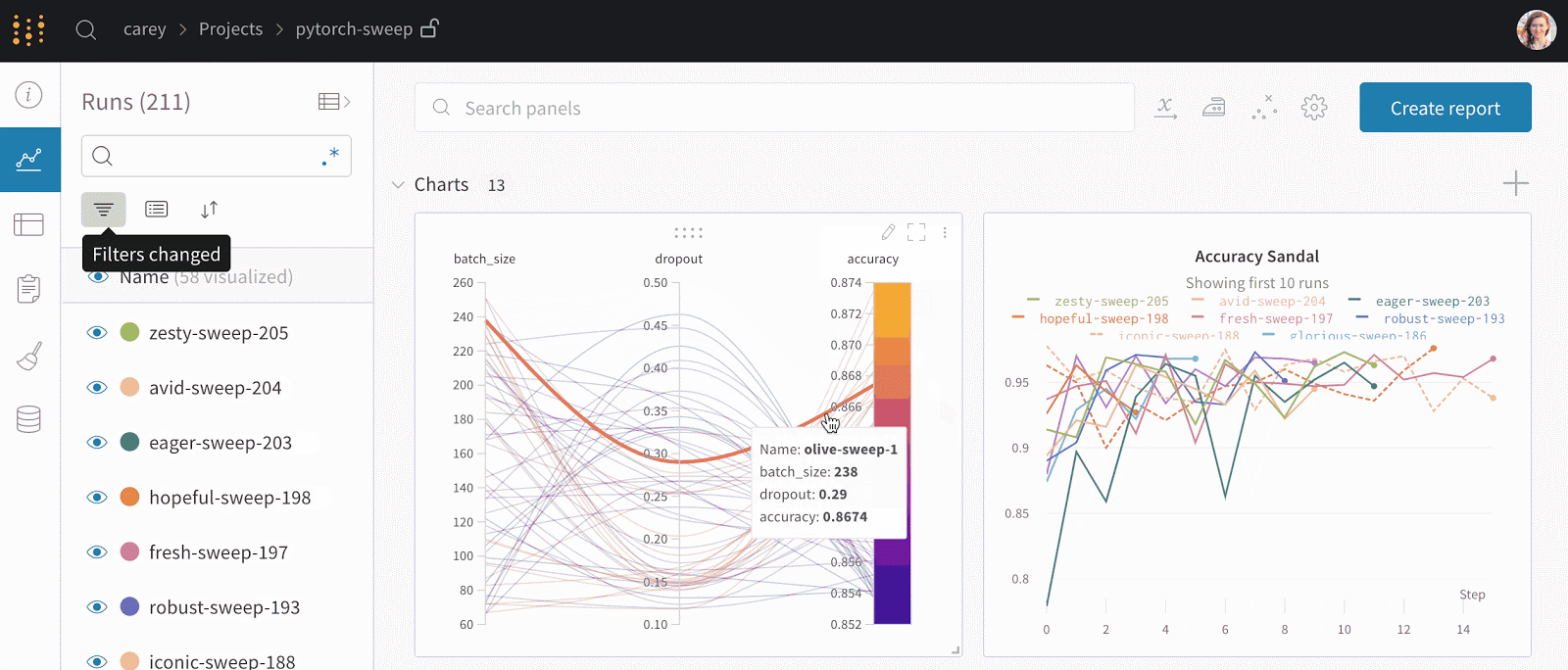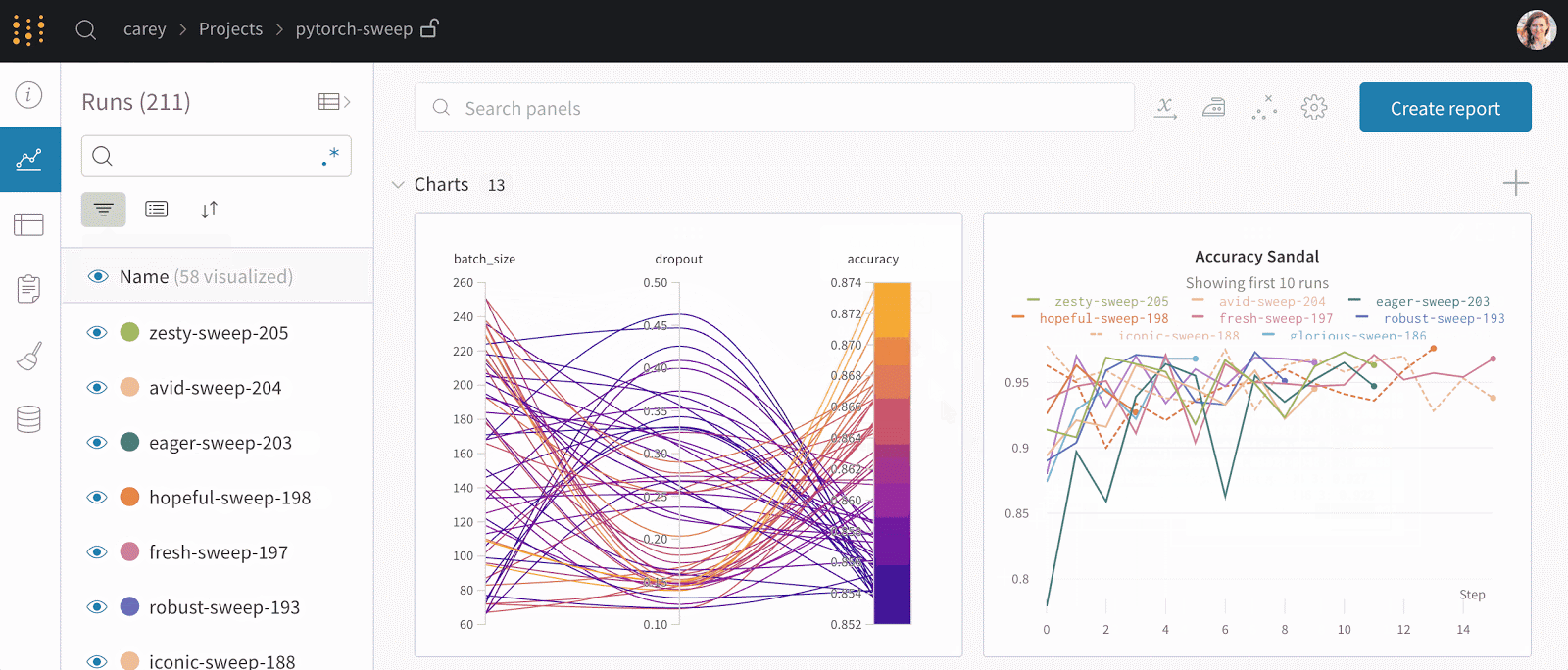
The Best Weights & Biases Alternatives
- Comet helps data science teams track experiment code, metrics dependencies, and more. It also helps to compare, explain and optimize experimental metrics and models across the model’s lifecycle.

The Best Tools for ML Experiment Tracking and Management
Metadata repository
Metadata in machine learning is the information that describes the dataset, computational environment, and model. ML reproducibility hinges on this, you can’t recreate experiments if you don’t record and store metadata. Some popular tools that can help you record and track any metadata and metadata changes:
- DVC does data and model versioning by creating metafiles as a pointer to stored datasets, models. These metafiles are handled using Git.
- neptune.ai has a customizable UI that allows you to compare and query all your ML metadata.
- TensorFlow Extended (TFX) uses the ML Metadata(MLMD) library to store metadata and uses APIs to record and retrieve the metadata from the storage backend; it also has reference implementations for SQLite and MySQL out of the box.
- Kubeflow Metadata store helps data scientists track and manage the huge amounts of metadata produced by their workflows.
Artifact store
An artifact in machine learning is data describing the output of a training process of a fully trained model or in ML terms, a model checkpoint. An artifact store logs every checkpoint in the model. Managing and storing every model checkpoint is important in reproducibility because artifacts make it easy for models to be replicated and verified by the ML team members. Tools such as :
- DVC can access data artifacts from outside of the project and how to import data artifacts from another DVC project. This can help to download a specific version of an ML model to a deployment server or import a model to another project.
- neptune.ai stores ML artifacts such as paths to the dataset or model (s3 bucket, filesystem), dataset hash/prediction preview (head of the table, snapshot of the image folder), description, who created/modified, when last modified, size of the dataset, etc.
- Amazon Sagemaker provides a model artifact store that stores the s3 bucket location of the model that contains information on the model type and content. Amazon Sagemaker also stores artifacts for AutoML experimentations.
- Kubeflow also stores artifacts data in its artifact store; it uses the artifact to understand how the pipelines of various Kubeflow components work. Kubeflow Pipeline can output a simple textual view of artifact’s data and rich interactive visualizations
- WandB allows you to create an artifact store for experimentations run using the following code.
artifact = wandb.Artifact('my-dataset', type='dataset')
- TFX Metadata also stores model artifacts generated in your ml pipelines and stores them via SQLite and MySQL. See diagram below

Version control
This is a software development tool that helps to manage changes made to code. A VCS reduces the possibility of error and conflict by tracking every small change that occurs in the source code.
If you work on a VCS-enabled project, you have the following:
- A version of every change made is recorded and stored, making it easy to revert to them in case of error.
- For every team member, a different copy of the source is maintained. It’s not merged to the main file until it gets validated by other team members.
- Information on who, why, and what changes were made to the project is recorded.
Git is the most popular example of a VCS for software development. Git is a free and open-source distributed version control system for tracking changes in any set of files.
Model versioning
Model versioning is the overall process of organizing controls, tracking changes in the model, and implementing policies for the model. Tools that can help in model versioning:
- DVC does data and model versioning by creating metafiles as a pointer to stored datasets, models while storing them on-premises or cloud. These metafiles are handled using Git. commands such as git commit, etc

- MLflow Model Registry is a centralized model store that allows you to automatically save and keep track of versions for registered models. You do so using the log_model method in MLflow. Once you log the model you can add, modify, update, transition, or delete the model in the Model Registry through the UI or the API.

- WandB offers automatic saving and versioning to every model built. The artifact of each model version is stored thereby creating a development history and also allowing us to use previous versions of a model. You can also use any other version by index or another custom alias.

Data versioning
Data changes from time to time, either during input or more training data is added. Data versioning means keeping track and recording every data change at any instance. Datasets can be updated, and trying to reproduce models with updated datasets will be impossible. With data versioning, you can keep track of every data
- DVC stores info about the data separately in an XML file and stores the data handling and processing which allows for efficient sharing. For large datasets, DVC uses a shared cache to store, version, and access the data on the dataset efficiently. Also for external data, DVC supports Amazon S3, SSH, HDFS.
- neptune.ai support many ways to log and display metadata about datasets. You can use Namespaces and basic Logging methods to organize any ML metadata in the app. Typically, people log the md5 hash of the dataset, the location of the dataset, a list of classes, and a list of feature names.
- Delta Lake brings reliability to your data lakes, unifies batch data processing in your experimentation run and it works on top of your existing data lake. It is compatible with Apache Spark APIs.
- Pachyderm version controls your data as it’s processed. It tracks data revisions and clarifies data lineage and transformation. It deals with plain texts, binary files, and very large datasets
- WandB allows you to store datasets in its artifact store and use its artifact reference to directly point to data in systems like S3, GCP, or locally hosted datasets.
- Qri is an open-source distributed dataset version control system that helps you clean, version, organize and share datasets. It can be used via the command line, desktop UI(macOS and Windows), and cloud. It records every change made to the dataset and saves them by stamp
The Best Data Version Control Tools That Improve Your Workflow With Machine Learning Projects
Data lineage tracking
Every model is a compressed version of the data it was trained on and data changes with time like new training data or changes in existing data make the model obsolete on its predictions, so changes to this must get tracked. This can be done with data lineage.
Data lineage is the process of understanding, recording, visualizing the changes and transformation of data from its source to final consumption. It gives every detail on how the data was transformed, what was transformed, and why it was transformed. Knowing the data lineage of a dataset helps reproducibility.

- MLflow uses Delta lake to track large-scale data used in the model.
- Pachyderm helps you find the data origins, then it tracks and versions it as it is processed during model development. Pachyderm also allows you to quickly audit differences in data version tracks and rollbacks
- Apatar uses visualization to show the flow of data from origin to end. It is an open-source extract, transform, and load (ETL) project for moving data across multiple formats and sources. It offers inbuilt data integration tools and data mapping tools.
- Truedat, an open-source data governance tool that gives end-to-end visualizations of the data from the model’s start to finish.
- CloverDX provides data lineage for your dataset with a developer-friendly visual designer. It is good for automating data-related tasks such as data migration and it does it fast.
Techniques such as pattern-based lineage, data tagging, and parsing can be used to track data.
Randomization management
As mentioned earlier, there is a lot of randomness in machine learning e.g random initializations, random noise introductions, random augmentations, selecting hidden layers, dropout, To overcome the randomness, set and save your environmental seed.
You can set seed values as follows:
import os
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
Or use the numpy pseudo-random generator to set a fixed seed value:
import numpy as np
np.random.seed(seed_value)
from comet_ml import Experiment
Or use the TensorFlow pseudo-random generator to set a fixed seed value:
import tensorflow as tf
tf.set_random_seed(seed_value)
You can also configure a new global `tensorflow` session:
from keras import backend as K
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
In pytorch:
import torch
torch.manual_seed(0)
It’s important that you set seed parameters to avoid random initialization, set the seed parameter for the framework you’re using. When working with GPUs, seed parameters might be ignored. But, it’s still important that you set and record your seed. Also, please don’t optimize your seed like a hyperparameter. To overcome randomness when splitting your data for training, test and validation, include the seed argument in your test_split_train code.
Model registry
Model registry is a tracking mechanism that records and stores all model metadata, lineage, and versioning logs. It captures the dataset used during training, who trained the model, what metrics were used to when the model was trained and when it was deployed for production.
- MLflow Model Registry allows you to register your model with a unique name, version, stage, and other metadata.

- Comet allows you to register your model either through its user interface or the comet python SDK.

Dependency management
It’s almost impossible to reproduce models without matching the same development environment and software libraries/frameworks the model was built. As you know ML frameworks are constantly being upgraded, so it is important to store and keep the info of the software version and the environment used in building the model. Tools such as Conda, Docker, Kubeflow, Pipenv, Singularity would help you store environment and software dependencies.
- Docker makes it easy to use a single environment with all your dependencies, frameworks, tools, and libraries needed to run your project. In docker, teams can easily build an environment using pre-built Docker Images which can be found in DockerHub.
- MLflow Projects allows you to pick a specific environment for a project and specify its parameters.
- With Kubeflow you can package the code, dependencies, and configurations of an environment in a container called Dockerfile
- Conda: Conda is an open-source environment and package management system. It allows you to quickly install, run and update packages and their dependencies. Conda easily creates, saves, loads, and switches between environments on your local computer.
- Pipenv: With Pipenv you can automatically create and manage virtual environments for your ml project.
Collaboration and communication
Building models or carrying out research involves teamwork, from the data engineer to the researcher and everyone involved in the process. Lack of communication would easily cause problems in the building process. So teams have to use tools that foster effective collaboration and communications among themselves. Tools like DVC, Github, neptune.ai, Comet.ml, Kubeflow, Pycharderm, and WandB allow teams to remotely collaborate and communicate effectively
- neptune.ai is an experiment tracker designed with a strong focus on collaboration and scalability. It allows teams to monitor months-long model training, track massive amounts of data, and compare thousands of metrics in the blink of an eye.
- Pachyderm offers collaborations across machine learning workflows and projects.
- WandB allows collaborations, you can easily invite people to edit and comment on a project.
- Comet lets you share and collaborate on projects with other people.
- Notebooks such as Colab, Deepnote also provide collaboration on model building.
Avoid non-deterministic algorithms
Non-deterministic algorithms display different behaviors on different runs for the same input and this is bad news for reproducibility.
- Pytorch allows you to avoid non-deterministic algorithms by using the torch.use_deterministic_algorithms(). This method returns an error whenever a non-deterministic algorithm is used.
import torch
torch.use_deterministic_algorithms(True)
- TensorFlow has a GPU-deterministic functionality and it can be accessed by the NVIDIA NGC TensorFlow container or Tensorflow version 1.14, 1.15, or 2.0- with GPU support.
For NGC tensorflow containers(version 19.06 – 19.09), it is implemented with as follows:
import tensorflow as tf
import os
os.environ['TF_DETERMINISTIC_OPS'] = '1'
For TensorFlow version 1.14, 1.15, and 2.0, it’s implemented like this:
import tensorflow as tf
from tfdeterminism import patch
patch()
Integration
Most MLOps tools might not have all the features required for successful end-to-end model orchestration(from model design to model deployment). Seamless integration of tools is a good thing for reproducibility.
Also, a lack of expertise on certain tools in a team would also cause the use of different tools for a project. It then makes sense that the tools used for such a project integrate properly with one another.
For instance:
- Docker integrates well with AWS, Tensorflow, Kubeflow.
- MLflow provides several standard flavors that might be useful in your applications, like Python and R functions, H20, Keras, MLeap, PyTorch, Scikit-learn, Spark MLlib, TensorFlow, and ONNX.
- Pachyderm can also deploy on AWS/GCE/Azure in about 5 minutes.
- WandB integrates well with PyTorch, Keras, Hugging Face, and more. WandB supports AWS, Azure, GCP, and Kubernetes.
Here’s a summary of some reproducible tools and their features:
You can check out these links for more tips on reproducibility when working on Notebooks:
- Tracking deep learning experiments in notebooks
- How to track and organize ML experiments that you run in Google Colab
Conclusion
Reproducibility is the key to better data science, and ML research, it is what makes your project flexible, and perfect for large-scale production.
When choosing tools for your next ML project, remember there’s no one-size-fits-all solution (especially if you’re not a fan of end-to-end solutions like SageMaker). The right choice of tools always depends on your unique context. Just make sure you have tools to track your code and computational environment, and also store your metadata, artifacts, and model versions.
Reproducibility, especially in research, makes it easier for others to collaborate, enables long-term growth for your project, and helps to properly establish institutional knowledge. But it’s equally important in business, where it can shorten your time-to-market and improve the bottom line.
