
You can’t deploy software based on a buggy model. Debugging is a big part of model development and deployment in machine learning.
Is there one silver-bullet strategy that works for all types of models and applications? Not really, there are plenty of different strategies for model debugging, and we’re going to explore 10 of them in this article.
Model debugging explanation
When you’re debugging models, you’re discovering and fixing errors in the workflows and outcomes. For example, debugging can reveal cases when your model behaves improperly, even when its specification is free of internal errors—debugging can also show you how to improve issues like this.
Why do we need debugging?
Debugging is a key part of software development, regardless of what type of software it is—so, naturally, it also applies to machine learning.
In machine learning, poor model performance can have a wide range of causes, and debugging might take a lot of work. No predictive power or suboptimal values can cause models to perform poorly. So, we debug our model to find the root cause of the issue.
Models are being deployed on increasingly larger tasks and datasets, and the more the scale grows, the more important it is to debug your model.
What are the general steps for debugging?
Debugging steps in the software world
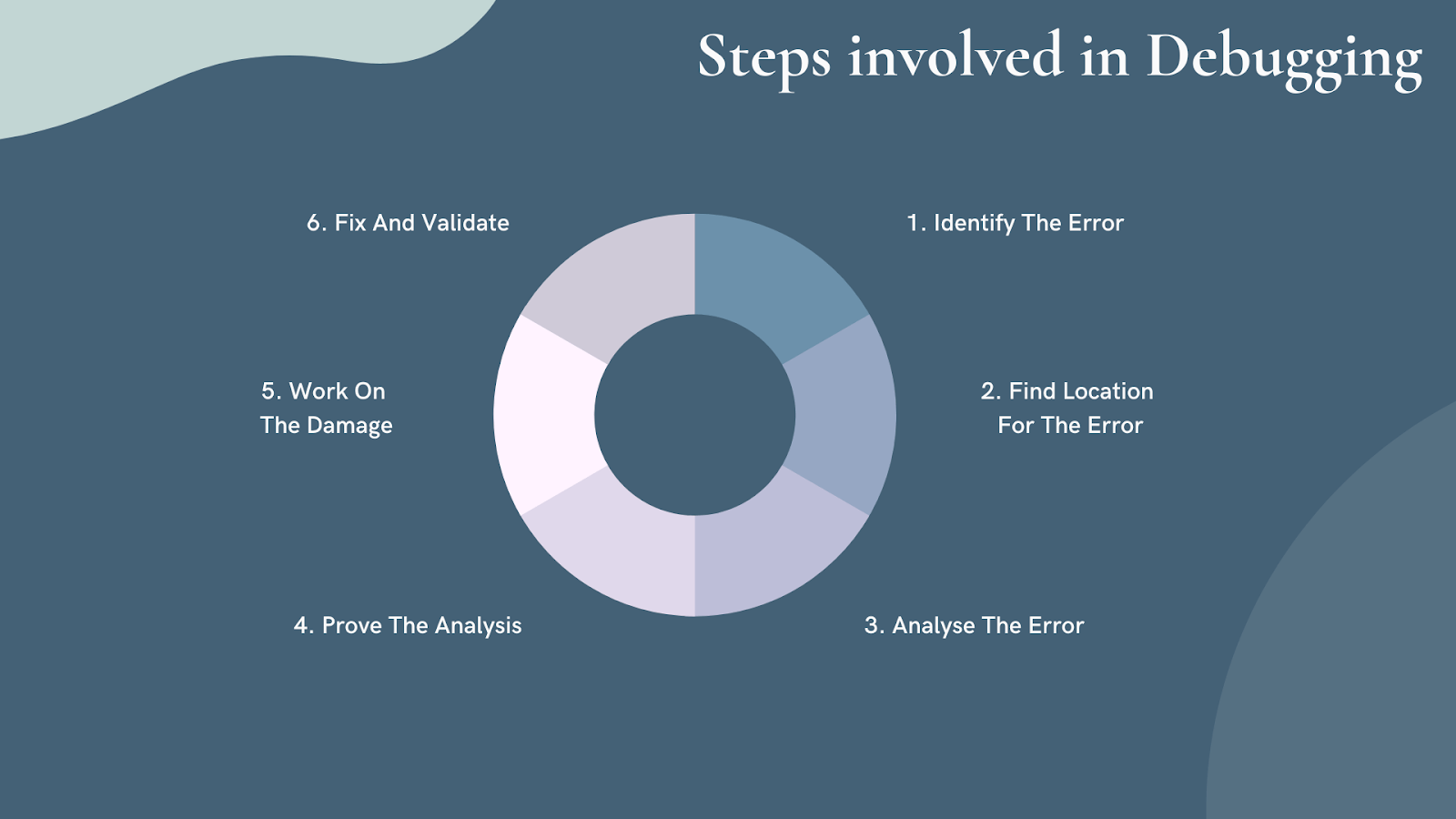
- Identify the Error: To fix the issue, you need to know that you have an issue in the first place. There are plenty of ways to identify errors, like performance monitoring and user feedback.
- Locate the Error: It’s time to see where exactly the error is happening. Inspect the system thoroughly to find it.
- Analyze the Error: Analyze the code to identify more issues and estimate the risk that the error creates.
- Prove the Analysis: Work with automated tests, after analyzing the bug you might find a few more errors in the application.
- Work On the Damage: Collect all test units for the program where you’ll be making changes. Now you can run test units and monitor their performance.
- Fix and Validate: Fix the issue, run all test units, monitor performance.
These debugging steps work perfectly in the conventional software world. Is debugging in machine learning or AI different?
When you debug an ML or AI model, you don’t focus on the code that much. You have to go deeper to determine why your model performs badly.
Bad performance might happen because of suboptimal values in hyperparameters, or dataset issues, or lack of predictive power. There are many reasons for bad model performance, and there are also many strategies for debugging machine learning models.
We’re going to explore popular techniques used by developers and data scientists to find bugs in machine learning models and ways to improve them. But before we do, let’s explore different types of bugs.
Common bugs in machine learning models
- Dimension error
The most common issue in models is the dimension, which happens because of the nature of linear algebra. Most popular libraries can spot inconsistent shapes. While working with matrices, let’s say we use shape(n1,n2)(n3,n4) so in matrix multiplication, it is important to match n1 and n3 dimensions for the matmul to work. It’s also critical to find where they’re coming from.
If you want a model summary like Tensorflow for Keras in PyTorch, just use:
!pip install torchsummary
It’ll display results in the table format for each layer.
- Variable
Data goes through a long process starting from preparation, cleaning, and more. In this process, developers often get confused or forget correct data variables. So, to stay on the correct path, it’s good practice to use a data flow diagram before architecting our models. This will help us find the correct data variable names, model flow, and expected results.
- Flaws in input data
To figure out if our model contains predictive information or not, try with humans first. If humans can’t predict the data (image or text), then our ML model won’t make any difference. If we try to feed it more inputs, it still won’t make a difference. Chances are that the model will lose its accuracy.
Once we get adequate predictive information, we need to know if our data is adequate to train a model and get the signal. In general, we need a minimum of 30 samples per class and 10 samples for specific features.
Size Of Dataset ∝ Number Of Parameters In Model
The exact shape of the above equation depends on your machine learning application.
- Learn from minimal data
When you work on machine learning projects, you might not have enough data. A good method to solve this is to augment your data. You can generate new data with generative models and generative adversarial networks, such as autoencoders. Autoencoders help to learn structured data codings in an unsupervised manner.
External data, let’s say data found on the internet or open-sourced, can be useful. Once you collect that data and label it, you can then use it for training. It can also be used for many other tasks. Just like external data, we can also use an external model which was trained by another person and reuse it for our task.
Using a high-quality but small dataset is the best way to train a simple model. Sometimes, when you use large training data sets you can waste too many resources and money.
- Preparing data and avoiding the common issue
When preparing features, it’s crucial to measure the scaling factors, mean, and standard deviation on the test dataset. Measuring these will improve the performance on the test data set. Standardization will help you make sure that all data has an SD of 1 and a mean of 0. This is more effective if the data has outliers, and it’s the most effective way to scale a feature.
- Hyperparameter Tuning
Hyperparameter tuning is about improving the hyperparameters. These parameters control the behavior of a learning algorithm. For example, learning rate (alpha), or the complexity parameter (m) in gradient descent optimization.
A common hyperparameter tuning case is to select optimal values by using cross-validation in order to choose what works best on unseen data. This evaluates how model parameters get updated during the training period. Often this task is carried out manually, using a simple trial and error method. There are plenty of different ways to tune hyperparameters, such as grid searches, random search methods, Bayesian optimization methods, and a simple educated guess.
- Logging
Logging is a way of monitoring any issue, but it’s best not to log useless information. Sometimes it’s very important to comment/log all the decisions and information that is exchanged. This might be difficult, but it should be possible to map out all possible scenarios and put logging to solve that.
The important details are, for example, values from arguments, runtimes types from classes, software decisions, and more. This depends on the type of your issue.
- Verification strategy
With verification strategies, we can find issues that aren’t related to the actual model. We can verify the integrity of a model (i.e. verifying that it hasn’t been changed or corrupted), or if the model is correct and maintainable. Many practices have evolved for verification, like automated generation of test data sequences, running multiple analyses with different sets of input values, and performing validation checks when importing data into a file.
Let’s get deeper, and explore the most used and important strategies used by developers and data scientists to find bugs in machine learning models.
Most-used model debugging strategies
Sensitivity analysis
Sensitivity analysis is a statistical technique that estimates how sensitive a model, parameter, or other quantity is to changes in the input parameters from their nominal values. This analysis shows how a model reacts to unseen data, and what it predicts from given data. Developers often refer to it as the “What if” analysis.
Suppose we have a model that predicts housing prices will rise by 10% given a 10% rise in a specific area. To see if this is true, we simulate data where the population increases by 10%. If predictions are correct and housing prices increase by 10%, it’s done. However, if the prediction is off, for example, the predicted value of housing doesn’t change, then the model is sensitive to changes in one or more of its input variables. With sensitivity analysis, we can figure out which input variable(s) are causing the problem. What if the prices increase by 10%, 20%, or 50%? It will help us demonstrate that prices are sensitive to changes in buyer traffic.
The example above is a prediction of an unknown quantity (housing prices). For models that make predictions about known quantities (e.g. the stock market), sensitivity analysis is even more important. The What-if-tool is the best way to visually monitor the behavior of trained ML models, with minimal coding.
Sensitivity analysis will help us study all the variables in depth. Because of this, predictions become more trustworthy. It also helps developers to recognize what could be improved in the future.
Residual analysis
The most used method among data scientists and developers. It’s a numeric evaluation of model errors and the difference between observed and predicted outcomes. Residual plots are very helpful in determining where a model is wrong (misclassifying data points). In simple terms, residuals can be calculated by subtracting predicted values from observed values.

Residuals = Observed Values (Inflation for above image) – Predicted values
So, let’s take the case of June 2020. The observed value of inflation was 2.2% and the predicted value of the model is 1.9, so the residual is 0.3. A small residual value often means the model is correct, and a large residual value often means that something is wrong with the model.
The plot of a residual analysis can be easily understood as a 2D plot in which the horizontal axis represents the input data and the vertical axis represents the prediction or predicted outcome. Essentially, residual analysis plots similarities between different numbers to determine if anomalies are present. Often, these anomalies are important bugs on which model debugging techniques such as breakpoints can be employed. Residual plots make it easy to visualize just how close or far apart two variables are within a dataset. They also give us insights into quality problems, such as outliers, that may potentially distort predictions and cause more harm if left unchecked. Look for patterns created for residual values. We’ll be able to understand a lot about our model with the patterns.
Residuals are crucial when it comes to evaluating the quality of a model. When residuals are zero, it means that the model prediction is perfect. More or fewer values mean less accuracy of the model. When the average residual isn’t zero, it means the model is biased or might have an issue. Diagnosing residual plots in linear regression models is often done with the following two graphical methods.
- Quantile Plots: The quantile plot is a graphical representation to see if the distribution of residuals is standard or not. It’s a plot of the quantiles of the actual and normal distribution. If the graph is overlapping on a diagonal, then it’s normally distributed. It helps us to test many distributional aspects.
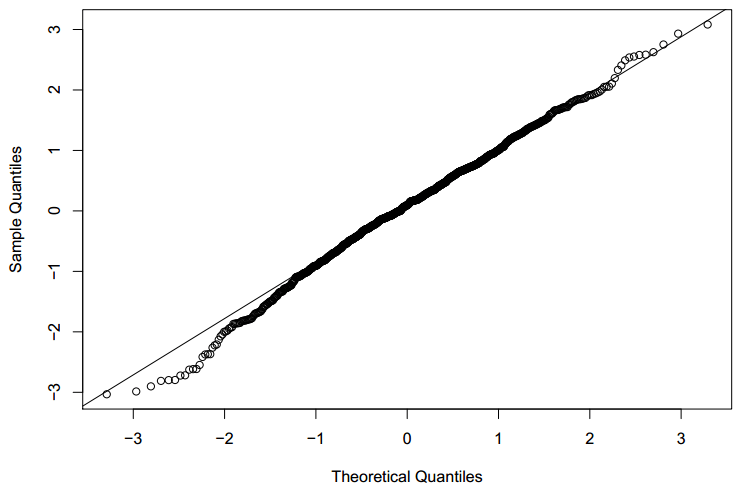
- Scatter Plots: The Scatter plot is a graphical representation to evaluate variance and linearity. The two dots depict two different values. They can help us visualize how two or more variables relate to each other. It’s often an effective way to analyze data and evaluate the relationship between two or more items. Another advantage is that building a scatter plot requires minimal math skills and provides a good sense of understanding about what we’re seeing in the data.

Benchmark models
A Benchmark Model is the most easy-to-use, reliable, transparent, and interpretable model that you can compare your model with. It’s best practice to check if your new machine learning model performs better than a known benchmark in test datasets.
A Benchmark model is easy to implement and doesn’t take much time. Use any standard algorithm to find a suitable benchmark model, and then just compare the results with model predictions. If there are many common features between standard algorithms and ML algorithms, a simple regression might already reveal possible problems with the algorithm.
Additionally, benchmark models can be used to estimate how our ML model will perform on different data classes. For example, if we’re surprised that our ML model is overfitting on some data, a benchmark model can help us understand whether it’s because the data is special or not.
Security audits
There are many attacks against machine learning models which can impact the model results and datasets. Commonly used assessment practices don’t tell us if a model is safe or not.
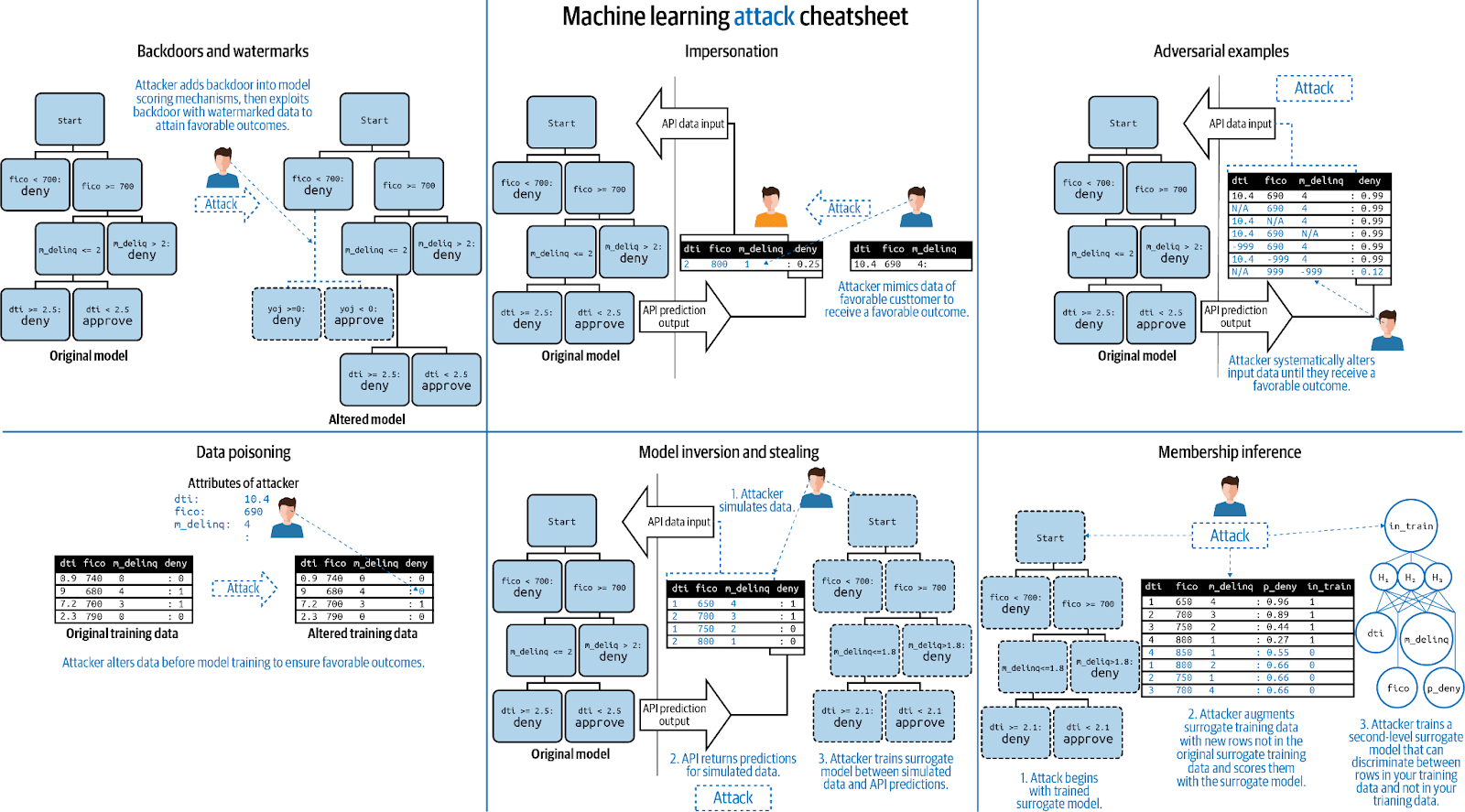
There are plenty of ways to audit machine learning models to ensure that they are safe. Some attacks can be launched using synthetic data and their analyses become very challenging when they’re combined with real machine learning models.
This is most applicable where the attacker has access to the training set that was used for developing a model. All the data, documentation, and information should only be accessible to authorized members. All the data should remain accurate. We need to make sure that we do routine backups, version control, and all the security measures to keep data secure.
Data augmentation
Data augmentation is a machine learning technique that can help us implement missing data. At its most basic definition, data augmentation is a method to add new training samples to fill in places where we have gaps in our dataset.
We can augment:
- Audio
- Text
- Images
- Any other types of data
Machine learning solutions combine a set of data with the mathematical equations that transform this available data into conclusions about the answers we want to find.
One of the most common uses for data augmentation is to fill missing data gaps within our training dataset. It’s common in ML problems to have a training dataset (and possibly a validation dataset) that doesn’t have every possible answer (or parameter of an algorithm).
But there can be many answers or parameters that may ‘predict’ correctly from the available data, which are missing from our dataset but required by the model. For example, for images, we can use
- Geometric transformations,
- Color space transformations,
- Kernel filters,
- Random Erasing,
- Mixing images.
For text, there’s word shuffling, replacement, and Syntax manipulation. For audio noise injection—shifting, speed of audio, and more.
Check also
Data Augmentation in Python: Everything You Need to Know
Data Augmentation in NLP: Best Practices From a Kaggle Master
Model editing and monitoring
Model editing is a technique where machine learning models are designed for human users to be able to understand how they work and edit them. This is done for the models to perform well in the future, as some ML variants are designed to be interpretable by humans, like decision trees and GA2M. Chances are other models might be hard to edit, but if they’re capable of generating a readable outcome, they can be edited.
Monitoring and managing our machine learning model is an important part of the workflow. We have to keep track of who and when trained the models. We have to keep records of all the datasets, inputs, and predictions.
These things aren’t static and can change drastically over time, so it’s important to monitor our models. Let’s say our model seems to be working pretty fine — did we think about what would happen if this weren’t the case? How will we know when our models are no longer calibrated with reality?
No one likes surprises, so it’s best not to wait with monitoring and calibration. It may be that we have a new data set with new information, and we want to see how it changes our model. Or perhaps there’s a serious issue with our model that needs to be corrected. Whatever the case may be, we’ll need a way of checking whether or not we should re-optimize and calibrate.
May be useful
Model assertions
Model assertions help improve or override model predictions in real-time. In the context of machine learning modeling, a business rule can help the model meet its specified goals by detecting when it fails predictions or behaves unexpectedly. This can be beneficial for many reasons, but the main benefit is that goal-oriented business rules allow models to provide different levels of response depending on what action is needed at the time, so they’re more likely to behave as expected in unpredictable situations.
Model assertions have many advantages over other implementation methods. They easily handle the addition of new rules to an already deployed model compared to application integration methods, as there’s no need to make changes to the machine or any other applications on the machine. Assertions can also be easily evaluated by evaluating whether the rules that they enforce are being followed and how accurate they are. As a result, model assertions can be more accurate than business rules implemented via application integration with less effort.
Anomaly detection
Anomaly detection is a powerful security measure, one that allows organizations to detect anomalous behavior as it develops. Anomalies may include anything from unusual transactions occurring in an organization’s financial network to a hacker stealing money or data from the company. It’s very similar to other methods of fraud detection, but rather than just looking for known fraudulent transactions or patterns, it also looks for anomalies and outliers in those patterns. This means that anomalies can be detected even when they haven’t been seen before.
Read also
Model visualization and debugging with neptune.ai
Neptune is an experiment tracker built with a strong focus on scalability. The tool is known for its fast, user-friendly interface and the ability to handle model training monitoring at a really large scale (think foundation model scale). Neptune enables AI researchers and engineers to log, monitor, visualize, compare, and query all their model metadata in a single place. With its reporting feature, it also improves team collaboration by making sharing project milestones or results with team members and stakeholders easy.
How visualization can help in debugging?
Many programmers will agree that debugging is one of the most difficult parts of programming. It requires a high level of concentration, constant attention to detail, and a fair amount of patience. It also can be very time consuming. Visualization techniques often help programmers tremendously by spotting areas in code that can feel like a mystery from their perspective.
That said machine learning visualization is an important part of computer programming–it allows data scientists to observe input and output values which result from the execution of a program. A common problem with development is the lack of understanding how programs work when they produce incorrect results. Debugging tools help with this by giving us perspective on what a program is actually doing and it’s outputs–specifically for visualizations, we are given insight into what different data points look like, allowing us to see why certain parts of our code are or aren’t working correctly. With the right visualization techniques, we can see exactly where errors are coming from and what data is being modified during a run, allowing us to fix our code before it’s too late.
Ways to improve model performance
There are many ways to improve model performance but we’ll only discuss a few top-ranking methods.
More Data: Adding more data is the best method to improve model performance. Resampling, cleaning, and getting more data also boosts the performance. Sometimes, you can’t add more data — but you can still create more data or get data from external sources. Adding more data is the best way to boost model performance.Feature Engineering: Simple process of transforming raw observations into desired features with the help of statistical or machine learning techniques. It’s always a good idea to add new features to your model, as it improves flexibility and decreases the variance. When working with feature engineering, you need to make sure you have a good amount of data and a good budget. You should be able to afford this.
Feature Selection: Imagine your data is like a large forest of trees. Feature selection is the process of walking through this forest and deciding which trees you want to keep, based on characteristics like height, width, or color. This analogy can be applied to data that you’re analyzing, filtering, or sifting for information. In order to extract useful information from data sets, it’s important to determine which features in the dataset we want to analyze further. We may not need all of the features. We might only need one or two out of many, so it’s important we choose intelligently and discard the rest before they take up valuable processing time in our machine learning training algorithm.
Multiple Algorithms: The goal here is to improve performance by using multiple algorithms and aggregating their outputs. A well-known example is Google’s search engine that uses many different statistical models for its results. You might think there would be no point in using more than one model if they’re all going to produce similar answers, but it turns out that there are some surprising benefits to doing so — even on a single day’s worth of data.

Algorithms Tuning: Model development is a process of trial and error. One of the most important parts of this process is tuning your algorithms to find the ones that are best for you. Tuning algorithms takes a good amount of time, it can take weeks or months to spot a good-performing algorithm. In the end, it’s worth all the time and effort you put into it.
Ensembles: The most used and most effective method. It combines prediction data of weak models and produces better outcomes. There are many ways to do this method. You can create multiple models with the same or different algorithms, or you can generate multiple subsamples for the training data and combine predictions to get better-performing algorithms.
Cross-Validation: The term cross-validation is used to describe the process of taking an algorithm and applying it to test data that hasn’t been used in training the algorithm. In machine learning, this typically means taking an unlearned model and running it on a validation set of data, which is then compared with the original training set. Cross-validation can be done using “leave-one-out” or repeated cross-validation schemes.
Conclusion
Model debugging can be a difficult, time-consuming task. Models are built with many different variables, and typically have layers of abstraction that make debugging difficult.
We saw what model debugging is and why we need it. We also discussed a few common bug types, and the most used model debugging practices. You can try these techniques and make your machine learning model more trustworthy, with better performance.
Hope you enjoy the article, stay safe!
Additional research and recommended reading
- https://www.edureka.co/blog/what-is-debugging/
- https://www.cs.cornell.edu/courses/cs312/2006fa/lectures/lec26.html
- https://www.investopedia.com/terms/s/sensitivityanalysis.asp
- https://towardsdatascience.com/strategies-for-model-debugging-aa822f1097ce
- https://jphall663.github.io/GWU_rml/
- https://cs.stanford.edu/~matei/papers/2018/mlsys_model_assertions.pdf
- https://blogs.oracle.com/ai-and-datascience/post/introduction-to-anomaly-detection
- https://www.analyticsvidhya.com/blog/2015/12/improve-machine-learning-results/
- https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
