
Version control tracks and manages changes in a collection of related entities. It records changes and modifications over time, so you can recall, revert, compare, reference, and restore anything you want.
Version control is also known as source control or revision control. Each version is associated with a timestamp, and the ID of the person making the changes in documents, computer programs, files, etc.
Various application types embed the concept of version control, like Sharepoint, Word, spreadsheets, Photoshop, and more. Version control prevents conflicts in concurrent work, and enables a platform for better decision-making and fostering compatibility.
Version Control Systems (VCM) run as stand-alone software tools that implement a systematic approach to track, record, and manage changes made to a codebase. It facilitates a smooth and continuous flow of changes.
In this article, we’re going to explore what version control means from different perspectives.
Types of version control systems
There are three main types of version control systems:
- Local Version Control Systems
- Centralized Version Control Systems
- Distributed Version Control Systems
Local Version Control System
This version control system consists of a local database on your computer that stores every file change as a patch (difference between files in a unique format). To recreate the file, the various patches will be required to add up at any point in time.
One of the popular examples of this system is the Revision Control System (RCS), still distributed with many computers today. One of the downsides of this system is the local storage of changes. If the local disk/database is damaged or corrupted, all patches will be consequently affected. Also, collaboration in this system is complex, nearly impossible.

Centralized Version Control Systems
This system has a central and single server that stores the different file versions. This system consists of a server and a client(s). Multiple clients can access files on the server simultaneously, pull current versions of files from the server to their local computer, and vice versa.
There’s just one repository that contains all the history. This approach supports collaboration, and it’s easy to track team member roles on a project. Every change goes to the central server and immediately influences the master code, which will be in production as it’s a simple commit and update process.
Due to how everything is stored on a centralized server, if the server is damaged or corrupted, there’s a high risk of losing the project’s entire history except whatever single snapshots people happen to have on their local machines. Examples of centralized version control systems are Microsoft Team Foundation Server (TFS), Perforce, and Subversion (SVN).

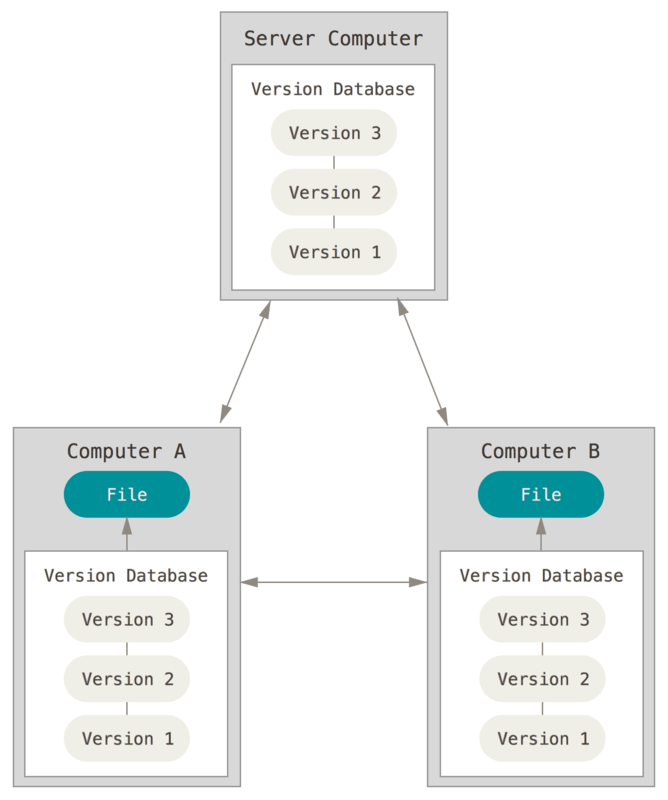
Distributed Version Control Systems
In this system, there’s no central repository, but rather multiple repositories. Every client has their server and thoroughly mirrors/clones the repository, including its entire history. This system makes every collaborator a local copy of the whole project, making it easy to work locally and offline.
Committing changes is unique to the client’s local repository, and requires it to be pushed to the central repository (which is authoritative). For other team members to get the changes, they have to pull those changes before effectively making updates.
If the server becomes unavailable, damaged, or corrupted, any of the clients’ repositories (a correct copy) can distribute or send a copy of the project version back to the server or any other client. Examples of distributed version control systems are Git and Mercurial.
Benefits of version control systems
- Efficient team collaboration and concurrency, as multiple people can work simultaneously on a given project. The concepts of branching and merging drive this collaboration.
- Access to traceability of all changes/modifications made to a given project. This traceability enables root cause analysis, forensics analysis, and insurance against downtime, crashes, or data loss. It helps manage source code and assets.
- It fosters effective integration of teams’ simultaneous work, and reduces the possibilities of error and conflict.
- It serves as a single source of truth (SSOT) across digital assets, teams, and source code.
- It empowers clients with the leverage to use multiple computers to work on a project.
- It improves development speed as improvements are incorporated faster with the help of Continuous Integration (CI). It also accelerates product delivery aided by better communication with team structure.
Version control in software engineering VS data science
Software engineering and data science aren’t very different. There are moderately overlapping and interrelated fields that are similar in many ways. One of these similarities is the concept of version control.
In software engineering, version control systems (VCS) manage, track, and store the history and state of the source code, the artifacts (by-products of software development), and documentation. Nowadays, software developers commit their projects progressively (irrespective of the programming language) to a version control system like Git, usually with meaningful commit messages. Versioning source code is standard practice.
Data science, on the other hand, is more of an exploratory working style. Productizing data science involves translating insights from exploratory analysis into scalable models that drive the building and development of data and AI-driven products, and services that provide value.
While productizing these products and services, these artifacts become more complex than file dependencies to datasets, models, metrics, and parameters. You must understand the various artifact changes to build responsible and robust data and AI-driven applications.
To understand version control in data science with the respective artifacts, let’s further discuss using a motivating example – a recommendation system.
Recommendation systems are information filtering systems that try to suggest information relevant and interesting to the end-user. The suggestion considers knowledge and data to adequately predict the preference or rating the end-user would assign to an item.
Recommendation systems filter a mountain of content and make personalized recommendations to users. We use them all the time when browsing Netflix, Youtube, Spotify, Amazon, Linkedin, Pinterest, and more.
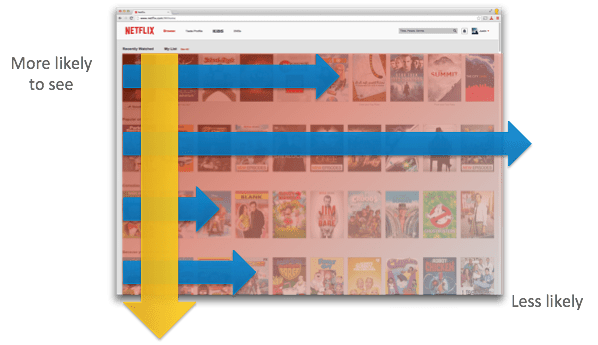
Netflix has a powerful recommendation system that accounts for over 80% of what its customers watch. Machine learning drives these recommendations using data inputs that cut across:
- Demographic data of users such as age, gender, location and selected favourite content upon sign up
- Device type used to stream movies
- Completion rate and time of movies
- Frequency of searches and results
- Re-watching movies
- Movie paused, rewound, or fast-forwarded time
- Credit calculation
- Nature of the watched programs
- Watch history and timestamp
- Rating
- Browsing and scrolling behavior
The recommendation engine filters over titles using some predefined recommendation clusters based on user preferences. The machine learning components are frequently updated, and various experiments are initiated. New updates to models may be released every day, or every few minutes, as users continuously generate data.
Different users tend to see the results of other models as part of A/B experiments or canary releases. These updates challenge figuring out which model made a specific prediction or which data produced certain models.
Let’s discuss a hypothetical case where the Netflix recommendation engine suggests 18+ rated movies to a minor. Netflix machine learning engineers will quickly start investigating such recommendation patterns, as it poses a potential problem that could negatively affect the company brand and possibly scare away customers.
Firstly, to explore this problem, it needs to be reproduced first. With the customer data stored in some database, the first question is: if we use the same input again, will we get the same result? Can we reproduce the results? If we can’t, why?
Is there nondeterminism in the machine learning operation, like preprocessing, feature selection/extraction, or other parts of the workflow? Or has there been an update on the model that predicted the instance under investigation?
We need to track and identify the model version used. We need to know if we were running experiments and if the customer was part of any specific experiments that may yield a different model. Do we still have access to that model? Did we record the testing phase, and who approved the release? Are models chained? These are just some of the questions we can ask on the model side of things.
Assuming we find the model that made the prediction, this will draw more questions, like what data was used to train and test the model? What were all the versions of the machine learning libraries? What hyperparameters were used for tuning the model? If the training should be repeated, are we going to get the same model?
Now, let’s further assume that we’ve identified the exact dataset used for training; this will also raise some questions. What’s the source of the data? What preprocessing steps were carried with what version of code? Was the dataset output of another model? Who was involved in the data modification?
It’s vital to monitor and trackback the origin and lineage of data, model, and pipeline code. Either for accountability, debugging, or investigation purposes, clarity on the following question (and not only these) is essential:
- Can we reproduce the observation we’re investigating?
- Can we identify the inputs of different models rolled out to production?
- Can we track the different model versions that have been used in production?
- What data was used to train and test a given model?
- Can we recreate the model?
- Was model chaining applied? If yes, what were their respective versions, and based on which data?
- What are the data sources?
- How was the data preprocessed?
- What are the hyperparameters used to tune the models?
- What is the learning code for the model?
Versioning data
Before we explore data versioning with different strategies, let’s discuss what “data provenance” is. Data provenance is simply tracking the origin and changes over the history of data. Data provenance is also known as data lineage.
These changes come in processing/editing steps in a machine learning pipeline, such as data acquisition, merging, cleaning, transformation learning, and deployment. Inadequacy in data provenance yields “visibility debt” (which is vague visibility into data dependencies and history).
Data provenance also covers governance and management in tracking who made data changes or modifications. The data is composed of individual independent variables that serve as input. We need to trace how the features in the training and testing data are changed as well, hence yielding the concept of feature provenance.
Some of the strategies for versioning data are as follows:
- Caching copies of datasets: Here, every change to a dataset yields storing the new copy of the entire dataset. This strategy provides easy access to individual versions of data, but the memory constraint of small changes to big data will require additional storage. With a name convention for files in a given directory, this strategy is readily implementable. An excellent example of VCS that uses this strategy is Git.
- Storing the difference between datasets: This strategy store only changes between versions due to the memory constraint discussed above. These changes or differences are stored in patches, so restoring to a specific version will require adding all the patches to the dataset. Some good examples of VCS that use this strategy are Mercurial and RCS.
- Storing the changes on individual records: Here, rather than keeping modifications on the entire dataset, individual instances/records are in focus. This strategy is implemented by having individual history per record documents that track changes on each record. The implementation is by creating a separate file for each record, which combines to form an “individual history per record” directory that tracks all changes on individual parts. Several databases can track provenance information of changes on individual-level (or case-based). This approach is easily implemented on structural data. A good example that utilizes the method is the Amazon S3 bucket.
- Offsets in append-only datasets: This works with the theory that existing data is immutable and changes with new data are required to be appended to existing data. Here, the file size (offset) is used to track changes. This strategy needs to be utilized on append-only data such as event streams or log files. This is the simplest form of data versioning. An excellent example of a system that uses this technique is Apache Kafka.
- Versioning pipelines to recreate derived datasets: This strategy involves versioning the original dataset and all processes/transformation steps (data cleaning, integration, wrangling, smoothing, encoding, and reduction stages) in a machine learning pipeline. It’s more efficient to recreate the data on-demand than to save it.
The choice of strategy depends on the size, structure, and frequency of updating the data. A tradeoff exists among the different approaches regarding how expensive it is to store the data (storage space) and recreate (computational effort) the data. It’s also best practice to version available metadata alongside the data.
Read more
Best 7 Data Version Control Tools That Improve Your Workflow with Machine Learning Projects
Versioning machine learning models
Due to the exploratory and collaborative nature of data science or machine learning projects that involve rapid experimentation and iteration, tracking model history is essential to understand and improve the performance of these developed models. Just like data, model provenance is about tracking model inputs, hyperparameters, and learning code with dependencies, algorithm choice, and architecture. These models are usually large binary data files as it serializes its parameters.
As mentioned earlier, machine learning operations are an iterative process to find the best model. In most cases, small changes to hyperparameters or data yield changes to several model parameters lead to different models.
Different models don’t share structure or parameters as they can be created from various machine learning algorithms, so tracking models based on their difference as data wouldn’t be all for meaningful analysis or storage. Hence, tracking the version of these binary files will suffice only with the storing copies strategy like Git and DVC.
Read more
Version Control for ML Models: Why You Need It, What It Is, How To Implement It
Versioning machine learning pipeline
A machine learning pipeline is a workflow with various interdependent sequential stages that lead to a machine learning model. Here, we want to track the learning code for the different stages such as data preprocessing, feature extraction and engineering, model training, and hyperparameter optimization. This versioning is crucial for model provenance.
These pipeline code and hyperparameters are expressive as script files and configuration files that can be versioned like traditional source code. Tracking frameworks and library versions is also essential to ensure reproducibility and avoid floating versions for dependencies. These libraries and framework dependencies can be versioned using package managers like pip to create requirements.txt files.
Also, pipeline code and dependencies can also be packaged in virtual execution environments to ensure that environmental changes are tracked. Docker is an excellent example.
Versioning machine learning experiments
Experiments in machine learning are various runs under different conditions, such as systematically varying variables and parameters. It consists of code, data, and model elements that can be codified into pipeline code or metadata. Still, here, additional focus is on comparing results and visualizing experiment results. Some experiments are suitable within a notebook (such as Jupyter notebook), while other times more precise tracking may be helpful, notably when exploring modeling options and their interactions.
neptune.ai is an excellent example that aids effective experiment tracking in scripts (Python, R, etc.) and notebooks (Jupyter notebook, Google Colab, AWS SageMaker).
- Read more about it here: ML Experiment Tracking: What It Is, Why It Matters, and How to Implement It
- Or just explore an example project to see Neptune in action.


The concept of reproducibility and replicability in machine learning
“Reproducibility” is a central topic in science that helps validate research findings, improve others’ work, and avoid reinventing the wheel. It can be seen as the ability to recreate an experiment with lesser differences to the original experiments and still achieve the same qualitative and quantitative results.
According to the U.S. National Science Foundation (NSF), “Reproducibility refers to the ability of a researcher to duplicate the results of a prior study using the same materials as were used by the original investigator”.
This concept validates results and ensures computational transparency, consistency, confidence, audits, and guide debugging. The inefficiency of this concept is easily observable when replicating results published in machine learning papers. According to Goodman et al[1], there are three types of reproducibility:
- Methods reproducibility: This is the ability to implement, as precisely as possible, the experimental and computational methods with the same data and tools, to obtain the same results as in an original work.
- Results reproducibility: The ability to produce corroborating results in a new and independent study has followed the same experimental procedures.
- Inferential reproducibility: The ability of various researchers to arrive at the same set of inferences after investigating a set of results.
“Replicability”, on the other hand, is the ability to reproduce results by running the same experiment exactly. Replicability requires no non-determinism in the workflow.
Both have their importance in data science as reproducibility steers in finding consistent results across various settings and increases trust, transparency, and confidence in the system. While replicability can guide apt investigation and debug as artifacts can be recreated and understood.
The various aspects of versioning contribute immensely to reproducibility and replicability. This concept also adds value to every continuous integration or continuous delivery cycle (CI/CD) as it aids the smooth activities to flow smoothly. Good programming and versioning practices are imperative for documentation for reproducibility and replicability in machine learning.
Conclusion
We have explored the various concepts related to guide versioning in data science/machine learning, covering strategies of monitoring and tracking changes in the data model, pipeline code, and experiments. Hope this helps you understand what versioning is all about. Thanks for reading!
References
- Goodman, Steven N., Daniele Fanelli, and John PA Ioannidis. “What does research reproducibility mean?” Science translational medicine 8.341 (2016): 341ps12-341ps12
- Technical debt and visibility debt: Sculley, David, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. “Hidden technical debt in machine learning systems”. In Advances in neural information processing systems, pp. 2503–2511. 2015.
- https://www.kdnuggets.com/2019/09/version-control-data-science-tracking-machine-learning-models-datasets.html
