
Deep learning solutions have taken the world by storm, and all kinds of organizations like tech giants, well-grown companies, and startups are now trying to incorporate deep learning (DL) and machine learning (ML) somehow in their current workflow. One of these important solutions that have gained quite a popularity over the past few years is the OCR engine.
OCR (Optical Character Recognition) is a technique of reading textual information directly from digital documents and scanned documents without any human intervention. These documents could be in any format like PDF, PNG, JPEG, TIFF, etc. There are a lot of Advantages of using OCR systems, these are:
- 1 It increases productivity as it takes very less time to process (extract information) the documents.
- 2 It is resource-saving as you just need an OCR program that does the work and no manual work would be required.
- 3 It eliminates the need for manual data entry.
- 4 Chances of error become less.
Extracting information from digital documents is still easy as they have metadata, that can give you the text information. But for the scanned copies, you require a different solution as metadata does not help there. Here comes the need for deep learning that provides solutions for text information extraction from images.
In this article, you will learn about different lessons for building a deep learning-based OCR model so that when you are working on any such use case, you may not face the issues that I have faced during the development and deployment.
What is deep learning-based OCR?
OCR has become very popular nowadays and has been adopted by several industries for faster text data reading from images. While solutions like contour detection, image classification, connected component analysis, etc. are used for documents that have comparable text size and font, ideal lighting conditions, good image quality, etc., such methods are not effective for irregular, heterogeneous text often called wild text or scene text. This text could be from a car’s license plate, house number plate, poorly scanned documents (with no predefined conditions), etc. For this, Deep Learning solutions are used. Using DL for OCR is a three-step process and these steps are:
- Preprocessing: OCR is not an easy problem, at least not as easy as we think it to be. Extracting text data from digital images/documents is still fine. But when it comes to scanned or phone-clicked images things change. Real-world images are not always clicked/scanned in ideal conditions, they can have noise, blur, skewness, etc. That needs to be handled before applying the DL models to them. For this reason, image preprocessing is required to tackle these issues.
- Text Detection/Localization: At this stage models like Mask-RCNN, East Text Detector, YoloV5, SSD, etc. are used that locates the text in images. These models usually create bounding boxes (square/rectangle boxes) over each text identified in the image or a document.
- Text Recognition: Once the text location is identified, each bounding box is sent to the text recognition model which is usually a combination of RNNs, CNNs, and Attention networks. The final output from these models is the text extracted from the documents. Some open-source text recognition models like Tesseract, MMOCR, etc. can help you gain good accuracy.

To explain the effectiveness of OCR models, let’s have a look at a few of the segments where OCR is applied nowadays to increase the productivity and efficiency of the systems:
- OCR in Banking: Automating the customer verification, check deposits, etc. processes using OCR-based text extraction and verification.
- OCR in Insurance: Extracting the text information from a variety of documents in the insurance domain.
- OCR in Healthcare: Processing the documents such as a patient’s history, x-ray report, diagnostics report, etc. can be a tough task that OCR makes easy for you.
These are just a few of the examples where OCR is applied, to know more about its use cases you can refer to the following link.
Lessons from building a deep learning-based OCR model
Now that you are aware of what OCR is and what makes it an important concept in the current times, it’s time to discuss some of the challenges that you may face while working on it. I have been part of several OCR-based projects that were related to the finance (insurance) sector. To name a few:
- I have worked on a KYC verification OCR project where information from different identification documents needed to be extracted and validated against each other to verify a customer profile.
- I have also worked on insurance documents OCR where information from different documents needed to be extracted and used for several other purposes like user profile creation, user verification, etc.
One thing that I have learned while working on these OCR use cases is that you need not fail every time to learn different things. You can learn from others’ mistakes as well. There were several stages where I faced challenges while working in a team for these financial DL-based OCR projects. Let’s discuss those challenges in the form of different stages of ML pipeline development.
Data collection
Problem
This is the first and most important stage while working on any ML or DL use case. Mostly OCR solutions are adopted by financial organizations like banks, insurance companies, brokerage firms, etc. As these organizations have a lot of documents that are hard to process manually. Since they are financial organizations here comes the government rules and regulations that these financial organizations must follow.
For this reason, if you are working on any POC (Proof of Concept) for these financial firms there might be the chance that they might not share a whole lot of data for you to train your text detection and recognition models. Since deep learning solutions are all about data you might get models with poor performance. This is related to of course the regulatory compliance that they might breach users’ privacy that can cause customer financial and other kinds of loss if they share the data.
Solution
Does this problem has any solution? Yes, it has. Let’s say you would want to work on some kind of Form or ID card for text extraction. For forms, you could ask clients for the empty templates and fill them with your random data (time-consuming but efficient) and for the id card, you may find a lot of samples on the internet that you can use to get started. Also, you can just have a few samples of these forms and ID cards and use image augmentation techniques to create new similar images for your model training.

Sometimes when you would want to start working on OCR use cases and do not have any organizational data, you can use one of the datasets available online (open-source) for OCR. You can check the list of best datasets for OCR here.
Labeling the data (data annotation)
Problem
Now that you have your data and also created new samples using image augmentation techniques, the next thing on the list is Data Labeling. Data Labeling is the process of creating bounding boxes on the objects that you would want your object detection model to find in images. In this case, our object is text so you need to create the bounding boxes over the text area that you would want your model to identify. Creating these labels is a very tedious but important task. This is something you can not get rid of.
How to Train Your Own Object Detector Using TensorFlow Object Detection API
Also, bounding boxes are too general when we talk about annotations, for different types of use cases different types of annotations are used. For example, for the use cases where you would want the most accurate coordinates of an object, you can not use square or rectangular bounding boxes, There you need to use Polynomial (multiline) bounding boxes. For Semantic Segmentation use cases where you want to separate an image into different portions, you need to assign a label to every pixel in an image. To know more about different types of annotations you can refer to this link.
Solution
Is there any way through which you can expedite the labeling process for your work? Yes, there is. Usually, if you are using image augmentation techniques like adding noise, blur, brightness, contrast, etc. There is no change in the image geometry so you can use the coordinates from the original image for these augmented images. Also If you are rotating your images, make sure you rotate them in multiple 90 Degree so that you can also rotate your annotations (labels) to the same angle and it would save you a lot of rework. For this task, you can use VGG or VoTT image annotations tools.

Sometimes when you have a lot of data to annotate you can even outsource it, there are a lot of companies that provide annotation solutions. You just need to simply explain the type of annotation you want and the annotation team would do it for you.
Model architecture and training infrastructure
Problem
One thing that you must ensure is the hardware component that you have for training your models. Training object detection models require a decent RAM capacity and a GPU unit (some of them can work with CPU as well but training would be super slow).
Another part of it is over the years different object detection models have been introduced in the field of computer vision. Choosing the one that works best for your use case (text detection and recognition) and also works fine on your GPU/CPU machine can be difficult.
Solution
For the first part, if you have a GPU-based system then there is no need to worry as you can easily train your model. But, if you are using a CPU, training the whole model at once can take a lot of time. In that case, transfer learning can be the way to go as it doesn’t involve training models from scratch.
Each newly introduced computer vision model has either whole new architecture or improves the performance of the existing models. For smaller and dense objects like text, YoloV5 is preferred for text detection over others for its architectural benefits.

If you want to segment an image into multiple portions (pixel-wise), Masked-RCNN is considered best. For text recognition, some of the widely used models are MMOCR, PaddleOCR and CRNN.
Training
Problem
This is a very crucial stage where you would be training your DL-based text detection and recognition models. One thing that we all are aware of is that training deep learning model is a black box thing, you can just try out different parameters to get the best results for your use case and would not know what is going on underneath. You may need to try different deep learning models for text detection and recognition which is pretty hard with all those hyperparameters that you need to take care of for training.
Solution
One thing I have learned here is that you must focus on a single model until you have tried out everything like hyperparameter tuning, model architecture tuning, etc. You need not judge the performance of a model by trying out only a few things.
Furthermore, I would advise you to train your model in parts for eg. if you want to train your model to 50 epochs, divide it into three different steps 15 epochs, 15 epochs, and 20 epochs and evaluate it intermediately. This way you would have results at different stages and would get the gist of whether the model is performing well or badly. It is better than trying all 50 epochs at once for a few days and finally getting to know the model is not working at all on your data.
Also, as already discussed above, transfer learning could be the key. You can train your model from scratch but using an already trained model and fine-tuning it on your data would surely give you good accuracy.
Testing
Problem
Once you have your models ready the next thing in the queue is to test the performance of the model. Testing the deep learning models is quite easy as you can see the results (bounding boxes created on the object) or compare the extracted text with ground truth data, unlike traditional machine learning use cases where you need to interpret the results from numbers.
Nowadays you can use manual DL model testing or could try one of the available automated testing services. The manual process takes some time as you would have to go ahead and check every image on your own to tell the performance of the models. If you are working on financial use cases you might have to work on manual testing only as you can not share the data with online automation testing services.
Solution
One major advice that I would give here is never to test your models on the training datasets as it would not show the real performance of your model. You need to create three different datasets train, validation, and test. First, two would be used for training and run time model assessment while the testing dataset would show you the real performance of the model.
The next thing would be to decide the best metrics to assess the performance of your detection and recognition models. Since text detection is a type of object detection, mAP (mean average precision) is used to assess the performance of the models. It compares the model predicted bounding boxes with the ground truth bounding boxes and returns the score, the higher the score better the performance.
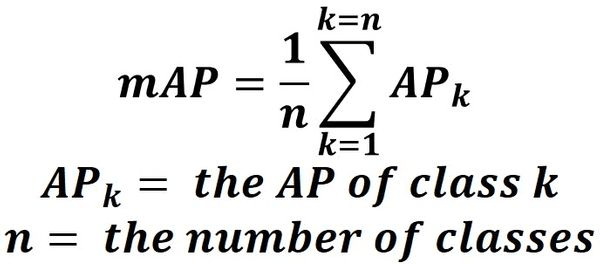
For the text recognition model, the widely used measure is CER (Character Error Rate). For this measure each predicted character is compared with the ground truth to tell the model performance, the lower the CER, the better the model performance. You need your model to have less than 10% CER for it to be replaced with a manual process. To know more about CER and how to calculate it, you can check the following link.
Deployment and monitoring
Problem
Once you have your final models ready with decent accuracy you would have to deploy them somewhere to make them accessible to the target audience. This is one of the major steps where you might face some issues no matter where you are going to deploy it. Three important challenges that I have faced while deploying these models are:
- I was using the PyTorch library to implement the object detection model, this library does not allow you to use multithreading at the time of inference if you have not trained it to be multithreaded at the time of training.
- Model size might be too much as it would be the DL-based model and it might take longer to load at the time of inference.
- Deploying the model is not enough, you need to monitor it for a few months to know if it is performing as expected or if it has further scope for improvement.
A Comprehensive Guide on How to Monitor Your Models in Production
Solution
So to resolve the first issue I would suggest you must be aware that you would have to train the model using the Pytorch with multithreading so that you can have it at the time of inferencing or another solution would be to switch to another framework i.e. look for the TensorFlow alternative for the torch model that you want as it already supports multithreading and is quite easy to work with.
For the second point, if you have a very large model that takes a lot of time to load for inferencing, you can convert your model to the ONNX model, it can reduce the size of the model by ⅓ but with a slight impact on your accuracy.
Model monitoring can be done manually but it requires some engineering resources to look for the cases that are failing with your OCR model. Instead, you can use different ML model monitoring solutions that work in an automated way.
Aside
Here’s an example of how Neptune helped ML team at Brainly optimize monitoring and debugging of their ML processes.
 Neptune gives us really good insight into simple data processing jobs that are not even training. We can, for example, monitor the usage of resources and know whether we are using all cores of the machines. And it’s quick – two lines of code, and we have much better visibility.
Neptune gives us really good insight into simple data processing jobs that are not even training. We can, for example, monitor the usage of resources and know whether we are using all cores of the machines. And it’s quick – two lines of code, and we have much better visibility.Hubert Bryłkowski, Senior ML Engineer at Brainly


-

Read the full case study with Brainly
-
Watch the 2-min product demo
Conclusion
After reading this article, you now know what a Deep Learning based OCR is, its various use cases, and finally seen some lessons based on scenarios I have seen while working on OCR use cases. OCR technology is now taking over the manual data entry and document processing work, this might be the right time to get hands-on with it so that you would not feel left out in the DL world. While working on these types of use cases, you must remember that you can not have a good model in one go. You need to try out different things and learn from every step that you would work on.
Creating a solution from scratch might not be a good solution as you would not have a whole lot of data while working on different use cases, so trying transfer learning and fine-tuning different models on your data can help you achieve good accuracy. The motive of this article was to tell you different issues that I have faced while working on OCR use cases so that you need not face them in your work. Still, there may be some new issues with the change in technology and libraries but you must look for different solutions to get the work done.
