
The first thing you need to do in any NLP project is text preprocessing. Preprocessing input text simply means putting the data into a predictable and analyzable form. It’s a crucial step for building an amazing NLP application.
There are different ways to preprocess text:
- stop word removal,
- tokenization,
- stemming.
Among these, the most important step is tokenization. It’s the process of breaking a stream of textual data into words, terms, sentences, symbols, or some other meaningful elements called tokens. A lot of open-source tools are available to perform the tokenization process.
In this article, we’ll dig further into the importance of tokenization and the different types of it, explore some tools that implement tokenization, and discuss the challenges.
Read also
Best Tools for NLP Projects
The Best NLP/NLU Papers from the ICLR 2020 Conference
Why do we need tokenization?
Tokenization is the first step in any NLP pipeline. It has an important effect on the rest of your pipeline. A tokenizer breaks unstructured data and natural language text into chunks of information that can be considered as discrete elements. The token occurrences in a document can be used directly as a vector representing that document.
This immediately turns an unstructured string (text document) into a numerical data structure suitable for machine learning. They can also be used directly by a computer to trigger useful actions and responses. Or they might be used in a machine learning pipeline as features that trigger more complex decisions or behavior.

Tokenization can separate sentences, words, characters, or subwords. When we split the text into sentences, we call it sentence tokenization. For words, we call it word tokenization.
Example of sentence tokenization

Example of word tokenization

Different tools for tokenization
Although tokenization in Python may be simple, we know that it’s the foundation to develop good models and help us understand the text corpus. This section will list a few tools available for tokenizing text content like NLTK, TextBlob, spacy, Gensim, and Keras.
White Space Tokenization
The simplest way to tokenize text is to use whitespace within a string as the “delimiter” of words. This can be accomplished with Python’s split function, which is available on all string object instances as well as on the string built-in class itself. You can change the separator any way you need.

As you can notice, this built-in Python method already does a good job tokenizing a simple sentence. It’s “mistake” was on the last word, where it included the sentence-ending punctuation with the token “1995.”. We need the tokens to be separated from neighboring punctuation and other significant tokens in a sentence.
In the example below, we’ll perform sentence tokenization using the comma as a separator.

NLTK Word Tokenize
NLTK (Natural Language Toolkit) is an open-source Python library for Natural Language Processing. It has easy-to-use interfaces for over 50 corpora and lexical resources such as WordNet, along with a set of text processing libraries for classification, tokenization, stemming, and tagging.
You can easily tokenize the sentences and words of the text with the tokenize module of NLTK.
First, we’re going to import the relevant functions from the NLTK library:
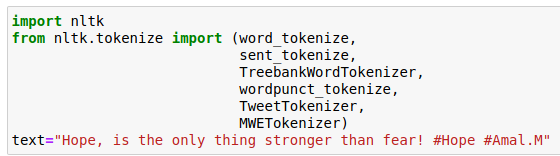
- Word and Sentence tokenizer

N.B: The sent_tokenize uses the pre-trained model from tokenizers/punkt/english.pickle.
- Punctuation-based tokenizer
This tokenizer splits the sentences into words based on whitespaces and punctuations.

We could notice the difference between considering “Amal.M” a word in word_tokenize and split it in the wordpunct_tokenize.
- Treebank Word tokenizer
This tokenizer incorporates a variety of common rules for english word tokenization. It separates phrase-terminating punctuation like (?!.;,) from adjacent tokens and retains decimal numbers as a single token. Besides, it contains rules for English contractions.
For example “don’t” is tokenized as [“do”, “n’t”]. You can find all the rules for the Treebank Tokenizer at this link.

- Tweet tokenizer
When we want to apply tokenization in text data like tweets, the tokenizers mentioned above can’t produce practical tokens. Through this issue, NLTK has a rule based tokenizer special for tweets. We can split emojis into different words if we need them for tasks like sentiment analysis.

- MWET tokenizer
NLTK’s multi-word expression tokenizer (MWETokenizer) provides a function add_mwe() that allows the user to enter multiple word expressions before using the tokenizer on the text. More simply, it can merge multi-word expressions into single tokens.

TextBlob Word Tokenize
TextBlob is a Python library for processing textual data. It provides a consistent API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Let’s start by installing TextBlob and the NLTK corpora:
$pip install -U textblob $python3 -m textblob.download_corpora
In the code below, we perform word tokenization using TextBlob library:
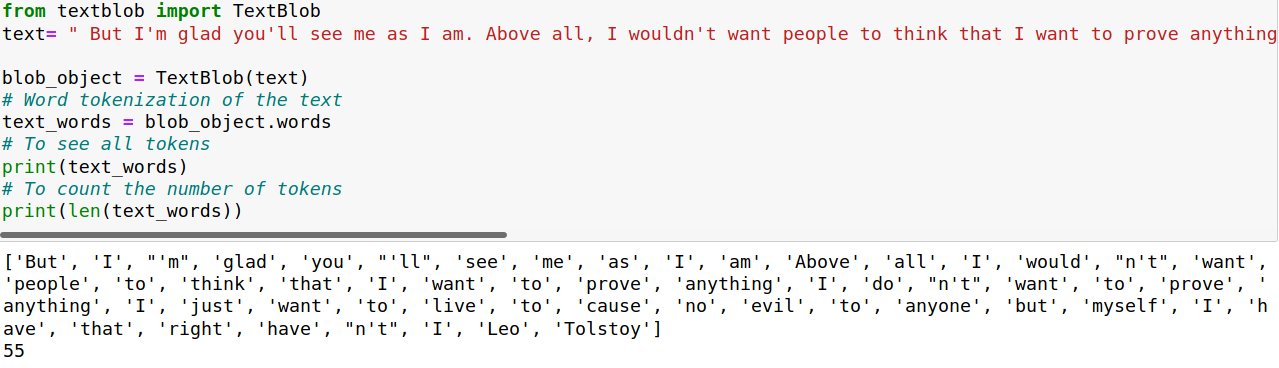
We could notice that the TextBlob tokenizer removes the punctuations. In addition, it has rules for English contractions.
spaCy Tokenizer
SpaCy is an open-source Python library that parses and understands large volumes of text. With available models catering to specific languages (English, French, German, etc.), it handles NLP tasks with the most efficient implementation of common algorithms.
spaCy tokenizer provides the flexibility to specify special tokens that don’t need to be segmented, or need to be segmented using special rules for each language, for example punctuation at the end of a sentence should be split off – whereas “U.K.” should remain one token.
Before you can use spaCy you need to install it, download data and models for the English language.
$ pip install spacy $ python3 -m spacy download en_core_web_sm
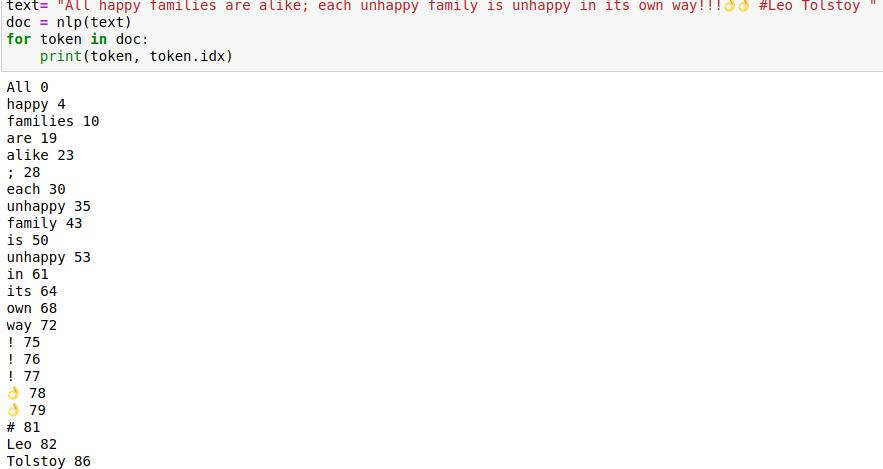
Gensim word tokenizer
Gensim is a Python library for topic modeling, document indexing, and similarity retrieval with large corpora. The target audience is the natural language processing (NLP) and information retrieval (IR) community. It offers utility functions for tokenization.

Tokenization with Keras
Keras open-source library is one of the most reliable deep learning frameworks. To perform tokenization we use: text_to_word_sequence method from the Class Keras.preprocessing.text class. The great thing about Keras is converting the alphabet in a lower case before tokenizing it, which can be quite a time-saver.
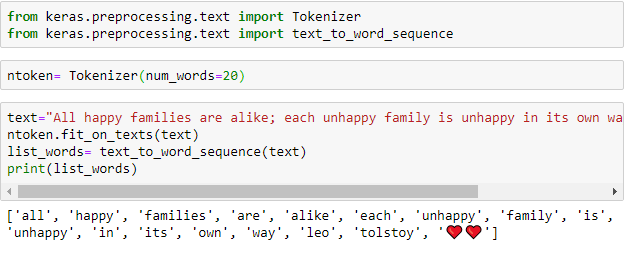
N.B: You could find all the code examples here.
Challenges and limitations
Let’s discuss the challenges and limitations of the tokenization task.
In general, this task is used for text corpus written in English or French where these languages separate words by using white spaces, or punctuation marks to define the boundary of the sentences. Unfortunately, this method couldn’t be applicable for other languages like Chinese, Japanese, Korean Thai, Hindi, Urdu, Tamil, and others. This problem creates the need to develop a common tokenization tool that combines all languages.
Another limitation is in the tokenization of Arabic texts since Arabic has a complicated morphology as a language. For example, a single Arabic word may contain up to six different tokens like the word “عقد” (eaqad).

There’s A LOT of research going on in Natural Language Processing. You need to pick one challenge or a problem and start searching for a solution.
Conclusion
Through this article, we have learned about different tokenizers from various libraries and tools.
We saw the importance of this task in any NLP task or project, and we also implemented it using Python. You probably feel that it’s a simple topic, but once you get into the finer details of each tokenizer model, you will notice that it’s actually quite complex.
Start practicing with the examples above and try them on any text dataset. The more you practice, the better you’ll understand how tokenization works.
If you stayed with me until the end – thank you for reading!
