
In this post, I’ll share with you my library of environments that support training reinforcement learning (RL) agents. The basis for RL research, or even playing with or learning RL, is the environment. It’s where you run your algorithm to evaluate how good it is. We’re going to explore 23 different benchmarks, so I guarantee you’ll find something interesting!
But first, we’ll do a short introduction to what you should be looking for if you’re just starting with RL. Whatever your current level of knowledge, I recommend looking through the whole list. I hope it will motivate you to keep doing good work, and inspire you to start your own project in something different than standard benchmarks!
Rule of thumb
If you’re interested in algorithms specialized in discrete action spaces (PPO, DQN, Rainbow, …), where the action input can be, for example, buttons on the ATARI 2600 game controller, then you should look at the Atari environments in the OpenAI Gym. These include Pong, Breakout, Space Invaders, Seaquest, and more.
On the other hand, if you’re more interested in algorithms specialized in continuous action spaces (DDPG, TD3, SAC, …), where the action input is, say, torque on the joints of a humanoid robot learning to walk, then you should look at the MuJoCo environments in the OpenAI Gym and DeepMind Control Suite. PyBullet Gymperium is an unpaid alternative. Harder environments include Robotics in the OpenAI Gym.
If you don’t know what you’re interested in yet, then I suggest playing around with classic control environments in the OpenAI Gym, and reading SpinningUp in Deep RL.
Enough introduction, let’s check out the benchmarks!
Benchmarks
The first part of this section is just a list, in alphabetical order, of all 23 benchmarks. Further down, I add a bit of description from each benchmark’s creator to show you what it’s for.
List of RL benchmarks
- AI Habitat – Virtual embodiment; Photorealistic & efficient 3D simulator;
- Behaviour Suite – Test core RL capabilities; Fundamental research; Evaluate generalization;
- DeepMind Control Suite – Continuous control; Physics-based simulation; Creating environments;
- DeepMind Lab – 3D navigation; Puzzle-solving;
- DeepMind Memory Task Suite – Require memory; Evaluate generalization;
- DeepMind Psychlab – Require memory; Evaluate generalization;
- Google Research Football – Multi-task; Single-/Multi-agent; Creating environments;
- Meta-World – Meta-RL; Multi-task;
- MineRL – Imitation learning; Offline RL; 3D navigation; Puzzle-solving;
- Multiagent emergence environments – Multi-agent; Creating environments; Emergence behavior;
- OpenAI Gym – Continuous control; Physics-based simulation; Classic video games; RAM state as observations;
- OpenAI Gym Retro – Classic video games; RAM state as observations;
- OpenSpiel – Classic board games; Search and planning; Single-/Multi-agent;
- Procgen Benchmark – Evaluate generalization; Procedurally-generated;
- PyBullet Gymperium – Continuous control; Physics-based simulation; MuJoCo unpaid alternative;
- Real-World Reinforcement Learning – Continuous control; Physics-based simulation; Adversarial examples;
- RLCard – Classic card games; Search and planning; Single-/Multi-agent;
- RL Unplugged – Offline RL; Imitation learning; Datasets for the common benchmarks;
- Screeps – Compete with others; Sandbox; MMO for programmers;
- Serpent.AI – Game Agent Framework – Turn ANY video game into the RL env;
- StarCraft II Learning Environment – Rich action and observation spaces; Multi-agent; Multi-task;
- The Unity Machine Learning Agents Toolkit (ML-Agents) – Create environments; Curriculum learning; Single-/Multi-agent; Imitation learning;
- WordCraft -Test core capabilities; Commonsense knowledge;
A
AI Habitat

The embodiment hypothesis is the idea that “intelligence emerges in the interaction of an agent with an environment and as a result of sensorimotor activity”. Habitat is a simulation platform for research in Embodied AI.
Imagine walking up to a home robot and asking “Hey robot – can you go check if my laptop is on my desk? And if so, bring it to me”. Or asking an egocentric AI assistant (sitting on your smart glasses): “Hey – where did I last see my keys?”. AI Habitat enables training of such embodied AI agents (virtual robots and egocentric assistants) in a highly photorealistic & efficient 3D simulator, before transferring the learned skills to reality.
It’ll be the best fit for you if you study intelligent systems with a physical or virtual embodiment.
B
Behaviour Suite
bsuite is a collection of carefully designed experiments that investigate the core capabilities of a reinforcement learning (RL) agent with two main objectives.
- To collect clear, informative, and scalable problems that capture key issues in the design of efficient and general learning algorithms.
- To study agent behavior through their performance on these shared benchmarks.
This library automates the evaluation and analysis of any agent on these benchmarks. It serves to facilitate reproducible, and accessible, research on the core issues in RL, and ultimately the design of superior learning algorithms.
D
DeepMind Control Suite

The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures to create your own tasks.
Moreover, the Control Suite is a fixed set of tasks with a standardized structure, intended to serve as performance benchmarks. It includes classic tasks like HalfCheetah, Humanoid, Hopper, Walker, Graber, and more (see the picture). The Locomotion framework provides high-level abstractions and examples of locomotion tasks like soccer. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included.
An introductory tutorial for this package is available as a Colaboratory notebook.
DeepMind Lab

DeepMind Lab is a 3D learning environment based on Quake III Arena via ioquake3 and other open-source software. DeepMind Lab provides a suite of challenging 3D navigation and puzzle-solving tasks for learning agents. Its primary purpose is to act as a testbed for research in artificial intelligence, where agents have to act on visual observations.
DeepMind Memory Task Suite
The DeepMind Memory Task Suite is a set of 13 diverse machine-learning tasks that require memory to solve. They are constructed to let us evaluate generalization performance on a memory-specific holdout set.
DeepMind Psychlab

Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab. Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As an example, the Psychlab includes several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking.
G
Google Research Football

Google Research Football is a novel RL environment where agents aim to master the world’s most popular sport – football! Modeled after popular football video games, the Football Environment provides an efficient physics-based 3D football simulation where agents control either one or all football players on their team, learn how to pass between them, and manage to overcome their opponent’s defense in order to score goals. The Football Environment provides a demanding set of research problems called Football Benchmarks, as well as the Football Academy, a set of progressively harder RL scenarios.
It’s perfect for multi-agent and multi-task research. It also allows you to create your own academy scenarios as well as completely new tasks using the simulator, based on the included examples.
M
Meta-World
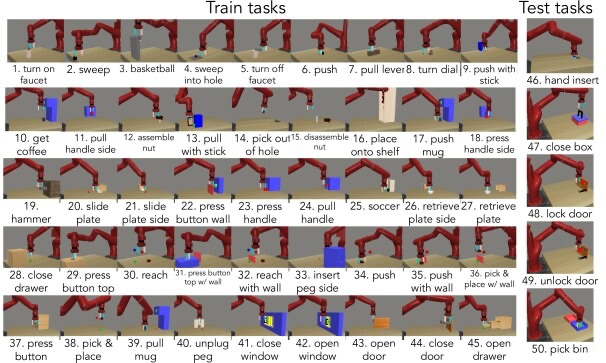
Meta-reinforcement learning algorithms can enable robots to acquire new skills much more quickly, by leveraging prior experience to learn how to learn. Meta-World is an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks. The authors aim to provide task distributions that are sufficiently broad to evaluate meta-RL algorithms’ generalization ability to new behaviors.
MineRL

MineRL is a research project started at Carnegie Mellon University aimed at developing various aspects of artificial intelligence within Minecraft. In short, MineRL consists of two major components:
- MineRL-v0 Dataset – One of the largest imitation learning datasets with over 60 million frames of recorded human player data. The dataset includes a set of environments that highlight many of the hardest problems in modern-day Reinforcement Learning: sparse rewards and hierarchical policies.
- minerl – A rich python3 package for doing artificial intelligence research in Minecraft. This includes two major submodules: minerl.env – A growing set of OpenAI Gym environments in Minecraft and minerl.data – The main python module for experimenting with the MineRL-v0 dataset.
Multiagent emergence environments

Environment generation code for Emergent Tool Use From Multi-Agent Autocurricula. It’s a fun paper, I highly recommend you read it. The authors observed agents discovering progressively more complex tool use while playing a simple game of hide-and-seek. Through training in the simulated hide-and-seek environment, agents build a series of six distinct strategies and counterstrategies. The self-supervised emergent complexity in this simple environment further suggests that multi-agent co-adaptation may one day produce extremely complex and intelligent behavior.
It uses “Worldgen: Randomized MuJoCo environments” which allows users to generate complex, heavily randomized environments. You should try it too, if you’re into creating your own environments!
O
OpenAI Gym

Gym, besides being the most widly known benchmark, is an amazing toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking the simulated humanoid (requires MuJoCo, see PyBullet Gymperium for the free alternative) to playing Atari games like Pong or Pinball. I personally use it in my research the most. It’s very easy to use and it’s kind of standard nowadays. You should get to know it well.
OpenAI Gym Retro
Gym Retro can be thought of as the extension of the OpenAI Gym. It lets you turn classic video games into OpenAI Gym environments for reinforcement learning and comes with integrations for ~1000 games. It uses various emulators that support the Libretro API, making it fairly easy to add new emulators.
OpenSpiel
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. Games are represented as procedural extensive-form games, with some natural extensions. The core API and games are implemented in C++ for efficiency and exposed to Python for your ease of use.
P
Procgen Benchmark

Procgen Benchmark consists of 16 unique environments designed to measure both sample efficiency and generalization in reinforcement learning. This benchmark is ideal for evaluating generalization since distinct training and test sets can be generated in each environment. This benchmark is also well-suited to evaluate sample efficiency since all environments pose diverse and compelling challenges for RL agents. The environments’ intrinsic diversity demands that agents learn robust policies; overfitting to narrow regions in state space will not suffice. Put differently, the ability to generalize becomes an integral component of success when agents are faced with ever-changing levels.
PyBullet Gymperium
PyBullet Gymperium is an open-source implementation of the OpenAI Gym MuJoCo environments and more. These are challenging continuous control environments like training a humanoid to walk. What’s cool about it, is that it doesn’t require the user to install MuJoCo, a commercial physics engine that requires a paid license to run for longer than 30 days.
R
Real-World Reinforcement Learning

The Challenges of Real-World RL paper identifies and describes a set of nine challenges that are currently preventing Reinforcement Learning (RL) agents from being utilized on real-world applications and products. It also describes an evaluation framework and a set of environments that can provide an evaluation of an RL algorithm’s potential applicability to real-world systems. It has since then been followed up with the An Empirical Investigation of the challenges of real-world reinforcement learning paper which implements eight of the nine described challenges and analyses their effects on various state-of-the-art RL algorithms.
This is the codebase used to perform this analysis and is also intended as a common platform for easily reproducible experimentation around these challenges. It is referred to as the realworldrl-suite (Real-World Reinforcement Learning (RWRL) Suite).
RLCard
RLCard is a toolkit for Reinforcement Learning (RL) in card games. It supports multiple card environments with easy-to-use interfaces. Games include Blackjack, UNO, Limit Texas Hold’em, and more! It also lets you create your own environments. The goal of RLCard is to bridge reinforcement learning and imperfect information games.
RL Unplugged
RL Unplugged is a suite of benchmarks for offline reinforcement learning. The RL Unplugged is designed to facilitate ease of use, it provides the datasets with a unified API which makes it easy for the practitioner to work with all data in the suite once a general pipeline has been established. It includes datasets for the most common benchmarks: Atari, DeepMind Locomotion, DeepMind Control Suite, Realworld RL, DeepMind Lab, and bsuite.
S
Screeps

Screeps is a massive, multiplayer, online, real-time, strategy game (phwee, it’s a lot). Each player can create their own colony in a single persistent world shared by all the players. Such a colony can mine resources, build units, conquer territory. As you conquer more territory, your influence in the game world grows, as well as your abilities to expand your footprint. However, it requires a lot of effort on your part, since multiple players may aim at the same territory. And what’s the most important, you build an AI that does all of it!
Screeps is developed for people with programming skills. Unlike some other RTS games, your units in Screeps can react to events without your participation – provided that you have programmed them properly.
Serpent.AI – Game Agent Framework

Serpent.AI is a simple yet powerful, novel framework to assist developers in the creation of game agents. Turn ANY video game you own into a sandbox environment ripe for experimentation, all with familiar Python code. For example, see this autonomous driving agent in GTA. The framework first and foremost provides a valuable tool for Machine Learning & AI research. It also turns out to be ridiculously fun to use as a hobbyist (and dangerously addictive)!
StarCraft II Learning Environment
PySC2 provides an interface for RL agents to interact with StarCraft 2, getting observations and sending actions. It exposes Blizzard Entertainment’s StarCraft II Machine Learning API as a Python RL Environment. This is a collaboration between DeepMind and Blizzard to develop StarCraft II into a rich environment for RL research. PySC2 has many pre-configured mini-game maps for benchmarking the RL agents.
T
The Unity Machine Learning Agents Toolkit (ML-Agents)

It’s an open-source project that enables games and simulations to serve as environments for training intelligent agents. Unity provides implementations (based on PyTorch) of state-of-the-art algorithms to enable game developers and hobbyists to easily train intelligent agents for 2D, 3D, and VR/AR games. Researchers, however, can use the provided simple-to-use Python API to train Agents using reinforcement learning, imitation learning, neuroevolution, or any other methods! See for example Marathon Environments.
W
WordCraft

This is the official Python implementation of WordCraft: An Environment for Benchmarking Commonsense Agents. The ability to quickly solve a wide range of real-world tasks requires a commonsense understanding of the world. To better enable research on agents making use of commonsense knowledge you should try WordCraft, an RL environment based on Little Alchemy 2. Little Alchemy 2 is a fun and addictive game which allows players to combine elements to create even more elements. This lightweight environment is fast to run and built upon entities and relations inspired by real-world semantics.
Conclusion
This concludes our list of RL benchmarks. I can’t really tell you which one you should pick. For some, the more classic benchmarks like OpenAI Gym or DM Control Suite described in the “Rule of thumb” section will be the best fit. For others, it will be not enough and they might want to jump into something less tired like the Unity ML-agents or Screeps.
Personally, I worked with GRF on one occasion and it was fun to see how my agents learn to play football and score goals. At the moment, I work on some more fundamental research and I test my agents using the well-recognized OpenAI Gym MuJoCo environments, which is fun in other ways like seeing that my method really works.
Whatever is your choice, I hope this list helps you make your RL research more exciting!
