
Data versioning control is an important concept in machine learning, as it allows for the tracking and management of changes to data over time. As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
In this article, we will discuss the importance of data versioning control in machine learning and explore various methods and tools for implementing it with different types of data sources.
What is data versioning in machine learning?
In machine learning, data is the foundation upon which models are built and trained. As such, it is crucial to have a system in place for tracking and managing changes to data over time. This is where data versioning comes in.
Data version control in machine learning vs conventional software engineering
Data version control in machine learning and conventional software engineering have some similarities, but there are also some key differences to consider.
In both cases, the main goal of the data version control system is to track and manage changes to data over time. This allows for the ability to revert to previous versions if necessary, as well as to understand the history of changes made.
However, there are some key differences that we need to consider:
Size and complexity of the data
In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. But, it is not rare that data engineers and database administrators process, control, and store terabytes of data in projects that are not related to machine learning.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and data scientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors. Data from different formats, databases, and sources are combined together for modeling. Data scientists often apply different data imputation and transformation techniques to create data sets with features. Sometimes even meta-learning models are used to produce meta-features.
Multiple tools and technologies
Machine learning often includes the use of many different tools and technologies. These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system.
For instance, our data lake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. Data scientists may also have separate files for features or feature stores and use various tools for model versioning and experiment tracking.
Given the range of tools and data types, a separate data versioning logic will be necessary. Different team roles may also be responsible for versioning data at different stages. For instance, data engineers and database administrators may handle versioning raw data in data lakes, while data scientists may be in charge of versioning files with features and data related to experiment tracking.

Why is data versioning important in machine learning?
There are several reasons why data versioning is important in machine learning:
- Data is constantly evolving – In machine learning, data is often collected and modified over long periods of time. By using a data versioning system, it is possible to track the history of changes made to the data and easily revert to a previous version if needed.
- Reproducibility – Data versioning is essential for reproducing results from previous experiments. Without a clear record of the data used, it may be difficult or impossible to recreate the same results.
- Collaboration – In a team environment, multiple people may be working with the same data at the same time. Data versioning allows team members to see the changes made by others and ensures that everyone is working with the most up-to-date version of the data.
- Auditability – For regulatory compliance, it may be necessary to demonstrate the source of data. Data versioning allows for the traceability of data and helps to detect tampering, ensuring the integrity of the data.
What are the key criteria for selecting a data version control tool?
To identify a data versioning tool that is appropriate for our workflow, we should consider:
- Ease of use – How simple is it to use the tool in a workflow? Does it require a lot of time to integrate into a project?
- Data support – Does it support all data types that a project requires?
- Collaboration options – Is there an option where multiple team members can share and access the data?
- Diverse integration – Does it have integration with popular MLOps tools? How does it fit with the current infrastructure, stack, or model training workflow?
Below, we will describe some of the data version control tools that are worth exploring.
TL;DR
If you want to take a quick look at which tool provides what feature, here’s a table to refer to.
|
|
DVC
|
Git LFS
|
neptune.ai
|
Dolt
|
LakeFS
|
Delta Lake
|
Pachyderm
|
|
Git-like versioning |
|
|
|
|
|
|
|
|
Database tool |
|
|
|
|
|
|
|
|
Data lake |
|
|
|
|
|
|
|
|
Data pipelines |
|
|
|
|
|
|
|
|
Experiment tracking |
|
|
|
|
|
|
|
|
Integration with cloud platforms |
|
|
|
|
|
|
|
|
Integrations with ML tools |
|
|
|
|
|
|
|
Examples of data version control tools in ML
DVC
Data Version Control DVC is a version control system for data and machine learning teams. It is a free, open-source command line tool that doesn’t require databases, servers, or any special services. It helps to track and manage the data and models used in machine learning projects and allows for the ability to reproduce results.
With DVC, we can track the versions of our data and models using Git commits and store them on-premises or in cloud storage. DVC also enables us to easily switch between different versions of data.

DVC is meant to be used with Git. In fact, the Git and DVC commands are often used in sequence, one after the other. Git is used for storing and versioning code, and DVC does the same for data and model files. While Git can store code locally and also on a hosting service like GitHub, GitLab, and Bitbucket, DVC uses a remote repository to store all data and models. The remote repository can be on the same computer, or it can be on the cloud. It supports most major cloud providers, such as AWS, GCP, and Azure.
Data versioning with DVC is very simple and straightforward. For example, the first thing that we need to do is to initialize Git and DVC in our directory:
git init
dvc init
Next, we add a data file to DVC tracking using the command:
dvc add data/data.csv
After that, DVC will instruct us to add new two files that have been generated after the last command:
git add data/.gitignore data/data.csv.dvc
Then we commit these two files with Git:
git commit -m "add raw data"When we store data in the remote repository, a .dvc file is created. It is a small text file with md5 hash that points to the actual data file in remote storage. Also, this file is meant to be stored with code in GitHub. When we download a Git repository, we also get the .dvc files which we use to download the data associated with them.
To add remote storage, we use commands:
dvc remote add -d storage gdrive://google_drive_id
git commit .dvc/config -m "Configure remote storage"And lastly, we need to push the data with:
dvc push
If we updated our data set, we need to again add, commit and push changes:
dvc add data/data.xml
git add data/data.xml.dvc
git commit -m "Dataset update"
dvc push
After this, one more file will be added to our remote storage. Now, if we want to revert back to the previous version of the file, we can list all commits using the Git command:
git log --oneline
It will list all commit hashes with commit messages. Using checkout command, we can revert back to any commit version that we want:
git checkout b11343a
dvc checkout
As we can see, DVC is very similar to Git, and using DVC, we can do data versioning with any file that we want. More useful resources about DVC:
- Versioning data and models
- Data version control with Python and DVC
- DVCorg YouTube
- DVC data version control cheatsheet
At this point, one question arises; why use DVC instead of Git?
There are a few reasons why Git alone is not the best tool for data versioning:
- 1 Git is designed for versioning text files and is not optimized for handling large files. This can make it inefficient for versioning large datasets or models.
- 2 Git stores all file versions in the repository, which can cause it to become very large over time. This can make it impractical for versioning large datasets or models.
- 3 Git does not provide features specifically designed for data versioning, such as data lineage tracking or support for switching between different versions of data.
Despite that, there is an extension to Git, called Git LFS, that is designed to handle large binary files more efficiently.
Check also
Git LFS
Git-LFS (Git Large File Storage) replaces large files with text pointers inside Git, while storing the file contents on a remote server like GitHub.com or GitHub Enterprise. With Git LFS is possible to version large files using the same Git workflow.
Originally, this tool was developed by game developers to manage large binary files, such as game assets, in Git repositories more efficiently. Git LFS was later adopted by machine learning and research professionals, who also have large files, such as models and data, in order to keep them connected with the code they relate to.

It is important to mention that there is a file storage limit. For example, on GitHub.com, it is a 2GB for free or 5GB for enterprise cloud option. In opposite to DVC, this tool is not intentionally created for a machine learning project, does not provide data lineage tracking, and is not an MLOps tool.
Git LFS might be a little bit complicated to set up, but once it’s done, we use it as we normally use Git. The only thing that we need to do is to specify what file types we want to track. For example, if we want to track .tsv files, we use the command:
git lfs track "*.tsv"
Only file types that are tracked in this way are stored in Git LFS rather than the standard Git storage.
More about Git LFS can be found here:
- Git file large storage
- Why is DVC better than Git and Git-LFS in machine learning reproducibility
- Using Git Large File Storage (LFS) for data repositories
- Configuring Git LFS for your enterprise
neptune.ai
neptune.ai is an experiment tracking and model registry tool built for ML teams that work with many experiments. It provides options for tracking, organizing, and storing metadata from machine learning experiments. Besides that, with Neptune, it is possible to visualize and compare results as well as do model and data versioning.
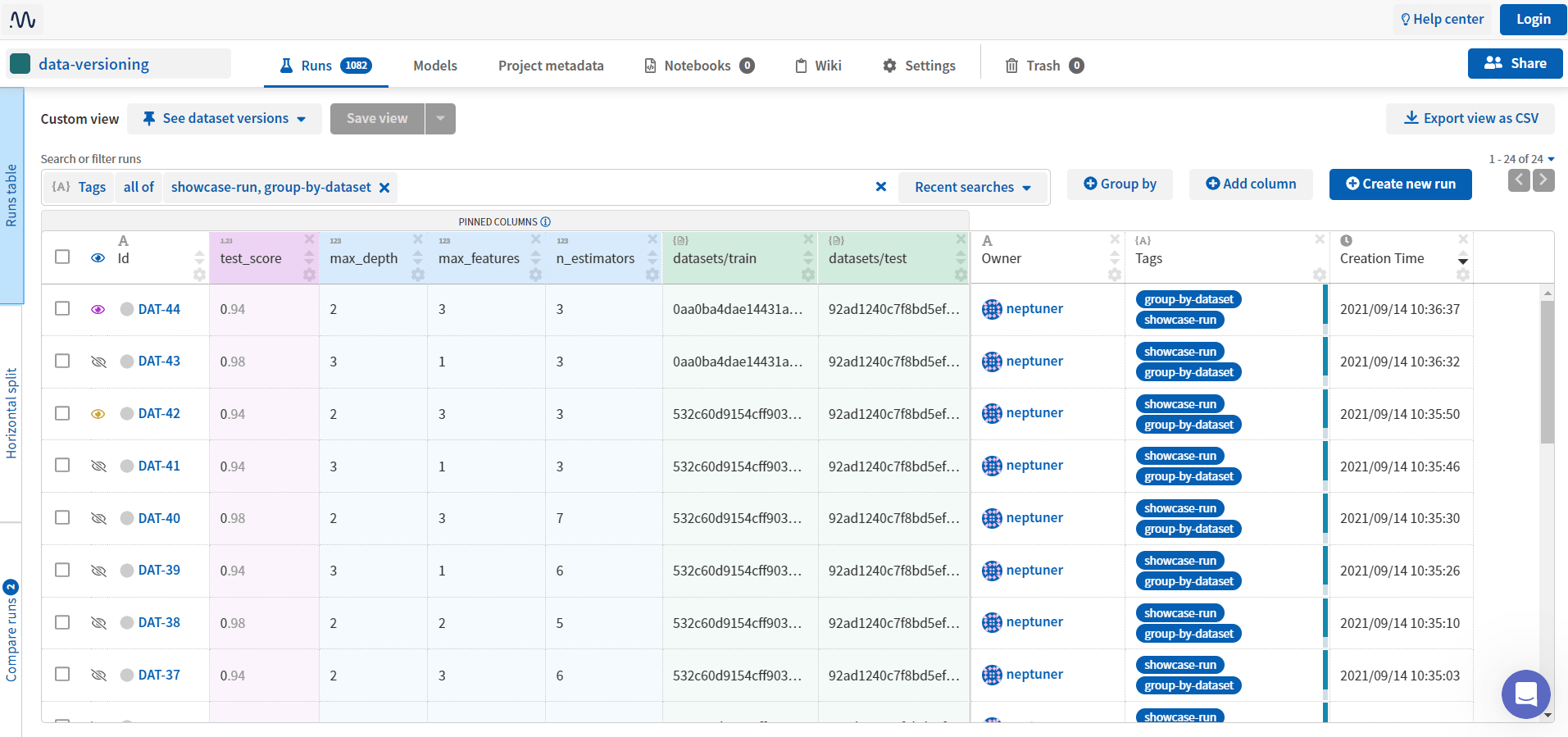
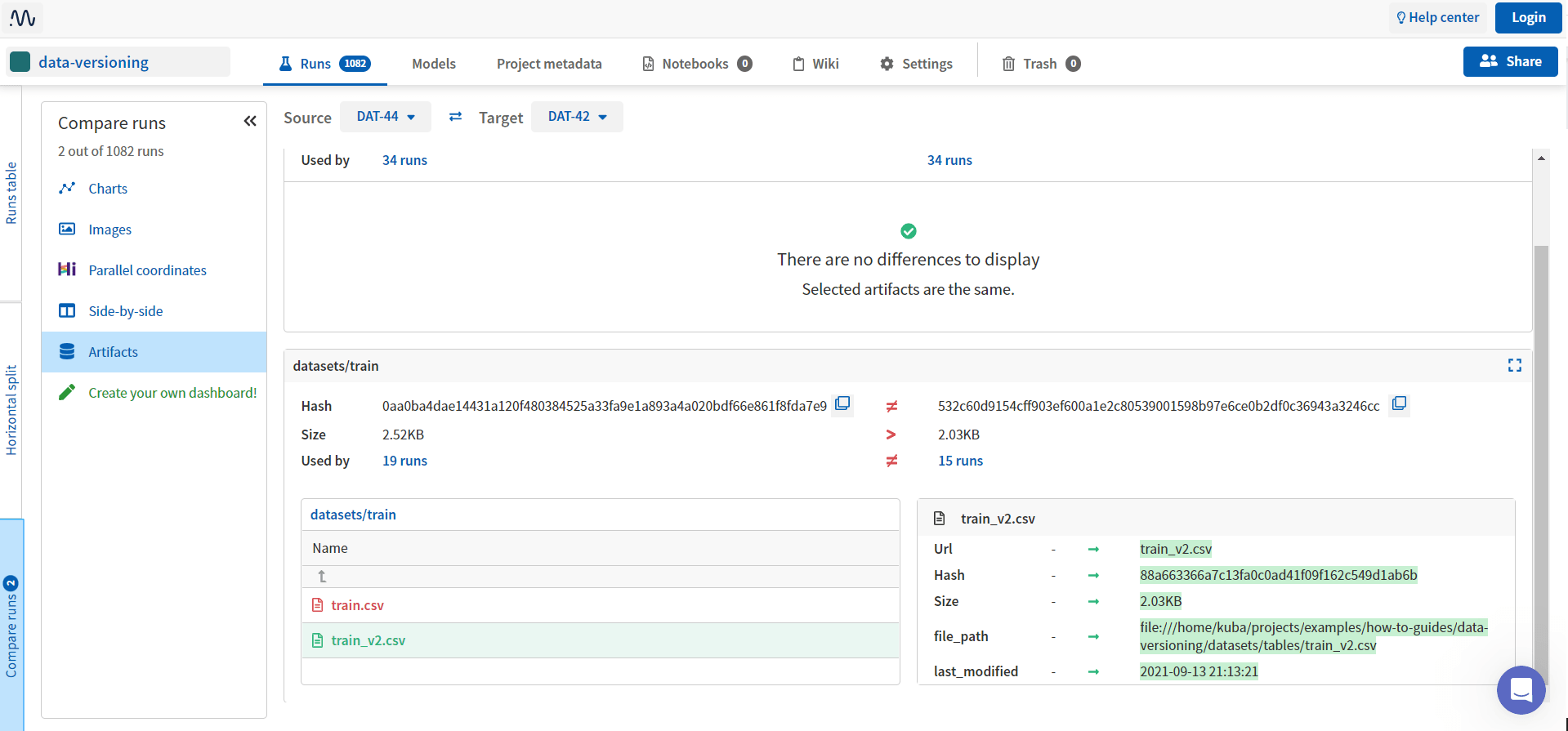
With Neptune artifacts, it is possible to version datasets, models, and any files from the local directory or any S3-compatible storage. Basically, it creates an MD5 hash which depends on the file contents and metadata like path, size, and last modification time. A change to any of these will result in a different hash.
In addition to the hash, it is possible to version a data file using:
- Location and name of the file or folder
- Size of the file in KBs
- Data of the last modification
Once the metadata is logged, it is simple to select specific runs of the experiment and compare how the artifacts changed.
Artifact tracking in Neptune can be implemented with a few lines of code. For example, if we want to track a file, we need to import neptune package, initialize run, and call the “track_files” method:
import neptune
run = neptune.init_run()
run["train/dataset"].track_files("./datasets/train.csv")
or if we need to track a folder:
run["train/images"].track_files("./datasets/images")
In order to store artifacts from Amazon S3, we need to configure an IAM policy with “S3ReadAccessOnly” permissions and store our credentials for AWS as environment variables. To do that, we use “export” command on Linux/macOS or “set” on Windows:
export AWS_SECRET_ACCESS_KEY='Your_AWS_key_here'
export AWS_ACCESS_KEY_ID='Your_AWS_ID_here'
To fetch metadata from the artifact, we use the “fetch_files_list” method:
artifact_list = run["train/images"].fetch_files_list()
It returns an ArtifactFileData object with the following properties:
- file_hash: Hash of the file.
- file_path: Path of the file, relative to the root of the virtual artifact directory.
- size: Size of the file, in kilobytes.
- metadata: Dictionary with the keys:
- file_path: URL of the file (absolute path in local or S3-compatible storage).
- last_modified: When the file was last modified.
In summary, Neptune is a simple and fast option for data versioning but it may not provide all data versioning features like DVC.
More about Neptune:
- Working with artifacts: versioning datasets in runs
- How to version datasets or models stored in the S3 compatible storage
Dolt
Dolt is a SQL database that is created for versioning and sharing data. It has Git semantics, including features for cloning, branching, merging, pushing, and pulling. Dolt also provides tools for querying and analyzing data, as well as for importing and exporting data from other sources.
In contrast to DVC and Neptune, Dolt is a database management system intended for versioning and sharing data stored in tables. It means that we cannot directly version CSV files or any unstructured data like images. Instead of that, there is an option for importing several different file formats.
More precisely, we can load the following formats into Dolt:
- CSV, JSON, Parquet
- MySQL databases
- Postgres
- Spreadsheets
For example, to dump a MySQL database “test” and load it into Dolt, the commands look like:
mysqldump --databases test -P 3306 -h 0.0.0.0 -u root -p > dump.sql
dolt sql < dump.sql
Or we can load a postgres database into dolt using commands:
./pg2mysql.pl < file.pgdump > mysql.sql
dolt sql < mysql.sql
where pg2mysql is their custom tool.
For version control, Dolt has multiple branches and stores all data in a commit graph, like Git. It allows working with different branches, merge them and resolving conflicts, query history and many more.
For instance, after importing a database, to make initial commit, we use a command:
call dolt_commit('-m', 'Created initial schema')
As with Git, to make changes on a new branch, we use checkout as:
call dolt_checkout('-b','modifications');
insert INTO employees (id, first_name, last_name) values (4,'Daylon', 'Wilkins');
call dolt_commit('-am', 'Modifications on a branch')
In addition to that, Dolt provides a cloud-hosted database server with built-in backups and monitoring. The pricing for that product varies based on the instance’s CPU, RAM, network speed, and disk space.
More about Dolt:
lakeFS
LakeFS is an open source data version control and management platform for data lakes. With lakeFS it is possible to test ETLs on top of production data, in isolation, without copying anything. Also, lakeFS can be used for data management, ETL testing, reproducibility for experiments, and CI/CD for data to prevent future failures. LakeFS is fully compatible with many ecosystems of data engineering tools such as AWS, Azure, Spark, Databrick, MlFlow, Hadoop and others.
For instance, with lakeFS it is possible to create a repository on an S3 bucket with a default branch. Then, using a separate branch, we can import files into the repository. If the files are already on S3, importing doesn’t copy the files but range and metarange of the location of these files. Analogously, we can merge the new branch into the main production branch and use other Git features such as branching, merging, diffing, and similar.

Regarding deployment, lakeFS is a stateless data versioning platform with a shared nothing architecture that can be deployed on multiple instances behind a load balancer using K8s with a helm chart. Alternatively, it can be used as a hosted cloud service where users consume lakeFS as a service and the data sits on top of the user’s buckets.
More about LakeFS:
Delta Lake
Delta lake is an open-source storage layer that is designed for working with data lakes. It allows data versioning, ACID transactions, and schema management on top of existing data lakes such as Amazon S3, Azure Data Lake Storage, Google Cloud Storage, and HDFS. Delta lake brings reliability to data lakes by building Lakehouse architecture on top of them. This makes it easier to build robust data pipelines and do more complex data analytics.
Regarding data versioning, Delta lake has an option called “Time travel”. It enables rollbacks, full historical audit trails, and reproducible machine learning experiments. With time travel it is possible to query an older snapshot of a Delta table and it helps in recreating analyses and reports, fixing mistakes in data, and providing snapshot isolation for a set of queries for fast-changing tables. For example, to query an older snapshot, we can use a SQL syntax:
SELECT * FROM table_name TIMESTAMP AS OF timestamp_expression
where timestamp_expression can be:
- ‘2023-01-30’ (date string)
- current_timestamp() – interval 12 hours
- Any other expression that is or can be cast to a timestamp
In summary, Data lake allows building a Lakehouse architecture, which is an architecture that combines the best elements of data lakes and data warehouses, and it has an option for data versioning.
More about Delta lake:
Pachyderm
Pachyderm is an open-source platform for data science and machine learning that enables data scientists and engineers to easily develop, version, and deploy their data pipelines. It provides a scalable and secure way to manage, version, and analyze large data sets, and is built on top of technologies such as Docker and Kubernetes. Also, this platform is code and infrastructure agnostic. It means that with Pachyderm we can use any language, library, integrate it with standard data processing and machine learning tools or major cloud providers.

Pachyderm has a built-in version control feature in its data-driven pipelines. The software allows users to define the smallest unit of data, called a “datum”, which is then used to process data with machine learning models. This allows Pachyderm to track changes to each datum over time with a global ID. This version control and ID tracking is used to scale data processing and trigger data pipelines only when there is new or different data to process, making it more efficient than other pipeline tools that only see the dataset as a whole.
More about Pachyderm:
Learn more
Conclusion
In this article, we described some of the data versioning tools and how to do data versioning with them. They can be used to do data versioning with various data sources. For example:
- To version data sets and models in an experiment tracking environment, we can use Neptune.
- To version any type of data file with Git-like architecture, we can use DVC or Git LFS.
- To version data sets stored in tables, Dolt might be useful.
- For data lakes or data lakehouses we described lakeFS and Delta Lake.
- Pachyderm is a tool that can be used to optimize data pipelines and manage data version control.
References
- https://neptune.ai/blog/best-data-version-control-tools
- https://www.aporia.com/blog/best-data-version-tools-for-mlops-2021/
- https://www.fuzzylabs.ai/guides/data-version-control
- https://realpython.com/python-data-version-control/
- https://derekchia.com/dvc/
- https://censius.ai/blogs/dvc-vs-git-and-git-lfs-in-machine-learning-reproducibility
- https://developer.lsst.io/v/DM-5063/tools/git_lfs.html#
- https://docs.dolthub.com/introduction/what-is-dolt
- https://towardsdatascience.com/data-versioning-all-you-need-to-know-7077aa5ed6d1
- https://docs.delta.io/latest/delta-batch.html#-deltatimetravel
- https://www.databricks.com/glossary/data-lakehouse
- https://www.pachyderm.com/glossary/what-is-data-versioning/
- https://dbmstools.com/categories/version-control-tools/mysql
- https://www.mongodb.com/blog/post/building-with-patterns-the-document-versioning-pattern
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/Versioning.html
